HBase原理|HBase内存管理之MemStore进化论
Java工程中内存管理总是一个绕不过去的知识模块,无论HBase、Flink还是Spark等,如果使用的JVM堆比较大同时对读写延迟等性能有较高要求,一般都会选择自己管理内存,而且一般都会选择使用部分堆外内存。HBase系统中有两块大的内存管理模块,一块是MemStore ,一块是BlockCache,这两块内存的管理在HBase的版本迭代过程中不断进行过各种优化,接下来笔者结合自己的理解,将这两个模块的内存管理迭代过程通过几篇文章梳理一遍,相信很多优化方案在各个系统中都有,举一反三,个人觉得对内核开发有很大的学习意义。本篇文章重点集中介绍MemStore内存管理优化。
基于跳表实现的MemStore基础模型
实现MemStore模型的数据结构是SkipList(跳表),跳表可以实现高效的查询\插入\删除操作,这些操作的期望复杂度都是O(logN)。另外,因为跳表本质上是由链表构成,所以理解和实现都更加简单。这是很多KV数据库(Redis、LevelDB等)使用跳表实现有序数据集合的两个主要原因。跳表数据结构不再赘述,网上有比较多的介绍,可以参考。
JDK原生自带的跳表实现目前只有ConcurrentSkipListMap(简称CSLM,注意:ConcurrentSkipListSet是基于ConcurrentSkipListMap实现的)。ConcurrentSkipListMap是JDK Map的一种实现,所以本质上是一种Map,不过这个Map中的元素是有序的。这个有序的保证就是通过跳表实现的。ConcurrentSkipListMap的结构如下图所示:

基于ConcurrentSkipListMap这样的基础数据结构,按照最简单的思路来看,如果写入一个KeyValue到MemStore中,肯定是如下的写入步骤:
-
在JVM堆中为KeyValue对象申请一块内存区域。
-
调用ConcurrentSkipListMap的put(K key, V value)方法将这个KeyValue对象作为参数传入。

图1 基于跳表实现的最基础MemStore模型
对吧,这样的话,实现非常简单。根据Key查询可以利用跳表的有序性。但是这样的内存存储模型会有很多问题(具体见下节),本文就基于这个最原始的模型开始优化之旅。
再看图1这个存储模型,可以发现MemStore从内存管理上来说主要由两个部分组成,一个是原生KeyValue的内存管理,见上图下半部分;一个是ConcurrentSkipListMap的内存管理,见上图上半部分。接下来笔者分别就这两个部分的内存管理优化,分成两个小节进行深入介绍。
MemStore中原生KeyValue对象内存存储优化
对于HBase这样基于LSM实现的MemStore来说,上述实现方案每写入一个KeyValue,在没有写入ConcurrentSkipList之前就需要申请一个内存对象,可以想见,对于很多写入吞吐量几万每秒的业务来说,每秒就会有几万个内存对象产生,这些对象会在内存中存在很长一段时间,对应的会晋升到老生代,一旦执行了flush操作,老生代的这些对象会被GC回收掉。这样的内存玩法,会导致JVM的GC压力非常大。GC压力主要来源于:这些内存对象一旦晋升到老生代,执行完Major GC后会存在大量的非常小的内存碎片,这些内存碎片会引起频繁的Full GC,而且每次Full GC的时间会异常的长。
-
MemStore引入MemStoreLAB
针对上面的问题,MemStore借鉴TLAB(Thread Local Allocation Buffer)机制,实现了MemStoreLAB,简称MSLAB。基于MSLAB实现写入的核心流程如下:
-
一个KeyValue写入之后不再单独为KeyValue申请内存,而是提前申请好一个2M大小的内存区域(Chunk)。
-
将写入的KeyValue顺序复制到申请的Chunk中,一旦Chunk写满,再申请下一个Chunk。
-
将KeyValue复制到Chunk中后,生成一个Cell对象(这个Cell对象在源码中为ByteBufferChunkKeyValue),这个Cell对象指向Chunk中的KeyValue内存区域。
-
将这个Cell对象作为Key和Value写入ConcurrentSkipListMap中。
-
原生的KeyValue对象写入到Chunk之后就没有再被引用,所以很快就会被Young GC回收掉。
基于MSLAB的MemStore可以表征为下图:

图2 基于MSLAB实现的MemStore示意图
对比图1和图2,引入MSLAB之后MemStore实现稍显复杂,后者引入了两个长寿内存对象,一个是2M的Chunk对象,一个是指向KV内存区域的Cell对象,这两种内存对象都会晋升到老生代。这里分别针对这两个内存对象进行解读:
-
引入2M大小的Chunk对象之后,数据写入就不再需要为每个KeyValue申请一个内存对象,这样可以大大降低内存碎片的产生。
-
那Cell对象不会引起内存碎片?这个笔者查阅了很多资料都没有找到相关的说明,个人理解是因为Cell相对原生KeyValue来说占用内存小的多,可以一定程度上可以忽略。Cell与KeyValue对象分别占用内存大小如下所示:
ByteBufferChunkKeyValue类(Cell对象)的字段如下:
protected final ByteBuffer buf;
protected final int offset;
protected final int length;
private long seqId = 0;
对象大小可以表示为对象头和各个字段的大小总和,其中对象头占16Byte,Reference类型占8Byte,int类型占4Byte,long类型占8Byte,Cell对象大小可以表示为:ClassSize.OBJECT + ClassSize.REFERENCE + (2 * Bytes.SIZEOF_INT) + Bytes.SIZEOF_LONG = 16 + 8 + 2 * 4 + 8 = 40 Byte。
原生KeyValue对象大小为:ClassSize.OBJECT(16) + Key Length(4) + Value Length(4) + Row Length(2) + FAMILY LENGTH(1) + TIMESTAMP_TYPE LENGTH(9) + length(row) + length(column family) + length(column qualifier) + length(value) = 36 + length(row) + length(column family) + length(column qualifier) + length(value)
按照一个KV中length(row) + length(column family) + length(column qualifier) + length(value)总计84Byte算,原生KeyValue对象大小为120Byte,为Cell对象的3倍。
引入MSLAB后一定程度上降低了老生代内存碎片的产生,进而降低了Promotion Failure类型的Full GC产生。那还有没有进一步的优化空间呢?针对Chunk,还有两个大的优化思路:
-
MemStore引入ChunkPool
MSLAB机制中KeyValue写入Chunk,如果Chunk写满了会在JVM堆内存申请一个新的Chunk。引入ChunkPool后,申请Chunk都从ChunkPool中申请,如果ChunkPool中没有可用的空闲Chunk,才会从JVM堆内存中申请新Chunk。如果一个MemStore执行flush操作后,这个MemStore对应的所有Chunk都可以被回收,回收后重新进入池子中,以备下次使用。基本原理如图3、图4所示:

图3 基于ChunkPool实现的Chunk管理模型
每个RegionServer会有一个全局的Chunk管理器,负责Chunk的生成、回收等。MemStore申请Chunk对象会发送请求让Chunk管理器创建新Chunk,Chunk管理器会检查当前是否有空闲Chunk,如果有空闲Chunk,就会将这个Chunk对象分配给MemStore,否则从JVM堆上重新申请。每个MemStore仅持有Chunk内存区域的引用,如图3中MemStoreLAB的小格子。
下图是MemStore执行Flush之后,对应的所有Chunk对象中KV落盘形成HFile,这部分Chunk就可以被Chunk管理器回收到空闲池子。
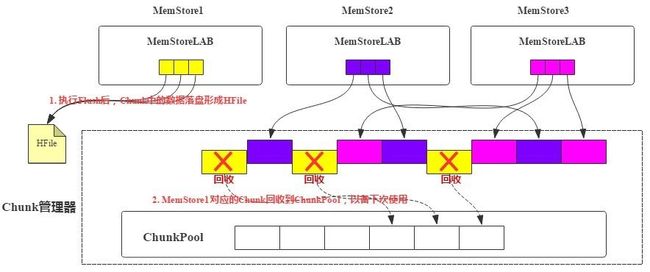
图4 MemStore Flush过程中Chunk回收过程
使用ChunkPool的好处是什么呢?因为Chunk可以回收再使用,这就一定程度上降低了Chunk对象申请的频率,有利于Young GC。
-
MemStore Offheap实现
