数据库:mysql:备份与恢复
一、概述
1. 备份分类
这里需要理解数据库备份的一致性,这种备份要求在备份的时候数据在这一时间点上是一致的。举例来说,在一个网络游戏中有一个玩家购买了道具,这个事务的过程是:先扣除相应的金钱,然后向其装备表中插入道具,确保扣费和得到道具是互相一致的。否则,在恢复时,可能出现金钱被扣除了而装备丢失的问题。
(1) 按备份的方法不同划分:
- Hot Backup(热备):是指数据库运行中直接备份,对正在运行的数据库操作没有任何的影响。这种方式在MySQL官方手册中称为Online Backup(在线备份)
- Cold Backup(冷备):是指备份操作是在数据库停止的情况下,这种备份最为简单,一般只需要复制相关的数据库物理文件即可。这种方式在MySQL官方手册中称为Offline Backup(离线备份)
- Warm Backup(温备):是在数据库运行中进行的,但是会对当前数据库的操作有所影响,如加一个全局读锁以保证备份数据的一致性。
(2) 按照备份文件的内容划分:
*逻辑备份:是指备份出的文件内容是可读的,一般是文本文件。内容一般是由一条条SQL语句,或者是表内实际数据组成
- 裸文件备份:是指复制数据库的物理文件,既可以是在数据库运行中的复制(如ibbackup、xtrabackup这类工具),也可以是在数据库停止运行时直接的数据文件复制
逻辑备份: 这类方法的好处是可以观察导出文件的内容,一般适用于数据库的升级、迁移等工作。但其缺点是恢复所需要的时间往往较长。
裸文件备份:这类备份的恢复时间往往较逻辑备份短很多。
(3) 按照备份数据库的内容划分:
- 完全备份:是指对数据库进行一个完整的备份
- 增量备份: 是指在上次完全备份的基础上,对于更改的数据进行备份
- 日志备份:是指对MySQL数据库二进制日志的备份,通过对一个完全备份进行二进制日志的重做(replay)来完成数据库的point-in-time的恢复工作
注意:MySQL数据库复制(replication)的原理就是异步实时地将二进制日志重做传送并应用到从(slave/standby)数据库。
二、冷备
1. 备份方式
对于InnoDB存储引擎的冷备非常简单,只需要备份MySQL数据库的frm文件,共享表空间文件,独立表空间文件(*.ibd),重做日志文件。另外建议定期备份MySQL数据库的配置文件my.cnf,这样有利于恢复的操作。
2. 优缺点
冷备的优点是:
- 备份简单,只要复制相关文件即可。
- 备份文件易于在不同操作系统,不同MySQL版本上进行恢复。
- 恢复相当简单,只需要把文件恢复到指定位置即可。
- 恢复速度快,不需要执行任何SQL语句,也不需要重建索引。
冷备的缺点是:
- InnoDB存储引擎冷备的文件通常比逻辑文件大很多,因为表空间中存放着很多其他的数据,如undo段,插入缓冲等信息。
- 冷备也不总是可以轻易地跨平台。操作系统、MySQL的版本、文件大小写敏感和浮点数格式都会成为问题。
三、逻辑备份
逻辑备份方式
1. mysqldump
(1) 作用
用来完成转存(dump)数据库的备份及不同数据库之间的移植,如从MySQL低版本数据库升级到MySQL高版本数据库,又或者从MySQL数据库移植到Oracle、Microsoft SQL Server数据库等。
(2) 注意事项
mysqldump备份工具来说,可以通过添加–single-transaction选项获得InnoDB存储引擎的一致性备份。对于InnoDB存储引擎的备份,务必加上–single-transaction的选项。
(3) 相关命令
mysqldump --help 查看。
mysqldump的语法如下:
shell>mysqldump -u root -p [arguments] >fle_name
这里列举一些比较重要的参数。
//如果想要备份所有的数据库,可以使用--all-databases选项:
shell > mysqldump -u root -p --all-databases >dump.sql
//如果想要备份指定的数据库,可以使用--databases选项:
shell > mysqldump -u root -p --databases db1 db2 db3 > dump.sql
//如果想要对test这个架构进行备份,可以使用如下语句(使用--single-transaction选项来保证备份的一致性):
shell > mysqldump -u root -p --single-transaction test > test_backup.sql
