作者:寒小阳
时间:2013年9月。
出处:http://blog.csdn.net/han_xiaoyang/article/details/11969497。
声明:版权所有,转载请注明出处,谢谢。
0、前言
这一部分的内容原本是打算在之后的字符串或者数组专题里面写的,但看着目前火热进行的各家互联网公司笔试面试中,出现了其中的一两个内容,就随即将这些经 典问题整理整理,单写一篇发上来了。这里争取覆盖面广一些,列举了7个最经典的问题,也会是之后大家笔试面试常见到的问题,而每个问题下都列举了几种思 路,掌握这些经典问题的解题思路和算法相信对同类型问题的解答都能有帮助。
这里总结的几个问题分别是最大子序列和,最长递增子序列,最长公共子串,最长公共子序列,字符串编辑距离,最长不重复子串,最长回文子串。其中前两个问 题是针对数组求解的,后五个问题是针对字符串求解的。多数问题都有动态规划的解法(博主不堪地表示,自己动态规划也较弱,只能想到一些基本的思路),这些 解法需要细细琢磨,可发散式地使用在很多其他的题目上。
一、最大子序列和
这里把最大子序列和放在第一个位置,它并不是字符串相关的问题,事实上它的目的是要找出由数组成的一维数组中和最大的连续子序列。比如[0,-2,3,5,-1,2]应返回9,[-9,-2,-3,-5,-3]应返回-2。
1、动态规划法
你也许从这两个例子中已经可以看出,使用动态规划的方法很容易完成这个任务,只要前i项的和还没有小于0那么子序列就一直向后扩展,否则丢弃之前的子序列开始新的子序列,同时我们要记下各个子序列的和,最后找到和最大的子序列。但是你可能需要谨慎一些,在整个数组都为负的情况下,所以初始的和最大值赋值不当的话可能会出问题。
根据以上的思路我们可以有以下的代码:
- /**********************************************************************
- 动态规划求最大子序列和
- **********************************************************************/
- int Maxsum(int * arr, int size)
- {
- int maxSum = -INF; //很重要,初始值赋值为负无穷大
- int sum = 0;
- for(int i = 0; i < size; ++i)
- {
- //小于0则舍弃
- if(sum < 0)
- {
- sum = arr[i];
- }else
- {
- sum += arr[i];
- }
- //比现有最大值大,则替换
- if(sum > maxSum)
- {
- maxSum = sum;
- }
- }
- return maxSum;
- }
- /*************************************************************************
- 如 果想获得最大子序列和的初始和结束位置怎么办呢?我们知道,每当当前子数组和的小于0时,便是新一轮子数组的开始,每当更新最大和时,便对应可能的结束下 标,这个时候,只要顺便用本轮的起始和结束位置更新始末位置就可以,程序结束,最大子数组和以及其始末位置便一起被记录下来了
- *****************************************************************************/
- void Maxsum_location(int * arr, int size, int & start, int & end)
- {
- int maxSum = -INF;
- int sum = 0;
- int curstart = start = 0; /* curstart记录每次当前起始位置 */
- for(int i = 0; i < size; ++i)
- {
- if(sum < 0)
- {
- sum = arr[i];
- curstart = i; /* 记录当前的起始位置 */
- }else
- {
- sum += arr[i];
- }
- if(sum > maxSum)
- {
- maxSum = sum;
- start = curstart; /* 记录并更新最大子数组起始位置 */
- end = i;
- }
- }
- }
2、分治法
其实数组的问题,最好留点心,有一大部分题目是可以用分治的办法完成的,比如说这道题里面:最大子序列和可能出现在三个地方,1)整个出现在输入数据的左半部分,2)整个出现在输入数据的右半部分,3)或者跨越输入数据的中部从而占据左右两个半部分。可以有以下代码:
- /**************************************************************
- 分治法求解最大子序列和
- ***************************************************************/
- int MaxSumRec( const vector<int> & a, int left, int right )
- {
- if( left == right ) // Base case
- if( a[ left ] > 0 )
- return a[ left ];
- else
- return 0;
- int center = ( left + right ) / 2;
- int maxLeftSum = maxSumRec( a, left, center );
- int maxRightSum = maxSumRec( a, center + 1, right );
