《机器学习》学习笔记(16) - 强化学习
16.1 任务与奖赏
此小节介绍强化学习的基本概念,并且说明了强化学习与机器学习的区别。
- 基本概念
强化学习(英语:Reinforcement learning,简称RL),是机器学习的一个领域,通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体定义课本有。其强调如何基于环境而行动,以取得最大化的预期利益。强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
状态(X):机器对环境的感知,所有可能的状态称为状态空间;
动作(A):机器所采取的动作,所有能采取的动作构成动作空间;
转移概率(P):当执行某个动作后,当前状态会以某种概率转移到另一个状态;
奖赏函数(R):在状态转移的同时,环境给反馈给机器一个奖赏。

机器要做的是通过在环境中不断地尝试而学得一个‘策略(policy)π’,常见的两种策略表示方法:
确定性策略:π(x)=a,即在状态x下执行a动作;
随机性策略:P=π(x,a),即在状态x下执行a动作的概率。
策略的优劣取决于长期执行这一策略后得到的累积奖赏。常用的累积奖赏分为两种:

强化学习与监督学习的差别,主要在于强化学习并没有监督学习中有标记样本,即在强化学习中机器只能通过反思(奖赏)的反馈,来判断自己之前的动作是否正确来进行学习,强化学习的反馈是有延迟的,而监督学习的反馈是及时快速的。
16.2 K-摇臂赌博机
此小节介绍K-摇臂赌博机,强化学习任务的最终奖赏是在多步动作之后才能观察到,而这里的K-摇臂赌博机即考虑最简单的情况,最大化单步奖赏。
由此开始出现的值函数指的是如果你从某一个状态或者状态行动对开始,一直按照某个策略运行下去最终获得的期望回报。
- 探索与利用
由此引出要求得最大单步奖赏,即要知道每个动作带来的奖赏。若每个动作的奖赏值为确定值,则只需要将每个动作尝试一遍即可,但大多数情形下,一个动作的奖赏值来源于一个概率分布,因此需要进行多次的尝试。
那如何利用有限的次数进行有效地探索呢?
这里有两种基本的想法:
仅探索法:将尝试的机会平均分给每一个动作,即轮流执行,最终将每个动作的平均奖赏作为期望奖赏的近似值。
仅利用法:将尝试的机会分给目前为止平均奖赏值最大的动作。
显然上述两种方法是相互矛盾的,仅探索法能较好地估算每个动作的期望奖赏,但是失去很多选择最优动作的机会;仅利用法在每次尝试之后都更新尝试策略,符合强化学习的思维,但若没有估计好期望奖赏,容易找不到最优动作。因此需要在这两者之间进行折中。
以下是两种常见折中的方法:
- ε-贪心
ε-贪心法基于一个概率来对探索和利用进行折中,具体即每次尝试时,以ε的概率进行探索;以1-ε的概率进行利用。ε-贪心法只需记录每个动作的当前平均奖赏值与被选中的次数,便可以增量式更新。

具体算法中ε根据奖赏的概率分布来调整,概率分布较宽时取值较大(分布宽应尽量探索),取值较集中时取值较小(此时通过利用容易得到最优解)。
- Softmax
Softmax算法则基于当前已知每个动作的平均奖赏值来对探索和利用进行折中,Softmax函数将一组值转化为一组概率,值越大对应的概率也越高,因此当前平均奖赏值越高的动作被选中的几率也越大。

(公式不知道怎么来的,这里面Boltzmann是热学的公式吧)

其中∝是正比于的意思,通过公式可看出,t趋于零时Softmax趋向仅利用,t趋向无穷时Softmax趋向仅探索。

ε-贪心算法与Softmax算法差别在于第4行,而算法的优劣则取决于具体应用,如下图,通过尝试次数以及概率分布等等原因。

但这两者都并没有考虑马尔可夫决策过程的结构,即这是单步的问题。于是引出下一小节内容。
16.3 有模型学习
若学习任务中的四个要素都已知,即状态空间、动作空间、转移概率以及奖赏函数都已经给出,这样的情形称为“有模型学习”。假设状态空间和动作空间均为有限,即均为离散值,这样我们不用通过尝试便可以对某个策略进行评估。
- 策略评估
模型已知的前提下,我们可以对任意策略的进行评估。一般常使用以下两种值函数来评估某个策略的优劣:
状态值函数(V):V(x),即从状态x出发,使用π策略所带来的累积奖赏;
状态-动作值函数(Q):Q(x,a),即从状态x出发,执行动作a后再使用π策略所带来的累积奖赏。
根据累积奖赏的定义,我们可以引入T步累积奖赏与r折扣累积奖赏:

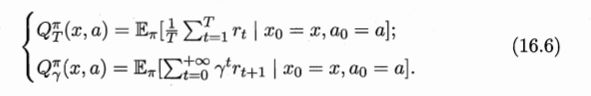
由于马尔可夫性质,对T步奖赏变化成递归形式:

(注视中提到的Bellman等式即递归,而全概率展开可自行百度)
通过这样的递归等式来求解计算值函数,实际上就是一种动态规划算法。只需迭代T轮就能精确的求出值函数。
而对于r折扣累积奖赏,由于r在t很大的时候趋向零,因此只需设置一个阈值,当前后两次改变量小于该阈值即停止迭代,得出结果既可。

- 策略改进
理想的策略应能使得每个状态的累积奖赏之和最大,因此对于给定的某个策略,我们需要对其进行改进,从而得到最优的值函数。

最优Bellman等式改进策略的方式为:将策略选择的动作改为当前最优的动作。即选择当前最优动作相当于将所有的概率都赋给累积奖赏值最大的动作,因此每次改进都会使得值函数单调递增,直到满足了Bellman等式即找到最优解。
- 策略迭代与值迭代
策略评估与策略改进结合起来,我们便得到了生成最优策略的方法。首先给定一个随机策略,现对该策略进行评估,然后再改进,接着再评估/改进一直到策略收敛、不再发生改变。这便是策略迭代算法。

而由于策略迭代法在每次改进策略后都要对策略进行重新评估,因此比较耗时。若从最优化值函数的角度出发,即先迭代得到最优的值函数,再来计算如何改变策略,这便是值迭代算法。

16.4 免模型学习
在现实的强化学习任务中,环境的转移函数与奖赏函数往往很难得知,因此我们需要考虑在不依赖于环境参数的条件下建立强化学习模型,这便是免模型学习。
- 蒙特卡罗强化学习
在免模型的情况下,之前方法都无法进行,受K-摇臂赌博机的启发,一种直接的策略评估替代方法是多次“采样”,然后求取平均累积奖赏作为期望累积奖赏的近似,这就是蒙特卡罗强化学习:对采样轨迹中的每一对状态-动作,记录其后的奖赏值之和,作为该状态-动作的一次累积奖赏,通过多次采样后,使用累积奖赏的平均作为状态-动作值的估计,并引入ε-贪心策略保证采样的多样性。
被评估和被改进的都是同一个策略,因此称为同策略蒙特卡罗强化学习算法。

然而我们引入ε-贪心仅是为了便于采样评估,而在使用策略时并不需要ε-贪心,那能否仅在评估时使用ε-贪心策略,而在改进时使用原始策略呢?这便是异策略蒙特卡罗强化学习算法。

后续更新…
- 时序差分学习
蒙特卡罗强化学习虽然克服了免模型学习的困难,但是此算法需要采样轨迹后更新策略的值估计,相比之前的策略迭代和值迭代效率显然低得多。
主要原因是因为蒙特卡罗没有充分利用MDP结构,时序差分(Temporal Difference,简称TD)则结合了动态规划与蒙特卡罗的方法思想。
即将蒙特卡罗强化学习算法中求平均期望累积奖赏的近似不再是等待所以状态-动作之后,而是增量式进行。即:
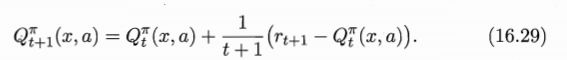
(t个采样的Q为假设的值)
与之前的ε-贪心方法类似,通过增量求和: 
同样时序差分学习也有同策略Sarsa算法(取其state,action,reward,state(当前状态),action(当前动作)首字母)以及由Sarsa算法修改的异策略即为Q-learning算法。

从算法中可以看出来,Q-learning是比较冒进的算法,选择一条路直直冲过去,而Sarsa则相对比较珍惜自己的‘生命’。
16.5 值函数近似
前面我们都是假定是在有限状态空间上进行,然而,现实中面临的状态空间往往是连续的,有无穷多个状态,此时我们应该怎么办?
最直接的方法对状态空间离散化,然而如何离散化这是一个难题。
因此我们不妨直接对连续状态空间的值函数进行学习。
后续更新…
16.6 模仿学习
由于现实中往往可以得到人类专家的决策过程范例,因此可以从范例中学习,称为模仿学习(imitation learning)。
- 直接模仿学习
强化学习中多步决策搜索空间巨大,基于累积学习十分困难,因此我们可以直接模仿人类专家的状态-动作学习。(例如:强化学习可以容易的完成打砖头的游戏,然而很难完成蒙特祖玛复仇类似超级玛丽的游戏,而通过模仿则可以实现)

将这些数据整理后按照前面的方法去学习即可。
- 逆强化学习
由于很多情况下设计奖赏函数往往很困难,从人类专家提供的范例数据反推出奖赏函数有助于解决该问题,这就是逆强化学习。
思想:寻找某种奖赏函数使得范例数据是最优的,然后既可使用这个奖赏函数来训练强化学习。
然而我们很难获得所有策略,一个较好的方法是从随机策略开始,迭代求解更好的奖赏函数,基于奖赏函数获得更好的策略。

学习过程中参考了资料如下:
1、机器学习 - 周志华
2、百度百科
3、https://blog.csdn.net/u011826404/article/details/75576856