除过ChunkPool之外,HBase 2.x版本针对Chunk对象优化的另一个思路是将Chunk使用的这部分内存堆外化。关于堆外内存的细节内容,笔者将会在下篇文章重点分析,这篇文章只做个简单介绍。
Chunk堆外化实现比较简单,在创建新Chunk时根据用户配置选择是否使用堆外内存,如果使用堆外内存,就使用JDK提供的ByteBuffer.allocateDirect方法在堆外申请特定大小的内存区域,否则使用ByteBuffer.allocate方法在堆内申请。如果不做配置,默认使用堆内内存,用户可以设置hbase.regionserver.offheap.global.memstore.size这个值为大于0的值开启堆外,表示RegionServer中所有MemStore可以使用的堆外内存总大小。
-
原生KeyValue对象内存存储优化总结
基于原生KeyValue直接写入ConcurrentSkipListMap方案,HBase在之后的版本中不断优化,针对原生KeyValue内存管理部分分别采用MemStoreLAB机制、ChunkPool机制以及Chunk Offheap机制三种策略,对GC性能进行持续优化。
第一节我们提到MemStore内存管理分为原生KeyValue内存管理和ConcurrentSkipListMap内存管理两个部分,第二节重点介绍了HBase针对原生KeyValue内存管理所采用的3种优化方案。接下来第三节首先介绍JDK原生ConcurrentSkipListMap在内存管理方面的主要问题,以及HBase在2.x版本以及3.x版本针对ConcurrentSkipListMap内存管理问题进行优化的两个方案。
ConcurrentSkipListMap数据结构存在的问题以及优化方案
-
一个KV在MemStore中的旅程
经过上面知识的铺垫我们知道,一个KV写入MemStore会经过如下几个核心步骤:
-
在Chunk中申请一段与KV相同大小的内存空间将KV拷贝进去。
-
生成一个Cell对象,该对象包含指向Chunk中对应数据块的指针、offsize以及length。
-
将这个Cell对象分别作为Key和Value插入到CSLM表示的跳表Map中。
有了CSLM这样的跳表之后,查询就可以在O(N)时间复杂度内完成。但是,JDK实现的CSLM跳表在内存使用方面有些粗糙,导致内存中产生了大量意义不大的Java对象,这些Java对象的频繁产生一方面导致内存效率使用比较低,另一方面会引起比较严重的Java GC。为什么JDK实现的CSLM跳表会有这样的问题?接着往下看。
-
MemStore ConcurrentSkipListMap数据结构存在的问题
原生ConcurrentSkipListMap逻辑示意图如下图所示:
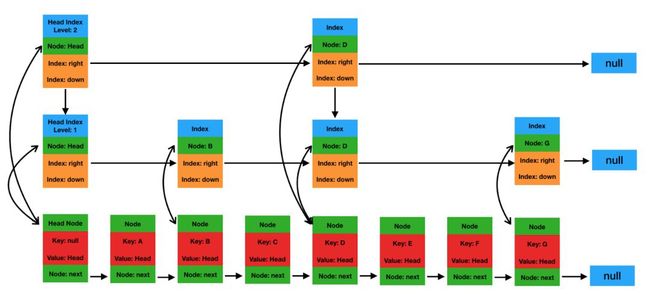
图5 CSLM示意图
JDK自带的CSLM每个节点都是一个对象,其中最底层节点是Node对象,其他上层节点是Index对象。Node对象和Index对象的核心字段可以参考CSLM源码实现:
/**
* Nodes hold keys and values, and are singly linked in sorted
* order, possibly with some intervening marker nodes. The list is
* headed by a dummy node accessible as head.node. The value field
* is declared only as Object because it takes special non-V
* values for marker and header nodes.
*/
static final class Node {
final K key;
volatile Object value;
volatile Node next;
......
}
/**
* Index nodes represent the levels of the skip list. Note that
* even though both Nodes and Indexes have forward-pointing
* fields, they have different types and are handled in different
* ways, that can't nicely be captured by placing field in a
* shared abstract class.