- int maxLeftBorderSum = 0, leftBorderSum = 0;
- for( int i = center; i >= left; i-- )
- {
- leftBorderSum += a[ i ];
- if( leftBorderSum > maxLeftBorderSum )
- maxLeftBorderSum = leftBorderSum;
- }
- int maxRightBorderSum = 0, rightBorderSum = 0;
- for( int j = center + 1; j <= right; j++ )
- {
- rightBorderSum += a[ j ];
- if( rightBorderSum > maxRightBorderSum )
- maxRightBorderSum = rightBorderSum;
- }
- return max3( maxLeftSum, maxRightSum, maxLeftBorderSum + maxRightBorderSum );
- }
二、最长递增子序列
和上一问题一样,这是数组序列中的问题,比如arr={1,5,8,2,3,4}的最长递增子序列是1,2,3,4
1、动态规划法
结合上一题的思路,在数组的这类问题里面使用动态规划还是很常见的,从后向前分析,很容易想到,第i个元素之前的最长递增子序列的长度要么是1(比如说递减的数列),要么就是第i-1个元素之前的最长递增子序列加1,我们可以得到以下关系:
LIS[i] = max{1,LIS[k]+1},其中,对于任意的k<=i-1,arr[i] > arr[k],这样arr[i]才能在arr[k]的基础上构成一个新的递增子序列。这种方法代码如下:
- #include
- using namespace std;
- //动态规划法求最长递增子序列 LIS
- int dp[101]; /* 设数组长度不超过100,dp[i]记录到[0,i]数组的LIS */
- int lis; /* LIS 长度 */
- int LIS(int * arr, int size)
- {
- for(int i = 0; i < size; ++i)
- {
- dp[i] = 1;
- for(int j = 0; j < i; ++j)
- {
- if(arr[i] > arr[j] && dp[i] < dp[j] + 1)
- {
- dp[i] = dp[j] + 1;
- if(dp[i] > lis)
- {
- lis = dp[i];
- }
- }
- }
- }
- return lis;
- }
- /* 输出LIS */
- void outputLIS(int * arr, int index)
- {
- bool isLIS = 0;
- if(index < 0 || lis == 0)
- {
- return;
- }
- if(dp[index] == lis)
- {
- --lis;
- isLIS = 1;
- }
- outputLIS(arr,--index);
- if(isLIS)
- {
- printf("%d ",arr[index+1]);
- }
- }
- void main()
- {
- int arr[] = {1,-1,2,-3,4,-5,6,-7};
- /* 输出LIS长度; sizeof 计算数组长度 */
- printf("%d\n",LIS(arr,sizeof(arr)/sizeof(int)));
- /* 输出LIS */
- outputLIS(arr,sizeof(arr)/sizeof(int) - 1);
- printf("\n");
- }
2、数组排序后,与原数组求最长公共子序列
这个方法还是非常巧妙的,因为LIS是单调递增的性质,所以任意一个LIS一定跟排序后的序列有最长公共子序列,并且就是LIS本身。不过这里还没有提到最长公共子序列,可以先移步下一节,看完后再回来看这个方法的代码,代码如下:
- #include
- using namespace std;
- /* 最长递增子序列 LIS
- * 设数组长度不超过 100
- * quicksort + LCS
- */
- void swap(int * arr, int i, int j)
- {
- int tmp = arr[i];
- arr[i] = arr[j];
- arr[j] = tmp;
- }
- void qsort(int * arr, int left, int right)
- {
- if(left >= right) return ;
- int index = left;
- for(int i = left+1; i <= right; ++i)
- {
- if(arr[i] < arr[left])
- {
- swap(arr,++index,i);
- }
- }
- swap(arr,index,left);
- qsort(arr,left,index-1);
- qsort(arr,index+1,right);
- }
- int dp[101][101];
- int LCS(int * arr, int * arrcopy, int len)
- {
- for(int i = 1; i <= len; ++i)
- {
- for(int j = 1; j <= len; ++j)
- {
- if(arr[i-1] == arrcopy[j-1])
- {
- dp[i][j] = dp[i-1][j-1] + 1;
- }else if(dp[i-1][j] > dp[i][j-1])
- {
