mysql-事务(1)实现原理简述
事务实现原理
- 事务实现原理
- a. 原子性实现原理 undolog
- c.一致性实现原理
- i.隔离性实现原理 读写锁+mvcc
- d. 持久性实现原理 redo log
- last番外篇
- 一、数据库并发现象和隔离级别如何进行测试
- 二、数据库锁
事务实现原理
1 原子性通过undo log 实现的
2 持久性通过redo log 实现
3 隔离性通过 读写锁+mvcc(并发控制) 实现的
4 一致性通过原子性,隔离性,持久性 来实现。
a. 原子性实现原理 undolog
原子性实现原理:在操作数据之前,将数据备份到undo log ,然后进行修改,当发生异常或者用户执行rollback语句,系统通过undo log将数据恢复到事务开始之前的数据状态,即 undo log是逻辑日志,事务通过它来实现其原子性。
c.一致性实现原理
一致性实现原理由事务的原子性,隔离性,持久性来实现。
i.隔离性实现原理 读写锁+mvcc
事务具有隔离性,理论上来说事务并行执行不应相互之间产生影响,也就是并行执行和串行执行在数据库中产生的结果是一样的。但完全的隔离性会降低系统并发性能,从而降低资源利用率,所以实际当中会适当放宽隔离性,那么数据一致性也会在一定程度上有所降低。
锁的并发控制流程图:
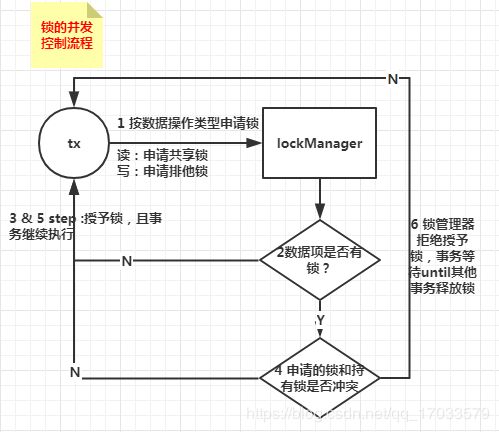
可能出现死锁:多个事务持有锁循环等待其他事务的锁导致所有事物都无法继续执行。
原理:
1 利用mvcc【多版本并发控制】实现了一致性非锁定读,在一个事务里多次读取的结果是一样的,解决了不可重复读的问题
2 gap locks(间隙锁,即在索引记录之间加锁)和 next-key locks(在索引记录上加锁并且在索引记录间隙之前加锁):在锁定区间不允许插入数据,解决了幻读的问题。
具体可参看文档:隔离性实现原理
数据库并发三种现象:
脏读:a事务读取了b事务修改未提交的数据,b事务回滚了,那事务1读到的数据就是脏数据。
不可重复读:a事务读取了某一数据,b事务更改并提交了这个数据,a事务再次读该数据为b事务更改后的数据,a事务在b事务更改同一数据前后不一致,这种并发现象是不可重复读。解决不可重复读的问题只需锁行
幻读:读多/少了,a事务查询列表数据前后两次中,数据库最大id都是10。但是b事务在a事务两次查询期间做了新增并提交的操作,id实际最大为11,a事务在b事务写操作之后,a事务第二次读最大id仍为10(避免了不可重复读),所以a事务同样也新增一个id为11的记录,执行提交时,报错: duplicate entry ‘11’ for key ‘primary’ ,意思已经有id=11的记录了,但是a明明查到的数据id最大为10啊,仿佛产生了幻觉。
对应事务有4个隔离级别来避免并发:
1 读未提交read uncommitted:(a修改数据还未提交时,b来查表,查到的是a未提交的更新数据,a有事回滚了,b读到的就是脏数据)
2 读已提交read committed:(解决了脏读问题,但出现了不可重复读的问题),
4可以重复读repeatable read:(解决不可重复读:同一个事务里的不管多多少次,结果都是一样的)
8串行化serializable:(事务隔离级别为串行化时,读写数据都会锁住整张表,因此不会出现读多读少的情况,解决了幻读,不可重复读,脏读)性能开销大,执行效率非常差。
d. 持久性实现原理 redo log
redolog是将新数据备份,在事务提交之前,只需将redo log持久化即可,发生系统崩溃时,系统通过redo log将数据恢复到最新状态。
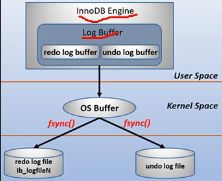
数据持久化不是直接到磁盘,而是先到内核,然后通过os buffer调用fsync()将数据刷到磁盘,在做持久化的时候有3种方式设置(第2种方式最慢):
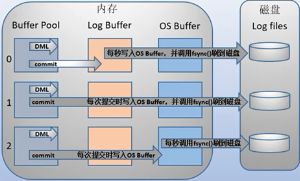
持久化过程如下:
last番外篇
一、数据库并发现象和隔离级别如何进行测试
如果想看具体并发现象,事务隔离级别可参看test-demo
也可以通过下面设置,自己主动测试下