*/
static class Index {
final Node node;
final Index down;
volatile Index right;
......
}
其中Node对象由一个key、一个value以及指向下一个Node节点的引用组成。Index对象由一个Node节点引用、向下和向右的引用组成。
根据上述代码可以知道:
-
每个Node对象有3个引用变量,分别指向Key(Cell对象)、Value(Cell对象)以及Next Node。
-
每个Index对象有3个引用变量,分别指向代表的Node节点,下层Index节点以及右侧Index节点。
假设业务写入50M规模的KV,那写入到MemStore后,除了正常存储KV数据占用的Chunk对象外,CSLM占用的对象和内存分别有多少呢?
-
对象数:50M个Node对象,假如跳表中level N层的Index节点个数是50M/2^(N+2),那么总共会有50M/4个Index对象。整个CSLM一共有62.5M个对象。
-
内存占用情况(均认为JVM设置大于32G,未开启压缩指针):
(1)Node对象
50M * (ClassSize.OBJECT + ClassSize.REFERENCE + ClassSize.REFERENCE + ClassSize.REFERENCE) =50M * (16 + 8 + 8 + 8) = 2000M
(2)Index对象
12.5M * (ClassSize.OBJECT + ClassSize.REFERENCE + ClassSize.REFERENCE + ClassSize.REFERENCE) =12.5M * (16 + 8 + 8 + 8) = 500M
总内存占用2500M。假设业务写入的KV为50Byte,那总的数据量为2500M。为了存储这2500M大小的数据,MemStore又产生了额外的2500M内存。
-
CompactingMemStore如何优化这个困境
CompactingMemStore的核心工作原理如图所示:
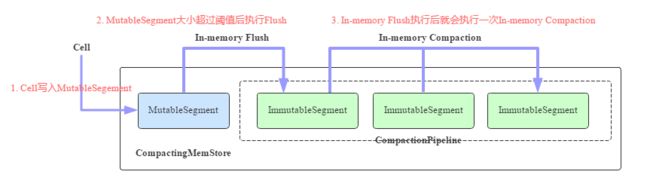
图6 CompactingMemStore核心工作原理示意图
-
一个Cell写入到Region后会先写入MutableSegment中。MutableSegment可以认为就是一个小的MemStore,MutableSegment包含一个MSLAB存储Chunk,同时包含一个ConcurrentSkipListMap。
-
默认情况下一旦MutableSegment的大小超过2M,就会执行In-memory Flush操作,将MutableSegment变为ImmutableSegment,并重新生成一个新的MutableSegment接收写入。ImmutableSegment有多个实现类,In-memory Flush生成的ImmutableSegment为CSLMImmutableSegment,可以预见这个ImmutableSegment在数据结构上也是使用CSLM。
-
每次执行完In-memory Flush之后,RegionServer都会启动一个异步线程执行In-memory Compaction。In-memory Compaction的本质是将CSLMImmutableSegment变为CellArrayImmutableSegment或者CellChunkImmutableSegment,这才是CompactingMemStore最核心的地方。那什么是CellArrayImmutableSegment/CellChunkImmutableSegment呢?为什么要做这样的转换?接着往下看。
-
In-memory Compaction机制
现在我们需要回过头来想想这两个问题:
-
为什么要将一个大的MemStore切分成这么多小的Segment?这么设计的初衷是为In-memory Compaction做准备,只有将MemStore分为MutableSegment和ImmutableSegment,才可能基于ImmutableSegment进行内存优化。
-