- dp[i][j] = dp[i-1][j];
- }else
- {
- dp[i][j] = dp[i][j-1];
- }
- }
- }
- return dp[len][len];
- }
- void main()
- {
- int arr[] = {1,-1,2,-3,4,-5,6,-7};
- int arrcopy [sizeof(arr)/sizeof(int)];
- memcpy(arrcopy,arr,sizeof(arr));
- qsort(arrcopy,0,sizeof(arr)/sizeof(int)-1);
- /* 计算LCS,即LIS长度 */
- int len = sizeof(arr)/sizeof(int);
- printf("%d\n",LCS(arr,arrcopy,len));
- }
3、动态规划和二分查找结合
我们期望在前i个元素中的所有长度为len的递增子序列中找到这样一个序列,它的最大元素比arr[i+1]小,而且长度要尽量的长,如此,我们只需记录len长度的递增子序列中最大元素的最小值就能使得将来的递增子序列尽量地长。
在这里我们维护一个数组MaxV[i],记录长度为i的递增子序列中最大元素的最小值,并对于数组中的每个元素考察其是哪个子序列的最大元素,二分更新MaxV数组,最终i的值便是最长递增子序列的长度。这个方法真是太巧妙了,妙不可言。
具体代码如下:
- #include
- using namespace std;
- /* 最长递增子序列 LIS
- * 设数组长度不超过 30
- * DP + BinarySearch
- */
- int MaxV[30]; /* 存储长度i+1(len)的子序列最大元素的最小值 */
- int len; /* 存储子序列的最大长度 即MaxV当前的下标*/
- /* 返回MaxV[i]中刚刚大于x的那个元素的下标 */
- int BinSearch(int * MaxV, int size, int x)
- {
- int left = 0, right = size-1;
- while(left <= right)
- {
- int mid = (left + right) / 2;
- if(MaxV[mid] <= x)
- {
- left = mid + 1;
- }else
- {
- right = mid - 1;
- }
- }
- return left;
- }
- int LIS(int * arr, int size)
- {
- MaxV[0] = arr[0]; /* 初始化 */
- len = 1;
- for(int i = 1; i < size; ++i) /* 寻找arr[i]属于哪个长度LIS的最大元素 */
- {
- if(arr[i] > MaxV[len-1]) /* 大于最大的自然无需查找,否则二分查其位置 */
- {
- MaxV[len++] = arr[i];
- }else
- {
- int pos = BinSearch(MaxV,len,arr[i]);
- MaxV[pos] = arr[i];
- }
- }
- return len;
- }
- void main()
- {
- int arr[] = {1,-1,2,-3,4,-5,6,-7};
- /* 计算LIS长度 */
- printf("%d\n",LIS(arr,sizeof(arr)/sizeof(int)));
- }
三、最长公共子串(LCS)
回到最常见的字符串问题了,这里的找两个字符串的最长公共子串,要求在原字符串中是连续的。其实和上面两个问题一样,这里依旧可以用动态规划来求解,其实博主自己也不大擅长动态规划,但是可以仿照上面的思路来操作。我们采用一个二维矩阵来记录中间的结果。这个二维矩阵怎么构造呢?直接举个例子吧:"bab"和"caba",则数组如下:
b a b
c 0 0 0
a 0 1 0
b 1 0 1
a 0 1 0
我们看矩阵的斜对角线最长的那个就是我们找的最长公共子串。
那怎么求最长的由1组成的斜对角线呢?可以做这样的操作:当要在矩阵是填1时让它等于其左上角元素加1。
b a b
c 0 0 0
a 0 1 0
b 1 0 2
a 0 2 0
这样矩阵中的最大元素就是 最长公共子串的长度。
在构造这个二维矩阵的过程中由于得出矩阵的某一行后其上一行就没用了,所以实际上在程序中可以用一维数组来代替这个矩阵(这样空间复杂度就降低了哈)。
代码如下:
- #include
- #include
- #include
- using namespace std;
- //str1为横向,str2这纵向
- const string LCS(const string& str1,const string& str2){
- int xlen=str1.size(); //横向长度
- vector<int> tmp(xlen); //保存矩阵的上一行
- vector<int> arr(tmp); //当前行
- int ylen=str2.size(); //纵向长度
- int maxele=0; //矩阵元素中的最大值
- int pos=0; //矩阵元素最大值出现在第几列
- for(int i=0;i
- string s=str2.substr(i,1);
- arr.assign(xlen,0); //数组清0
- for(int j=0;j
- if(str1.compare(j,1,s)==0){
- if(j==0)
- arr[j]=1;
- else
- arr[j]=tmp[j-1]+1;
- if(arr[j]>maxele){
- maxele=arr[j];
- pos=j;