❑--single-transaction:在备份开始前,先执行START TRANSACTION命令,以此来获得备份的一致性,当前该参数只对InnoDB存储引擎有效。当启用该参数并进行备份时,确保没有其他任何的DDL语句执行,因为一致性读并不能隔离DDL操作。
❑--lock-tables(-l):在备份中,依次锁住每个架构下的所有表。一般用于MyISAM存储引擎,当备份时只能对数据库进行读取操作,不过备份依然可以保证一致性。对于InnoDB存储引擎,不需要使用该参数,用--single-transaction即可。并且--lock-tables和--single-transaction是互斥(exclusive)的,不能同时使用。如果用户的MySQL数据库中,既有MyISAM存储引擎的表,又有InnoDB存储引擎的表,那么这时用户的选择只有--lock-tables了。此外,正如前面所说的那样,--lock-tables选项是依次对每个架构中的表上锁的,因此只能保证每个架构下表备份的一致性,而不能保证所有架构下表的一致性。
❑--lock-all-tables(-x):在备份过程中,对所有架构中的所有表上锁。这个可以避免之前说的--lock-tables参数不能同时锁住所有表的问题。
❑--add-drop-database:在CREATE DATABASE前先运行DROP DATABASE。这个参数需要和--all-databases或者--databases选项一起使用。在默认情况下,导出的文本文件中并不会有CREATE DATABASE,除非指定了这个参数。
shell > mysqldump --single-transaction --add-drop-database --databases test > test_backup.sql
❑--master-data[=value]:通过该参数产生的备份转存文件主要用来建立一个replication。当value的值为1时,转存文件中记录CHANGE MASTER语句。当value的值为2时,CHANGE MASTER语句被写出SQL注释。在默认情况下,value的值为空。
❑--master-data会自动忽略--lock-tables选项。如果没有使用--single-transaction选项,则会自动使用--lock-all-tables选项。
shell > mysqldump --single-transaction --add-drop-database --master-data=1 --databases test > test_backup.sql
shell > mysqldump --single-transaction --add-drop-database --master-data=2 --databases test > test_backup.sql
❑--events(-E):备份事件调度器。
❑--routines(-R):备份存储过程和函数。
❑--triggers:备份触发器。
❑--hex-blob:将BINARY、VARBINARY、BLOG和BIT列类型备份为十六进制的格式。mysqldump导出的文件一般是文本文件,但是如果导出的数据中有上述这些类型,在文本文件模式下可能有些字符不可见,若添加--hex-blob选项,结果会以十六进制的方式显示。
shell > mysqldump --single-transaction --add-drop-database --master-data=2 --no-autocommit --databases test3 > test3_backup.sql
❑--tab=path(-T path):产生TAB分割的数据文件。对于每张表,mysqldump创建一个包含CREATE TABLE语句的table_name.sql文件,和包含数据的tbl_name.txt文件。可以使用--fields-terminated-by=...,--fields-enclosed-by=...,--fields-optionally-enclosed-by=...,--fields-escaped-by=...,--lines-terminated-by=...来改变默认的分割符、换行符等。
shell > mysqldump -u root -p --single-transaction --add-drop-database --tab="/var/lib/mysql-files/" learn
shell > cd /var/lib/mysql-files/
//learn.z表数据
shell > cat z.txt
1 1
3 1
7 6
10 8
//learn.z表结构
shell > cat z.sql
...