如何对ImmutableSegment进行内存优化?答案是将CSLMImmutableSegment变为CellArrayImmutableSegment或者CellChunkImmutableSegment。通过上文的介绍我们知道,CSLM这种数据结构对内存并不友好,因为ImmutableSegment本身已经不再接收任何更新删除写入操作,只允许读操作,这样的话CSLM就可以转换为对内存更加友好的Array或者其他的数据结构。这个转换就是In-memory Compaction。
理清楚上面两个问题,我们再来看看In-memory Compaction的主要流程。如果参与Compaction的Segment只有一个,我们称之为Flatten,非常形象,就是将CSLM拉平为Array或者Chunk,示意图如下图图7所示。
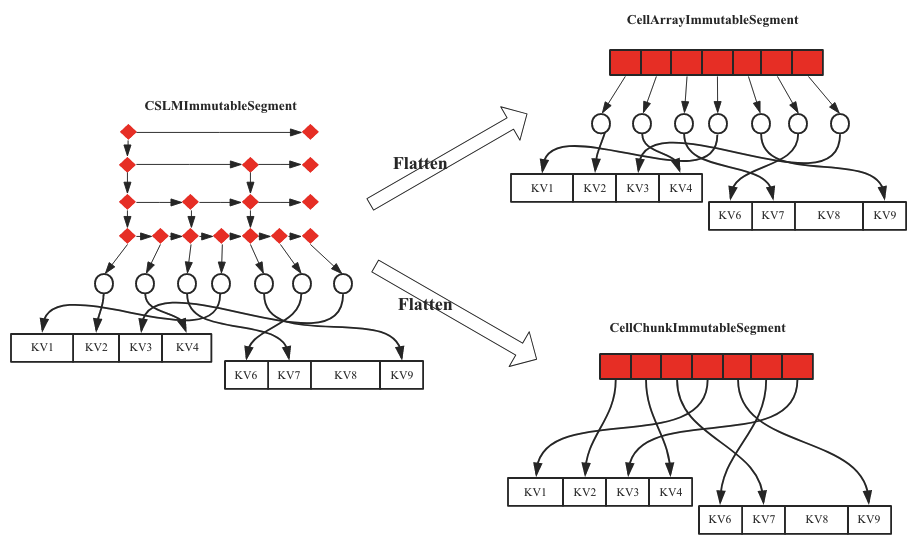
图7 In-Memory Compaction之Flatten示意图
紧接着就有两个问题:CSLMImmutableSegment是如何拉平成CellArrayImmutableSegment?CellArrayImmutableSegment和CellChunkImmutableSegment分别是什么样的数据结构?
CSLMImmutableSegment拉平成CellArrayImmutableSegment比较容易理解,顺序遍历CSLMImmutableSegment读取出对应的Cell,顺序写入一个申请好的数组即可。所以直观上看,CSLMImmutableSegment和CellArrayImmutableSegment相比就是将CSLM变成了一个数组。
那CellArrayImmutableSegment能不能进一步优化呢?是不是可以将Array[Cell]这样一个在内存中不完全连续的对象转变成一块完全连续内容空间的对象,这种优化方式也比较自然,借鉴Chunk思路申请一块2M的大内存空间,遍历数组中的Cell对象,将其顺序拷贝到这个Chunk(这种Chunk称为Index Chunk,区别与存储KV数据的Data Chunk)中,就变成了CellChunkImmutableSegment,将内存由不连续变为连续的一大好处就是变换后连续的内存区域可以在堆外管理,默认情况下In-memory Compaction会直接将CSLMImmutableSegment拉平成CellChunkImmutableSegment。
上述过程是只有一个Segment参与Compaction的流程。如果参与Compaction的Segment个数超过1个,会有两种Compaction的形式:Merge和Compact。先说Merge,Merge的处理流程和Flatten基本一致,如In-Memory Compaction之Merge示意图所示,左侧两个Segment进行合并形成右侧一个大的CellChunkImmutableSegment,合并过程就是顺序遍历左边两个Segment,取出对应的Cell,然后顺序写入右边CellChunkImmutableSegment中。

图8 In-Memory Compaction之Merge示意图
Compaction与Merge的处理流程基本相同,不同的是,Compaction在合并的过程中顺序遍历左边两个Segment,读取对应Cell之后会检测是否有多个版本的Cell,如果存在超过设置版本数的Cell,就将老版本的Cell删掉。因为存在原始KV的变更,所以新生成的Data Chunk会进行重建,这是和Merge最大的不同。如In-Memory Compaction之Compaction示意图所示,右侧新生成的CellChunkImmutableSegment的Data Chunk是经过重建过的。

图9 In-Memory Compaction之Compaction示意图
CompactingMemStore通过将CSLM数据结构变成Array或者Chunk,优化了CSLM数据结构本身内存利用效率低的问题,提升GC效率。另外,提升内存利用率可以使MemStore中存储下更多的KV数据,进而减少Flush和Compaction发生的频率,提升整个HBase集群的性能。
CCSMap又是如何优化CSLM?