- }
- }
- }
- tmp.assign(arr.begin(),arr.end());
- }
- string res=str1.substr(pos-maxele+1,maxele);
- return res;
- }
- int main(){
- string str1("21232523311324");
- string str2("312123223445");
- string lcs=LCS(str1,str2);
- cout<
- return 0;
- }
四、最长公共子序列
这才是笔试面试中出现频度最高的问题,前面提到了一个最长公共子串,这里的最长公共子序列与它的区别在于最长公共子序列不要求在原字符串中是连续的,比如ADEFG和ABCDEG的最长公共子序列是ADEG。
1)递归方法求解
这个地方可能最容易想到的方法就是递归处理了,设有字符串a[0...n],b[0...m],则易知当数组a的i位置上和b的j位置上对应位相同时,则直接求解两个串从下一个位置开始的剩下部分的最长公共子序列即可;当不同时,则求a[i+1...n]、b[j...m]和a[i...n]、b[j+1...m]两种情况中的较大数值即可,用公式表示如下:

代码如下:
- #include
- #include
- char a[100],b[100];
- int lena,lenb;
- int LCS(int,int);///两个参数分别表示数组a的下标和数组b的下标
- int main()
- {
- strcpy(a,"ABCBDAB");
- strcpy(b,"BDCABA");
- lena=strlen(a);
- lenb=strlen(b);
- printf("%d\n",LCS(0,0));
- return 0;
- }
- int LCS(int i,int j)
- {
- if(i>=lena || j>=lenb)
- return 0;
- if(a[i]==b[j])
- return 1+LCS(i+1,j+1);
- else
- return LCS(i+1,j)>LCS(i,j+1)? LCS(i+1,j):LCS(i,j+1);
- }
这种处理方法优点是编程简单,非常容易理解。缺点是效率太低了,有大量的重复执行递归调用,一般情况下面试官是不会满意的。另一个致命的缺点是只能求出最大公共子序列的长度,求不出具体的最大公共子序列,而在大部分笔试或者面试时会要求我们求出具体的最大公共子序列。
2)动态规划
这里依旧可以采用动态规划的方法来解决这个问题,可以借助一个二维数组来标识中间计算结果,避免重复的计算来提高效率,可能需要消耗一部分空间,但是时间复杂度大大降低。
如下图所示的两个串,求解最长公共子序列的过程很明了:
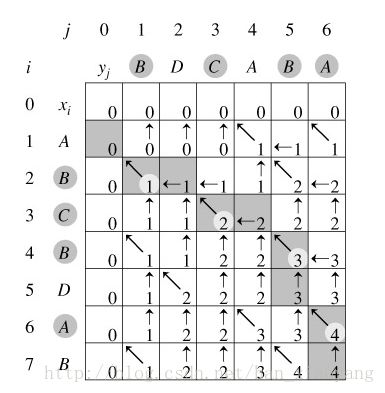
设有字符串a[0...n],b[0...m],字符串a对应的是二维数组num的行,字符串b对应的是二维数组num的列。我们有以下的递推公式:

我们在程序中,可以使用二维数组flag来记录下标i和j的走向。数字"1"表示,斜向下;数字"2"表示,水平向右;数字"3"表示,竖直向下。这样我们可以求解出行进的路径,从而得到最长公共子序列。代码如下:
- #include
- #include
- char a[500],b[500];
- char num[501][501]; ///记录中间结果的数组
- char flag[501][501]; ///标记数组,用于标识下标的走向,构造出公共子序列
- void LCS(); ///动态规划求解
- void getLCS(); ///采用倒推方式求最长公共子序列
- int main()
- {
- int i;
- strcpy(a,"ABCBDAB");
- strcpy(b,"BDCABA");
- memset(num,0,sizeof(num));
- memset(flag,0,sizeof(flag));
- LCS();
- printf("%d\n",num[strlen(a)][strlen(b)]);
- getLCS();
- return 0;
- }
- void LCS()
- {
- int i,j;
- for(i=1;i<=strlen(a);i++)
- {
- for(j=1;j<=strlen(b);j++)
- {
- if(a[i-1]==b[j-1]) ///注意这里的下标是i-1与j-1
- {
- num[i][j]=num[i-1][j-1]+1;
- flag[i][j]=1; ///斜向下标记
- }
- else if(num[i][j-1]>num[i-1][j])
- {
- num[i][j]=num[i][j-1];
- flag[i][j]=2; ///向右标记
- }
- else
- {
- num[i][j]=num[i-1][j];
- flag[i][j]=3; ///向下标记
- }
- }
- }
- }
- void getLCS()
- {
- char res[500];
- int i=strlen(a);
- int j=strlen(b);
- int k=0; ///用于保存结果的数组标志位
- while(i>0 && j>0)
- {
- if(flag[i][j]==1) ///如果是斜向下标记
- {
- res[k]=a[i-1];
- k++;
- i--;
- j--;
- }
- else if(flag[i][j]==2) ///如果是斜向右标记
- j--;
- else if(flag[i][j]==3) ///如果是斜向下标记
- i--;
- }
