Paper Notes——Deep Learning In Program Synthesis and Induction
Neural program synthesis&Induction的三篇入门论文,在期末过后的招生季,在往返南北的飞机上、酒店房间的小憩中断断续续地读下来,在此记之。
By Samuel Chen 2019.6
个人博客原文链接
1.Recent Advances in Neural Program Synthesis
综述性文章,介绍了Program Induction的概念、常见模型、它们的表现及改进方向,读毕对Program Induction领域有了大致的整体性把握。深度学习在CV和NLP等领域都取得了巨大突破,但在Program Synthesis上依然任重道远。
1.1 Introduction
| 方法 | 特点 |
|---|---|
| Program Synthesis | 显式返回程序,可读性强,但遇到很多瓶颈 |
| Program Induction | 引入Deep Learning,模拟性的黑盒,无法解读,Generality非常重要 |
深度学习的火爆让我们在程序生成领域也看到了希望,但程序生成和实体识别、机器翻译等问题有着一大不同,就是这些DL已大获成功的领域中,输入空间是连续的,可以用可微函数表示(因此可以使用梯度下降优化),只有数据的集合对人来说才有意义,如图像的像素点只有组合起来才有意义,而NLP领域中,字词虽然是离散的,DL却是通过学习连续的词向量起作用的。神经网络适于通过这种高维的、连续的状态空间表示离散的实体,这是人工智能中联结主义的观点。
而对我们关心的Program Synthesis领域,程序的每个原子结构都有其内在含义,不存在连续的状态空间,而由于字典较小和抽象性等原因,嵌入的办法也很难解决问题。由于训练数据是成对的输入/输出,神经网络无法学习具体的程序结构知识,联结主义在这里是有瓶颈的。
所以从1960年代起,早期的研究者多是遵循符号主义的观点,通过上下文无关语法树学习领域语言,进而构建有意义的程序。其缺点是学习本身不是直接的任务,目标不可微,不能用梯度下降优化。现有的方法实质上是求解约束可满足性问题,在尽可能缩小状态空间的前提下搜索解决方案。如模可满足性运算器(SMT solver)已在正确性和泛化能力上取得了突破。
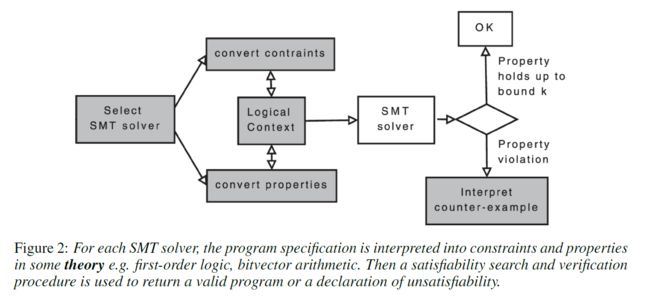
时至今日,多数研究者认为符号主义和联结主义的互补才是程序生成的出路。人在符号控制方面是独一无二的,而信息处理的机制可以由联结主义的神经模型解决。好的Synthesis系统也应当如此,“where symbols are built up from embeddings of the program state space.”