注意:导出若报错:mysqldump: Got error: 1290: The MySQL server is running with the --secure-file-priv option so it cannot execute this statement when executing 'SELECT INTO OUTFILE'
//导出路径用下面路径
mysql> show global variables like '%secure_file_priv%';
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
//我发现大多数DBA喜欢用SELECT...INTO OUTFILE的方式来导出一张表,但是通过mysqldump一样可以完成工作,而且可以一次完成多张表的导出,并且实现导出数据的一致性。
❑--where='where_condition'(-w'where_condition'):导出给定条件的数据
mysql> desc learn.z;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| a | int(11) | NO | PRI | NULL | |
| b | int(11) | YES | MUL | NULL | |
+-------+---------+------+-----+---------+-------+
mysql> select * from z;
+----+------+
| a | b |
+----+------+
| 1 | 1 |
| 3 | 1 |
| 7 | 6 |
| 10 | 8 |
+----+------+
shell > mysqldump -uroot -p --single-transaction --where='a>3' learn z > z.sql
2. SELECT … INTO OUTFILE
(1) 作用
SELECT … INTO语句也是一种逻辑备份的方法,更准确地说是导出一张表中的数据。
(2) 使用
mysql> select * from z;
+----+------+
| a | b |
+----+------+
| 7 | 6 |
| 10 | 8 |
+----+------+
mysql> show variables like 'secure_file_priv';
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
mysql> select * into outfile '/var/lib/mysql-files/z.txt' from learn.z;
shell > cat z.txt
7 6
10 8
//可以发现,默认导出的文件是以TAB进行列分割的,如果想要使用其他分割符,如“,”,则可以使用FIELDS TERMINATED BY'string'选项,如:
mysql> select * into outfile '/var/lib/mysql-files/z.txt' fields terminated by ',' from learn.z;
shell > cat z.txt
7,6
10,8
//在Windows平台下,由于换行符是“\r\n”,因此在导出时可能需要指定LINES TERMINATED BY选项,如:
mysql> select * into outfile '/var/lib/mysql-files/z.txt' fields terminated by ',' lines terminated by '\r\n' from learn.z;
逻辑备份与恢复
1. mysql 与source 命令
注意:通过mysqldump可以恢复数据库,但是经常发生的一个问题是,mysqldump可以导出存储过程、导出触发器、导出事件、导出数据,但是却不能导出视图。因此,如果用户的数据库中还使用了视图,那么在用mysqldump备份完数据库后还需要导出视图的定义,或者备份视图定义的frm文件,并在恢复时进行导入,这样才能保证mysqldump数据库的完全恢复。
//导出数据库learn
shell > mysqldump -u root -p --databases learn >dump.sql
//mysql命令(恢复表结构和数据)
shell > mysql -uroot -p < dump.sql
//导出数据库learn
shell > mysqldump -u root -p --databases learn >dump.sql
//source命令(恢复表结构和数据)
mysql> source ~/test/dump.sql;
2. LOAD DATA INFILE(恢复表数据)
(1) 作用
若通过mysqldump-tab,或者通过SELECT INTO OUTFILE导出的数据需要恢复,这时可以通过命令LOAD DATA INFILE来进行导入。
(2) 注意
要对服务器文件使用LOAD DATA INFILE,必须拥有FILE权。其中对于导入格式的选项和之前介绍的SELECT INTO OUTFILE命令完全一样。IGNORE number LINES选项可以忽略导入的前几行
(3) 使用
mysql> select * from z;
+----+------+
| a | b |
+----+------+
| 7 | 6 |
| 10 | 8 |
+----+------+
//导出z表数据
mysql> select * into outfile '/var/lib/mysql-files/z.txt' from learn.z;
//删除还需要创建表
mysql> truncate table z;
mysql> load data infile '/var/lib/mysql-files/z.txt' into table z;
mysql> select * from z;
+----+------+
| a | b |
+----+------+
| 7 | 6 |
| 10 | 8 |
+----+------+
//为了加快InnoDB存储引擎的导入,可能希望导入过程忽略对外键的检查,因此可以使用如下方式
mysql> SET @@foreign_key_checks=0;
mysql> load data infile '/var/lib/mysql-files/z.txt' into table z;
//另外可以针对指定的列进行导入,如将数据导入列a、b,而c列等于a、b列之和:
//注意:好像导出的z.txt数据必须要以,分隔,要不然load的话会报错