- for(i=k-1;i>=0;i--)
- printf("%c",res[i]);
- }
五、字符串编辑距离
给定一个源字符串和目标字符串,能够对源串进行如下操作:
1.在给定位置上插入一个字符
2.替换任意字符
3.删除任意字符
求通过以上操作使得源字符串和目标字符串一致的最小操作步数。
简单描述一下解该题的思想,源字符串和目标字符串分别为str_a、str_b,二者的长度分别为la、lb,定义f[i,j]为子串str_a[0...i]和str_b[0...j]的最小编辑距离,简单分析可知求得的str_a[0...i]和str_b[0...j]的最小编辑距离有一下三种可能:
(1)去掉str_a[0...i]的最后一个字符跟str_b[0...j]匹配,则f[i, j]的值等于f[i-1, j]+1;
(2)去掉str_b[0...j]的最后一个字符跟str_a[0...i]匹配,则f[i, j]的值等于f[i, j-1]+1;
(3)去掉str_a[0...i]和str_b[0...j]的最后一个字符,让二者匹配求得f[i-1, j-1],计算f[i, j]时要考虑当前字符是否相等,如果str_a[i]==str_b[j]说明该字符不用编辑,所以f[i, j]的值等于f[i-1, j-1],如果str_a[i]!=str_b[j]说明该字符需要编辑一次(任意修改str_a[i]或者str_b[j]即可),所以f[i, j]的值等于f[i-1, j-1]+1。
因为题目要求的是最小的编辑距离,所以去上面上中情况中的最小值即可,因此可以得到递推公式:
f[i, j] = Min ( f[i-1, j]+1, f[i, j-1]+1, f[i-1, j-1]+(str_a[i]==str_b[j] ? 0 : 1) )
维基百科中的描述如下:

1)递归方法(用到动态规划)
由上述的递归公式可以有以下代码:
- //求两个字符串的编辑距离问题
- //递归版本,备忘录C[i,j]表示strA[i]...strA[size_A-1]与strB[j]...strB[size_B-1]的编辑距离
- int editDistance_mem(char *strA,int size_A,char *strB,int size_B){
- int **C=new int*[size_A+1];
- for(int i=0;i<=size_A;i++){
- C[i]=new int[size_B+1]();
- }
- //初始化
- for(int i=0;i<=size_A;i++){
- for(int j=0;j<=size_B;j++)
- C[i][j]=INT_MAX;
- }
- int res=EDM(C,strA,0,size_A-1,strB,0,size_B-1);
- //free mem
- for(int i=0;i<=size_A;i++){
- delete [] C[i];
- }
- delete [] C;
- return res;
- }
- int EDM(int **C,char *strA,int i,int A_end,char *strB,int j,int B_end){
- if(C[i][j]
- return C[i][j];
- if(i>A_end){
- if(j>B_end)
- C[i][j]=0;
- else
- C[i][j]=B_end-j+1;
- }else if(j>B_end){
- if(i>A_end)
- C[i][j]=0;
- else
- C[i][j]=A_end-i+1;
- }
- else if(strA[i]==strB[j])
- C[i][j]=EDM(C,strA,i+1,A_end,strB,j+1,B_end);
- else{
- int a=EDM(C,strA,i+1,A_end,strB,j+1,B_end);
- int b=EDM(C,strA,i,A_end,strB,j+1,B_end);
- int c=EDM(C,strA,i+1,A_end,strB,j,B_end);
- C[i][j]=min(a,b,c)+1;
- }
- return C[i][j];
- }
2)矩阵标记法
递推方法(也可称为矩阵标记法),通过分析可知可以将f[i, j]的计算在一个二维矩阵中进行,上面的递推式实际上可以看做是矩阵单元的计算递推式,只要把矩阵填满了,f[la-1, lb-1]的值就是要求得最小编辑距离。代码如下:
- //求两个字符串的编辑距离问题
- //递推版本 C[i,j]表示strA[i]...strA[size_A-1]与strB[j]...strB[size_B-1]的编辑距离
- int editDistance_iter(char *strA,int size_A,char *strB,int size_B){
- int **C=new int*[size_A+1];
- for(int i=0;i<=size_A;i++){
- C[i]=new int[size_B+1]();
- }
- for(int i=size_A;i>=0;i--){
- for(int j=size_B;j>=0;j--){
- if(i>size_A-1){
- if(j>size_B-1)
- C[i][j]=0;
- else
- C[i][j]=size_B-j;
- }else if(j>size_B-1){
- if(i>size_A-1)
- C[i][j]=0;
- else
- C[i][j]=size_A-i;
- }else if(strA[i]==strB[j])
- C[i][j]=C[i+1][j+1];
- else