1.2 Neural Program Induction Models
1.2.1 基础——RNN & LSTM
RNN及其改进版本LSTM适合处理序列数据,双层LSTM形成的encoder-decoder结构不仅适于机器翻译,同样适用于输入输出不定长的Program Induction。以下介绍几种改进方向。
1.2.2 Convolutional Recurrence
将CNN与GRU融合,代表作是Neural GPU,在循环神经网络的基础上,在每个神经元处加入卷积操作,以GRU为基础,以门控的CGRU为神经单元加入卷积操作,用3维向量嵌入表示hidden state,长度为n则经过n个CGRU单元输出,再进行解码。缺陷是每个时刻认为1个3D的状态向量包含之前所有的信息,可能无法真正利用之前1-t-1时刻的所有信息。
1.2.3 Attention
借鉴机器翻译中常见的Attention机制,代表是Pointer-Net.此模型可解决比训练数据规模更大的测试问题,表现 出泛化性能的进步,但在大规模数据和corner cases上的性能表现无法保证。
1.2.4 Attention with memory
The Neural Turing Machine (NTM)和Differentiable Neural Computer (DNC),加入外部存储,本质是发出读写命令的RNN controller,都是图灵完备的,但泛化能力和训练的方便程度都不如Pointer Net
1.2.5 Memory and Pre-Defined Primitives
之前几种方案都是单纯的联结主义,而Neural Programmer 和 Neural RAM不直接对memory发出读写指令,而是对数据进行已显式定义好的一元或二元的基本运算,通过组合基本运算构成复杂程序。
组分:
- RNN Controller
- attention distributions
- memory unit
- Neural Programmer : take natural language inputs,is designed to be an automatic Question-Answering system that learns the latent programs required to answer its questions
- Neural RAM:creating highly compositional programs,can take hundreds of timesteps to complete,can create coherent programsthat span a much higher number of timesteps
1.2.6 Function Hierarchy
之前提到的模型都是以输入-输出对作为训练数据,容易过拟合,监督太弱,不适于深度学习。Neural Programmer-Interpreter (NPI)通过增加模型复杂度和监督的粒度解决这个问题。最重要的改进是让函数通过创建新的栈帧(new stack frames)调用子函数,即调用新函数时将RNN的隐藏状态设为0,将新的程序嵌入向量、参数和上下文作为输入,返回母函数时通过A sigmoidal “return to caller” unit to terminate the current stack frame。问题是如何调用栈帧需要学习,对训练数据要求较高。作者提出的Neural Program Lattices (NPL),通过a new neural network module uses dynamic programming estimate the likelihood of which stack frame the program exists,在更弱的监督下取得了与NPI相似的效果。
1.3 Analysis of Performance
通过四个难度递增的任务评估各个模型。
1.3.1算术
Neural GPU在二进制上表现出色,但十进制有问题,而且corner cases无法泛化。NPI和NPL在二进制和十进制加法都能handle,而且能通过Function Hierarchy学习进位操作,泛化性能更好。
1.3.2 数列操作
NTM在20左右的小规模复制和排序上有良好表现,超过了传统的LSTM。Neural RAM在规模50左右的数列复制、翻转、轮换等操作都有良好表现,但不能很好排序,而NPI能很好地学习冒泡排序算法。
1.3.3 组合优化
很多是NP难问题,普遍认为用神经网络处理嵌入表示更好解决。DNC目前能处理小规模的TSP问题。
1.3.4 Semantic Query Parsing
缺乏严谨的大规模数据集
1.4 Strategies to Reshape Program Induction
1.4.1 Structured Attention
利用线性条件随机场,把握过去的状态集体间的关系
1.4.2 Hierarchical Memory
利用二叉树等机构优化memory,加快速度
1.4.3 Enabling Recursion
单纯的连接主义模型是无法进行递归调用的,Neural RAM和Neural Programmer只能使用事先定义好的操作,无法动态学习,只有Neural Programmer-Interpreter (NPI) is the only currently existing Neural Programming Architecture (NPA) that could support recursion.而且NPI的拥有可证明的泛化能力。