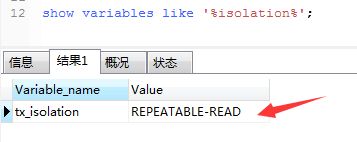
1 、查看事务隔离级别show variables like '%isolation%';下图看见mysql数据库默认隔离级别是4 ,可以重复读。
2、设置事务隔离级别eg:set session transation isolation level REPEATABLE READ 测试事务隔离级别的时候会用到。
mysql> help ISOLATION
Name: 'ISOLATION'
Description:
Syntax:
SET [GLOBAL | SESSION] TRANSACTION ISOLATION LEVEL
{
REPEATABLE READ
| READ COMMITTED
| READ UNCOMMITTED
| SERIALIZABLE
}
3、查询是否自动提交select @@autocommit
测试回显并发显现需要将自动提交关闭:set autocommit=0 ;
4、也可以在每个会话里分别重新开一个事务:start transaction;
二、数据库锁
1、数据库锁粒度 3个:行锁,表锁,数据库,锁粒度越小,效率越高,出现问题的概率增大,如果锁的粒度越大,效率就越低,也就越安全。
2、数据库锁分为两类:
共享锁:将数据锁定为只读形式,不能更新,也成为读取锁定。
1、锁定读
在一个事务中,标准的SELECT语句是不会加锁,但是有两种情况例外。SELECT … LOCK IN SHARE MODE 和 SELECT … FOR UPDATE。
SELECT … LOCK IN SHARE MODE
给记录假设共享锁,这样一来的话,其它事务只能读不能修改,直到当前事务提交
SELECT … FOR UPDATE
给索引记录加排他锁,这种情况下跟UPDATE的加锁情况是一样的
2、一致性非锁定读
consistent read (一致性读),InnoDB用多版本来提供查询数据库在某个时间点的快照。如果隔离级别是REPEATABLE READ,那么在同一个事务中的所有一致性读都读的是事务中第一个这样的读读到的快照;如果是READ COMMITTED,那么一个事务中的每一个一致性读都会读到它自己刷新的快照版本。Consistent read(一致性读)是READ COMMITTED和REPEATABLE READ隔离级别下普通SELECT语句默认的模式。一致性读不会给它所访问的表加任何形式的锁,因此其它事务可以同时并发的修改它们。
排它锁:数据进行写操作的时候,其他事务不能做读取数据,也成为写入锁定。
2.1、下面三种锁要了解一下:
Record Locks(记录锁):在索引记录上加锁。
Gap Locks(间隙锁):在索引记录之间加锁,或者在第一个索引记录之前加锁,或者在最后一个索引记录之后加锁。
Next-Key Locks:在索引记录上加锁,并且在索引记录之前的间隙加锁。它相当于是Record Locks与Gap Locks的一个结合。
假设一个索引包含以下几个值:10,11,13,20。那么这个索引的next-key锁将会覆盖以下区间:
(negative infinity, 10]
(10, 11]
(11, 13]
(13, 20]
(20, positive infinity)
innoDb存储引擎默认都是加的行锁
3、快照读和当前读
快照读:读取的是快照版本,也就是历史版本
当前读:读取的是最新版本
普通的SELECT就是快照读,当前读:UPDATE、DELETE、INSERT、SELECT … LOCK IN SHARE MODE、SELECT … FOR UPDATE。
4、并发控制策略:
基于锁的并发控制
基于时间戳的并发控制
基于有效性检查的并发控制
基于快照隔离的并发控制
5、数据库默认隔离级别
mysql支持1248这四种隔离级别,默认可以重复读。
Oracle数据库支持READ COMMITTED 和 SERIALIZABLE这两种事务隔离级别。所以Oracle不支持脏读
SQL标准所定义的默认事务隔离级别是SERIALIZABLE,但是Oracle 默认使用的是READ COMMITTED