- C[i][j]=min(C[i+1][j+1],C[i+1][j],C[i][j+1])+1;
- }
- }
- int res=C[0][0];
- //free mem
- for(int i=0;i<=size_A;i++){
- delete [] C[i];
- }
- delete [] C;
- return res;
- }
六、最长不重复子串
很好理解,即求一个串内最长的不重复子串。
1)使用Hash
要求子串中的字符不能重复,判重问题首先想到的就是hash,寻找满足要求的子串,最直接的方法就是遍历每个字符起始的子串,辅助hash,寻求最长的不重复子串,由于要遍历每个子串故复杂度为O(n^2),n为字符串的长度,辅助的空间为常数hash[256]。代码如下:
- /* 最长不重复子串 我们记为 LNRS */
- int maxlen;
- int maxindex;
- void output(char * arr);
- /* LNRS 基本算法 hash */
- char visit[256];
- void LNRS_hash(char * arr, int size)
- {
- for(int i = 0; i < size; ++i)
- {
- memset(visit,0,sizeof(visit));
- visit[arr[i]] = 1;
- for(int j = i+1; j < size; ++j)
- {
- if(visit[arr[j]] == 0)
- {
- visit[arr[j]] = 1;
- }
- else
- {
- if(j-i > maxlen)
- {
- maxlen = j - i;
- maxindex = i;
- }
- break;
- }
- }
- }
- output(arr);
- }
2)动态规划法
字符串的问题,很多都可以用动态规划处理,比如这里求解最长不重复子串,和前面讨论过的最长递增子序列问题就有些类似,在LIS(最长递增子序列)问题中,对于当前的元素,要么是与前面的LIS构成新的最长递增子序列,要么就是与前面稍短的子序列构成新的子序列或单独构成新子序列。
这里我们采用类似的思路:某个当前的字符,如果它与前面的最长不重复子串中的字符没有重复,那么就可以以它为结尾构成新的最长子串;如果有重复,那么就与某个稍短的子串构成新的子串或者单独成一个新子串。
我们来看看下面两个例子:
1)字符串“abcdeab”,第二个a之前的最长不重复子串是“abcde”,a与最长子串中的字符有重复,但是它与稍短的“bcde”串没有重复,于是它可以与其构成一个新的子串,之前的最长不重复子串“abcde”结束;
2)字符串“abcb”,跟前面类似,最长串“abc”结束,第二个字符b与稍短的串“c”构成新的串;
我们貌似可以总结出一些东西:当一个最长子串结束时(即遇到重复的字符),新的子串的长度是与(第一个重复的字符)的下标有关的。
于是类似LIS,对于每个当前的元素,我们“回头”去查询是否有与之重复的,如没有,则最长不重复子串长度+1,如有,则是与第一个重复的字符之后的串构成新的最长不重复子串,新串的长度便是当前元素下标与重复元素下标之差。
可以看出这里的动态规划方法时间复杂度为O(N^2),我们可以与最长递增子序列的动态规划方案进行对比,是一个道理的。代码如下:
- /* LNRS 动态规划求解 */
- int dp[100];
- void LNRS_dp(char * arr, int size)
- {
- int i, j;
- maxlen = maxindex = 0;
- dp[0] = 1;
- for(i = 1; i < size; ++i)
- {
- for(j = i-1; j >= 0; --j)
- {
- if(arr[j] == arr[i])
- {
- dp[i] = i - j;
- break;
- }
- }
- if(j == -1)
- {
- dp[i] = dp[i-1] + 1;
- }
- if(dp[i] > maxlen)
- {
- maxlen = dp[i];
- maxindex = i + 1 - maxlen;
- }
- }
- output(arr);
- }
3)动态规划和hash结合
我们发现在动态规划方法中,每次都要“回头”去寻找重复元素的位置,所以时间复杂度徒增到O(n^2),结合方法1)中的Hash思路,我们可以用hash记录元素是否出现过,我们当然也可以用hash记录元素出现过的下标,,这样就不必“回头”了,而时间复杂度必然降为O(N),只不过需要一个辅助的常数空间visit[256],这也是之前我另外一篇文章找工作笔试面试那些事儿(15)---互联网公司面试的零零种种和多家经验提到的的空间换时间思路,不过一般我们的面试里面优先考虑时间复杂度,所以这是可取的方法。
- /* LNRS 动态规划 + hash 记录下标 */
- void LNRS_dp_hash(char * arr, int size)
- {
- memset(visit, -1, sizeof visit); //visit数组是-1的时候代表这个字符没有在集合中
- memset(dp, 0, sizeof dp);
- maxlen = maxindex = 0;
- dp[0] = 1;
- visit[arr[0]] = 0;
- for(int i = 1; i < size; ++i)
- {
- if(visit[arr[i]] == -1) //表示arr[i]这个字符以前不存在
- {
- dp[i] = dp[i-1] + 1;
- visit[arr[i]] = i; /* 记录字符下标 */
- }else
- {
- dp[i] = i - visit[arr[i]];