1.4.4 Greedy Algorithms
强化学习的方法适合产生贪心解,并有较好的灵活性和泛化性能
1.5 Neural Program Synthesis
1.5.1 Recent Examples
-
Base: FlashFill
-
NSPS:提出R3EE,将程序抽象为树状的RNN
-
RobustFill:仍是带attention的s2s模型,make modifications to the
DSL so as to increase the vocabulary by making compositional programs into literal ones
-
Abstract Syntax Networks:the decoder which generates the AST is actually composed of several mutually recursive modules
1.5.2 Future Recommendations
- Specifically designing neural architectures
- NLP
- RL
- Reprsentation Learinng
- automation in learning
- meta optimization
2.Code Completion with Neural Attention and Pointer Networks
IJCAI2018的文章,针对语言模型无法处理OoV(out of vocabulary)的问题,提出了pointer mixture network
- 带Attention的LSTM生成词典内成分
- pointer结构根据上下文补充Oov
- swicher决定何时用LSTM,何时用pointer
在JS和Python这两种动态类型语言数据集上测试,取得了state-of-arts效果。
具体实现:
2.1 程序表示:AST
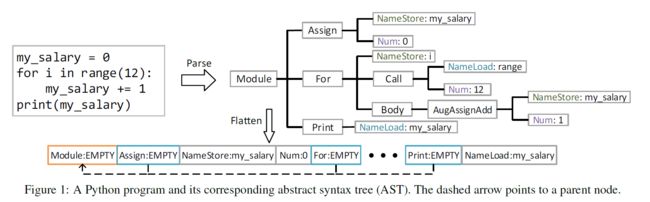
- 结点含义
- 扁平序列化(增加两个bit)
- 程序生成→Seq2seq
2.2 Neural Language Model:LSTM Encoder-Decoder and Attention Mechanism
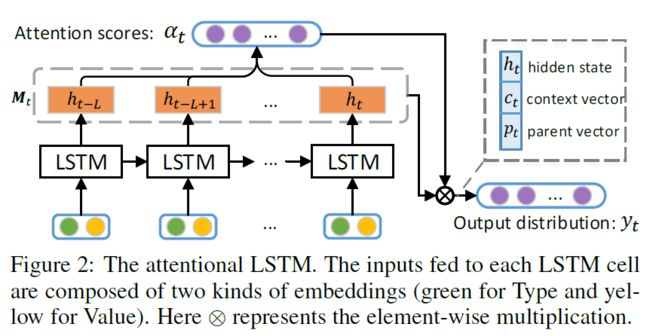
- Context Attention
- Parent Attention
2.3 Pointer Mixture
[外链图片转存失败(img-0aLIFn7Z-1562330818399)(C:\Users\css\AppData\Roaming\Typora\typora-user-images\1562329917192.png)]

2.4 Experiments
要点:
- 来自JS和Py的数据集
- 只对Value使用带Pointer的混合结构
- 评测指标:Accuracy
3.NEURAL SKETCH LEARNING FOR CONDITIONAL PROGRAM GENERATION
3.1 概述
ICLR2018的oral,提出解决根据标签条件(API calls and types)生成类Java语言代码的任务面临两大挑战:
- 语义与语法限制
- 低级特征阻碍学习
解决方案是一个叫BAYOU的系统,让神经网络学习生成满足语法要求的代码框架(忽略语义要求),is to learn not over source code, but over tree-structured syntactic models, or sketches, of programs,再通过组合方法补全低级的语义特征。生成可编译的代码。
目标:

实现:
Label域X包含三类属性:API CALLS,OBJECT TYPES,KEYWORDS
思路:两种工具对应两类内容:
- Low level Features:主要是semantic的,these are relatively easy for a combinatorial,
syntax-guided program synthesizer - Syntax Features:主要是类型和API调用等语法信息 用树状结构表示,hypothesize should be relatively easy for a statistical learner
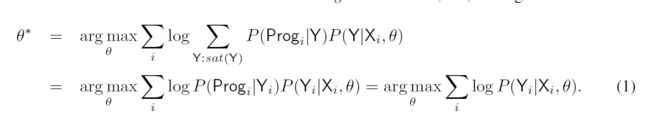
3.2 Sketch Learning ——Gaussian Encoder-Decoder(GED)
$ P(Y | X , \Theta) = \int_{Z \in R^m}P(Z|X,\Theta)P(Y|Z,\Theta) dZ$
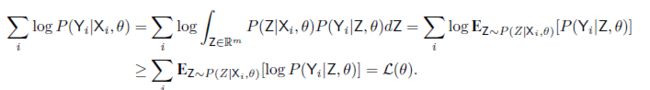
用到Jansen’s inequality,极大似然估计 Θ \Theta Θ
3.3 Combinatorial Concretization
a type-directed, stochastic search procedure that builds on
combinatorial methods for program synthesis