CCSMap全称CompactedConcurrentSkipListMap,是阿里巴巴内部版本为了优化CSLM数据结构内存利用效率低所实现的一个新的数据结构。CCSMap数据结构的基本理念是将原生的ConcurrentSkipListMap进行压缩,压缩的直观效果如下图所示:

图10 CCSMap数据结构逻辑示意图
上图中上面结构是原生的CSLM数据结构,下面是CCSMap数据结构,很明显,主要是将Index对象压缩到了Node对象上,数据写入/读取流程和CSLM基本上一致。压缩后可以抹掉Index对象,但是这样的优化显然不是全部。接下来的优化才是重点。
CCSMap数据结构可以认为只有一个Node对象(Index可以理解为Node对象的一个字段),既然只有一种对象,是否可以借鉴MSLAB的思路将Node对象顺序存储到固定大小的Chunk中,这样做的好处显而易见:整个Chunk可以以大块申请,同时可以在堆外申请。CCSMap就是基于这个思路进行的物理存储设计,笔者根据相关Jira上给出的资料以及阅读源代码画出来的一个物理存储示意图:

图11 CCSMap数据结构物理实现示意图
这里有个认知的转换,在CSLM数据结构下,KV就是KV,但是在CCSMap数据结构下,KV需要包装成Node对象,Node对象的核心字段如下:

Node对象除了正常的KV Data之外,还有几个比较重要的字段,meta字段主要存储level,dataLen存储数据大小,nextNode存储当前节点的后继节点,levelIndex是一个数组,表示这个Node在各个Level上Index指向的Node(NodeId)。这样一个Node对象就可以完全表征逻辑示意图中Node节点。
当然在具体实现中如何根据Index存储的一个long类型的NodeId在CCSMap中找到对应的Node,这里面有个小小的技巧,就是这个long类型的NodeId前4Byte表示ChunkId,后4Byte表示对应Node在指定Chunk上的偏移量,这样就可以根据NodeId轻松读取到这个Node对应的内存空间。
根据物理存储示意图,KV数据写入的时候会首先包装成一个Node对象,包装的过程主要是生成level字段,然后根据跳表规则不断查找,确定对应的nextNode和levelIndex[]两个字段。Node对象封装好之后就可以顺序持久化到Chunk中。
-
CCSMap相比CSLM可以节省多少对象?多少内存?
-
减少多少对象?CCSMap将ConcurrentSkipListMap和KV对象一起放到Chunk中去了,所以没有任何对象开销,这点比原生的CSLM优秀了非常多。
-
减少了多少内存?还是假设业务写入50M规模的KV,CCSMap中Node对象中long[] levelIndex会占用12.5M * 8Byte = 100M,另外,dataLen占用4Byte,nextNode占用8Byte,meta占用4Byte,总共占用50 * 16Byte = 800M。所以总计占用900M。相比CSLM的2500M,降低了64%。
MemStore内存进化总结
基于上述长篇大论,我们知道MemStore的内存主要分为两部分,其中一部分是KV存储本身,一部分是CSLM。文中第二节重点介绍了KV存储本身的几个优化思路,包括MSLAB、ChunkPool以及Chunk Offheap等,第三节分别重点介绍了使用CompactingMemStore和CCSMap两种机制对CSLM数据结构进行优化的原理。其实,优化来优化去,最核心的落脚点还是能不能将对象顺序持久化到连续一段内存(Chunk)上,抓住这个最终落脚点非常重要。
最后说点题外话,前一段时间JDK13发布,进一步增强了ZGC特性。ZGC应该是Java历史上最大的改进之一,这点应该没有任何疑问,TB级别的堆可以保证GC时间低于10ms,实际场景中128G内存最大GC时间才1.68ms。如果真是这样的GC性能,可能很多现在我们做的各种内存管理优化在很多年之后都不再是问题。