- visit[arr[i]] = i; /* 更新字符下标 */
- }
- if(dp[i] > maxlen)
- {
- maxlen = dp[i];
- maxindex = i + 1 - maxlen;
- }
- }
- output(arr);
- }
4)空间再优化
上面的方法3)已经将时间复杂度降到了O(n),可是这时面试官又发言了,说你用的辅助空间多了,还有优化方法吗,我们仔细观察动态规划最优子问题解的更新方程:
dp[i] = dp[i-1] + 1;
dp[i-1]不就是更新dp[i]当前的最优解么?这又与之前提到的最大子数组和问题的优化几乎同出一辙,我们不需要O(n)的辅助空间去存储子问题的最优解,而只需O(1)的空间就可以了,至此,我们找到了时间复杂度O(N),辅助空间为O(1)(一个额外变量与256大小的散列表)的算法,代码如下:
- /* LNRS 动态规划+hash,时间复杂度O(n) 空间复杂度O(1)算法*/
- void LNRS_dp_hash_ultimate(char * arr, int size)
- {
- memset(visit, -1, sizeof visit);
- maxlen = maxindex = 0;
- visit[arr[0]] = 0;
- int curlen = 1;
- for(int i = 1; i < size; ++i)
- {
- if(visit[arr[i]] == -1)
- {
- ++curlen;
- visit[arr[i]] = i; /* 记录字符下标 */
- }
- else
- {
- curlen = i - visit[arr[i]];
- visit[arr[i]] = i; /* 更新字符下标 */
- }
- if(curlen > maxlen)
- {
- maxlen = curlen;
- maxindex = i + 1 - maxlen;
- }
- }
- output(arr);
- }
七、最长回文子串
给出一个字符串S,找到一个最长的连续回文串。例如串 babcbabcbaccba 最长回文是:abcbabcba
1)自中心向两端寻找
回文是一种特殊的字符串,我们可以以源字符串的每个字符为中心,依次寻找出最长回文子串P0, P1,...,Pn。这些最长回文子串中的最长串Pi = max(P1, P2,...,Pn)即为所求。核心代码如下:
- string find_lps_method1(const string &str)
- {
- int center = 0, max_len = 0;
- for(int i = 1; i < str.length()-1; ++i)
- {
- int j = 1;
- //以str[i]为中心,依次向两边扩展,寻找最长回文Pi
- while(i+j < str.length() && i-j >= 0 && str[i+j] == str[i-j])
- ++j;
- --j;
- if(j > 1 && j > max_len)
- {
- center = i;
- max_len = j;
- }
- }
- return str.substr(center-max_len, (max_len << 1) + 1);
- }
2)利用最长公共字串的方法
这里用到了一个我们观察出来的结论:对于串S, 假设它反转后得到的串是S', 那么S的最长回文串是S和S'的最长公共字串。
例如 S = babcbabcbaccba, S' = abccabcbabcbab,S和S'的最长公共字串是 abcbabcba也是S的最长回文字串。
代码这个地方就不写了,用首指针++,尾指针--很容易实现串的翻转,再结合前面写过的最长公共子串代码可得到最后结果。
3)利用栈的性质
这是一个不成熟的想法,博主只是觉得比较好的想法需要拿出来分享一下,对于长度为偶数的最长回文,可以采用这样一种思路求得:
将字符串中的字符从左至右逐个入栈,出现情况:1)若栈顶字符和要入栈的字符相同,则该字符不入栈且栈pop出栈顶字符,回文长度加一。2)若栈顶字符与要入栈的字符不相同,直接入栈。则依次入栈出栈,求最长连续出栈序列即可。
因为对于奇数长度的字符串,博主没有想到时间复杂度低的类似处理方法,所以这里就不写代码了,大家有好的解法或者思路欢迎留言。
4)著名的Manacher’s Algorithm算法
算法首先将输入字符串S, 转换成一个特殊字符串T,转换的原则就是将S的开头结尾以及每两个相邻的字符之间加入一个特殊的字符,例如#
例如: S = “abaaba”, T = “#a#b#a#a#b#a#”.
为了找到最长的回文字串,例如我们当前考虑以Ti为回文串中间的元素,如果要找到最长回文字串,我们要从当前的Ti扩展使得 Ti-d … Ti+d 组成最长回文字串. 这里d其实和 以Ti为中心的回文串长度是一样的. 进一步解释就是说,因为我们这里插入了 # 符号,对于一个长度为偶数的回文串,他应该是以#做为中心的,然后向两边扩,对于长度是奇数的回文串,它应该是以一个普通字符作为中心的。通过使用#,我们将无论是奇数还是偶数的回文串,都变成了一个以Ti为中心,d为半径两个方向扩展的问题。并且d就是回文串的长度。
例如 #a#b#a#, P = 0103010, 对于b而言P的值是3,是最左边的#,也是延伸的最左边。这个值和当前的回文串是一致的。
如果我们求出所有的P值,那么显然我们要的回文串,就是以最大P值为中心的回文串。
T = # a # b # a # a # b # a #
P = 0 1 0 3 0 1 6 1 0 3 0 1 0
例如上面的例子,最长回文是 “abaaba”, P6 = 6.
