C语言编写管道代码
什么是管道:
管道是Unix中最古老的进程间通信的形式。
我们把从一个进程链接到另外一个进程的一个数据流称为管道。
本质是有固定大小的内核缓存区。
管道的限制
管道是半双工的,数据只能向一个方向流动,需要双方通信时,需要建立起两个管道
只能用于具有共同祖先的进程(具有亲缘关系的进程)之间进行通信,通常,一个管道由一个进程创建,然后该进程调用fork,此后父、子进程之间就可以用管道。
匿名管道pipe
包含头文件
功能:创建一无名管道
原型:
int pipe(int fd[2]);
参数
fd:文件描述符数组,其中fd[0]表示读端,fd[1]表示写端。
返回值:成功返回0,失败返回错误代码。
国际惯例:上个代码
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define ERR_EXIT(m) \
do \
{ \
perror(m); \
exit(EXIT_FAILURE); \
}while(0)
int main()
{
int pipefd[2];
if(pipe(pipefd) == -1)
{
ERR_EXIT("pipe error");
}
pid_t pid;
pid = fork();
if(pid == 0)
{
close(pipefd[0]);
write(pipefd[1],"hello",5);
close(pipefd[1]);
exit(EXIT_SUCCESS);
}
close(pipefd[1]);
char buf[10] = {0};
read(pipefd[0],buf,10);
printf("buf = %s\n",buf);
return 0;
} 解释一波:
本次实验是子进程写一个字符串,父进程打印出来。
从主函数开始解释:
int pipefd[2];
if(pipe(pipefd) == -1)
{
ERR_EXIT("pipe error");
}
第一行代码是先创建一个数组,为的就是pipe的参数。if(pipe(pipefd)==-1)这行代码的意思就是创建一个管道,如果失败的打印错误信息。
pid_t pid;
pid = fork();
if(pid == 0)
{
close(pipefd[0]);
write(pipefd[1],"hello",5);
close(pipefd[1]);
exit(EXIT_SUCCESS);
}
解释这些代码
这些代码的意思是,创建一个进程(第一行和第二行),第三行代码的意思是进入子进程,pid返回0表示在子进程中,返回大于0表示在父进程中。
再看子进程的代码:
close(pipefd[0]);这行代码的意思是,关闭读端。因为子进程是要写字符串在管道中,所以读端就没什么用了。关闭了。
write(pipefd[1],"hello",5);这行代码的意思就是向管道中写hello这个字符串。
第四行close(pipefd[1]);这行代码就是关闭写端。
再来就是子进程退出。
close(pipefd[1]);
char buf[10] = {0};
read(pipefd[0],buf,10);
printf("buf = %s\n",buf);
return 0;再看这几行代码:
这几行代码是父进程的代码,一天因为子进程执行完就退出了。所以不会执行到这里的。
第一行代码是关闭写端。因为父进程是读子进程传来的消息,所以写端没什么用,关闭。
第二行代码是定义一个字符串,用来存放读取到的字符串。
第三行代码就是读取管道的信息。
第四行就是打印。
注:试着让子进程睡眠10s,想让父进程先执行完看看是什么效果,但是我失望了,还是这样的。就是白等了10s;
看结果:

这是为啥那?
强行解释一波,下面代码是父子进程共用的代码,并不是父进程自己的代码,所以当子进程执行完才会执行的代码。(实际上是当没有数据可读时:O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止。)
在看一段代码:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define ERR_EXIT(m) \
do \
{ \
perror(m); \
exit(EXIT_FAILURE); \
}while(0)
int main()
{
int pipefd[2];
if(pipe(pipefd) == -1)
{
ERR_EXIT("pipe error");
}
pid_t pid;
pid = fork();
if(pid == 0)
{
dup2(pipefd[1],STDOUT_FILENO);
close(pipefd[1]);
close(pipefd[0]);
execlp("ls","ls",NULL);
fprintf(stderr,"error execor execte ls\n");
exit(EXIT_FAILURE);
}
dup2(pipefd[0],STDIN_FILENO);
close(pipefd[0]);
close(pipefd[1]);
execlp("wc","wc","-w",NULL);
fprintf(stderr,"error execute wc\n");
return 0;
}
这行代码的执行效果和 ls | wc -w
的执行效果是一样的。
看结果:


·重复部分不做解释,只简单说明一下:
if(pid == 0)
{
dup2(pipefd[1],STDOUT_FILENO);
close(pipefd[1]);
close(pipefd[0]);
execlp("ls","ls",NULL);
fprintf(stderr,"error execor execte ls\n");
exit(EXIT_FAILURE);
}
这段代码的意思是:
dup2(pipefd[1],STDOUT_FILENO);这行代码的意思是,把文件输出描述符定义到写端。
close(pipefd[1]);
close(pipefd[0]);
当重定向完以后就可以关闭通道了。
execlp("ls","ls",NULL);
fprintf(stderr,"error execor execte ls\n");
这两行代码是执行ls命令,因为已经输出重定向了,进管道了。
到了父进程
dup2(pipefd[0],STDIN_FILENO);
这行代码重定向了读端,
execlp("wc","wc","-w",NULL);
读到了ls命令再加上wc -w这样就输出了 ls | wc -w的效果。
在实现一个例子:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define ERR_EXIT(m) \
do \
{ \
perror(m); \
exit(EXIT_FAILURE); \
}while(0)
int main()
{
close(0);
open("pip.cpp",O_RDONLY);
close(1);
open("01pipe.cpp",O_WRONLY | O_CREAT | O_TRUNC,0644);
execlp("cat","cat",NULL);
return 0;
}
这行代码的意思是复制代码:
先关闭标准输出标准输出。打开pip.cpp文件,在创建一个01pipe.cpp文件,cat命令当单独使用的时候,会把键盘输入的在打印出来,由于关闭了标准输入和输出,所以会把pip.cpp的文件输出到01pipe.cpp中。假如想打印出这个代码,可以这样做。
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define ERR_EXIT(m) \
do \
{ \
perror(m); \
exit(EXIT_FAILURE); \
}while(0)
int main()
{
close(0);
open("04pipe.cpp",O_RDONLY);
execlp("cat","cat",NULL);
return 0;
}
执行结果。
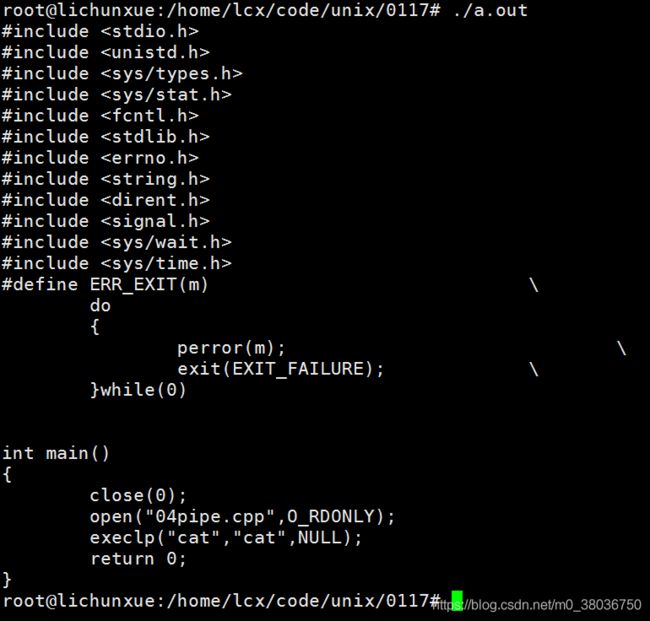
之前写过如何打印自己的代码?这个也是可以实现的。
https://blog.csdn.net/m0_38036750/article/details/85066109
这篇文章是写的如何打印自己的代码,效果一样,但是这样写会更简单。
管道的读写规则
当没有数据可读时:
O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止。
O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。
如果所有管道写端对应的文件描述符被关闭,则read返回0.
如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE
当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
命名管道(FIFO)
管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。
如果我们想在不相关的进程之间交换数据,可以使用FIFO文件来做这项工作,它经常被称为命名管道。
命名管道是一种特殊类型的文件。
创建一个命名管道:
命名管道可以从命令行上创建,命令行方法使用下面这个命令:
mkfifo filename
命名管道也可以从程序里创建,相关函数有:
int mkfifo(const char *filename,mode_t mode);
代码:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define ERR_EXIT(m) \
do \
{ \
perror(m); \
exit(EXIT_FAILURE); \
}while(0)
int main()
{
mkfifo("p2",0644);
return 0;
}
执行结果:
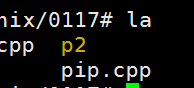
p2是一个管道文件,这个和mkfifo filename相似。
匿名管道和命名管道
匿名管道由pipe函数创建并打开。
命名管道由mkfifo函数创建,打开用open
FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在他们创建与打开的方式不同,一但这些工作完成之后,他们具有相同的语义。
命名管道的打开规则
如果当前打开操作是为读而打开FIFO时
O_NONBLOCK disable:阻塞直到有相应进程为写而打开该FIFO
O_NONBLOCK enable:立刻返回成功
如果当前打开操作是为写而打开FIFO时
O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO
O_NONBLOCK enable:立刻返回失败,错误码为ENXIO