根据观察发现,如果我们在一个位置例如 abaaba的中间位置,用一个竖线分开,两侧的P值是对称的。当然这个性质不是在任何时候都会成立,接下来就是分析如何利用这个性质,使得我们可以少算很多P的值。
下面的例子 S = “babcbabcbaccba” 存在更多的折叠回文字串。

C表示当前的回文中心,L和R处的线表示以C为中心可以到达的最左和最右位置,如果知道这些,我们如何可以更好的计算C后面的P[i].
假设我们当前计算的是 i = 13, 根据对称性,我们知道对称的那个下标 i' = 9.

根据C对称的原则,我们很容易得到如下数据 P[ 12 ] = P[ 10 ] = 0, P[ 13 ] = P[ 9 ] = 1, P[ 14 ] = P[ 8 ] = 0).

当时当i = 15的时候,却只能得到回文 “a#b#c#b#a”, 长度是5, 而对称 i ' = 7 的长度是7.

如上图所示,如果以 i, i' 为中心,画出对称的区域如图,其中以i‘ = 7 对称的区域是 实心绿色 + 虚绿色 和 左侧,虚绿色表示当前的对称长度已经超过之前的对称中心C。而之前的P对称性质成立的原因是 i 右侧剩余的长度 R - i 正好比 以 i‘ 为中心的回文小。
这个性质可以这样归纳,对于 i 而言,因为根据C对称的最右是R,所以i的右侧有 R - i 个元素是保证是 i' 左侧是对称的。 而对于 i' 而言他的P值,也就是回文串的长度,可能会比 R-i 要大。 如果大于 R - i, 对于i而言,我们只能暂时的先填写 P[i] = R - i, 然后依据回文的属性来扩充P[i] 的值; 如果P[i '] 小于R-i,那么说明在对称区间C内,i的回文串长度和i' 是一样长的。例如我们的例子中 i = 15, 因为R = 20,所以i右侧 在对称区间剩余的是 R - 15 = 5, 而 i’ = 7 的长度是7. 说明 i' 的回文长度已经超出对称区间。我们只能使得P[i] 赋值为5, 然后尝试扩充P[i].
if P[ i' ] ≤ R – i,
then P[ i ] ← P[ i' ]
else P[ i ] ≥R – i. (这里下一步操作是扩充 P[ i ].
扩充P[i] 之后,我们还要做一件事情是更新 R 和 C, 如果当前对称中心的最右延伸大于R,我们就更新C和R。在迭代的过程中,我们试探i的时候,如果P[i'] <= R - i, 那么只要做一件事情。 如果不成立我们对当前P[i] 做扩展,因为最大长度是n,扩展最多就做n次,所以最多做2*n。 所以最后算法复杂度是 O(n)
具体实现的代码如下:
-
- // 转换S 到 T.
- // 例如, S = "abba", T = "^#a#b#b#a#$".
- // ^ 和 $ 作为哨兵标记加到两端以避免边界检查
- string preProcess(string s) {
- int n = s.length();
- if (n == 0) return "^$";
- string ret = "^";
- for (int i = 0; i < n; i++)
- ret += "#" + s.substr(i, 1);
- ret += "#$";
- return ret;
- }
- string longestPalindrome(string s) {
- string T = preProcess(s);
- int n = T.length();
- int *P = new int[n];
- int C = 0, R = 0;
- for (int i = 1; i < n-1; i++) {
- int i_mirror = 2*C-i; // equals to i' = C - (i-C)
- P[i] = (R > i) ? min(R-i, P[i_mirror]) : 0;
- // Attempt to expand palindrome centered at i
- while (T[i + 1 + P[i]] == T[i - 1 - P[i]])
- P[i]++;
- // If palindrome centered at i expand past R,
- // adjust center based on expanded palindrome.
- if (i + P[i] > R) {
- C = i;
- R = i + P[i];
- }
- }
- // Find the maximum element in P.
- int maxLen = 0;
- int centerIndex = 0;
- for (int i = 1; i < n-1; i++) {
- if (P[i] > maxLen) {
- maxLen = P[i];
- centerIndex = i;
- }
- }
- delete[] P;
- return s.substr((centerIndex - 1 - maxLen)/2, maxLen);
- }