mysql> select * into outfile '/var/lib/mysql-files/z.txt' fields terminated by ',' from learn.z;
mysql> CREATE TABLE b( a INT, b INT, c INT, PRIMARY KEY(a) )ENGINE=InnoDB;
mysql> load data infile '/var/lib/mysql-files/z.txt' into table b FIELDS TERMINATED BY ',' (a,b) set c=a+b;
mysql> select * from b;
+----+------+------+
| a | b | c |
+----+------+------+
| 7 | 6 | 13 |
| 10 | 8 | 18 |
+----+------+------+
3. mysqlimport(恢复表数据)
(1) 作用
mysqlimport是MySQL数据库提供的一个命令行程序,从本质上来说,是LOAD DATA INFILE的命令接口,而且大多数的选项都和LOAD DATA INFILE语法相同。
(2) 特点
mysqlimport命令可以用来导入多张表。并且通过–user-thread参数并发地导入不同的文件。这里的并发是指并发导入多个文件,而不是指mysqlimport可以并发地导入一个文件,这是有明显区别的。此外,通常来说并发地对同一张表进行导入,其效果一般都不会比串行的方式好。
(3) 使用
//导出数据
mysql> select * into outfile '/var/lib/mysql-files/z.txt' from learn.z;
mysql> select * into outfile '/var/lib/mysql-files/b.txt' from learn.b;
mysql> truncate z;
mysql> truncate b;
//mysqlimport并发地导入2张表
shell > mysqlimport -uroot -p --use-threads=2 learn /var/lib/mysql-files/z.txt /var/lib/mysql-files/b.txt
//如果在上述命令的运行过程中,查看MySQL的数据库线程列表,可以用下面命令:
mysql>SHOW FULL PROCESSLIST;
四、二进制日志备份与恢复
1. 概述
二进制日志非常关键,用户可以通过它完成point-in-time的恢复工作。MySQL数据库的replication同样需要二进制日志。
在默认情况下并不启用二进制日志,要使用二进制日志首先必须启用它.推荐的二进制日志的服务器配置应该是:
[mysqld]
log-bin=mysql-bin
sync_binlog=1
innodb_support_xa=1
参考之前博客:mysql二进制日志
2. 使用
//在备份二进制日志文件前,可以通过FLUSH LOGS命令来生成一个新的二进制日志文件,然后备份之前的二进制日志。
//重新生成一个新的二进制日志文件
mysql> FLUSH LOGS;
//备份之前的二进制文件binlog.000001 binlog.000002
shell> ls
befen binlog.000001 binlog.000002 binlog.index error.log
//删除要恢复的数据库 或者 删除该数据库下面的所有表
mysql> drop database learn;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
mysql> create database learn;
//恢复learn数据库
shell > mysqlbinlog binlog.00000[1-2] | mysql -uroot -p
//查看恢复后的数据库
mysql> use learn ;
mysql> show tables;
+-----------------+
| Tables_in_learn |
+-----------------+
| articles |
| b |
| buy_log |
| fts_a |
| t |
| user_stopword |
| z |
+-----------------+
//--start-position和--stop-position选项可以用来指定从二进制日志的某个偏移量来进行恢复,这样可以跳过某些不正确的语句,
//--start-datetime和--stop-datetime选项可以用来指定从二进制日志的某个时间点来进行恢复
mysql> drop database learn;
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
mysql> create database learn;
mysql> show master status;
mysql> SHOW BINLOG EVENTS IN 'binlog.000001';
mysql> SHOW BINLOG EVENTS IN 'binlog.000002';
shell > mysqlbinlog --start-position=4 binlog.000001 | mysql -uroot -p learn
shell > mysqlbinlog --start-position=2 binlog.000001 | mysql -uroot -p learn
五、热备
1. ibbackup
(1) ibbackup介绍
ibbackup是InnoDB存储引擎官方提供的热备工具,可以同时备份MyISAM存储引擎和InnoDB存储引擎表。
ibbackup提供了一种高性能的热备方式,是InnoDB存储引擎备份的首选方式。不过它是收费软件,并非免费的软件。
(2) ibbackup工作原理
1)记录备份开始时,InnoDB存储引擎重做日志文件检查点的LSN。
2)复制共享表空间文件以及独立表空间文件。
3)记录复制完表空间文件后,InnoDB存储引擎重做日志文件检查点的LSN。
4)复制在备份时产生的重做日志。
(3) ibbackup优点
- 在线备份,不阻塞任何的SQL语句。
- 备份性能好,备份的实质是复制数据库文件和重做日志文件。
- 支持压缩备份,通过选项,可以支持不同级别的压缩。
- 跨平台支持,ibbackup可以运行在Linux、Windows以及主流的UNIX系统平台上。
(4) ibbackup恢复步骤
1)恢复表空间文件。
2)应用重做日志文件。
2. xtrabackup
(1) xtrabackup介绍
免费热备工具,它实现所有ibbackup的功能,并且扩展支持了真正的增量备份功能。
官网地址
(2) xtrabackup增量备份的原理
1)首选完成一个全备,并记录下此时检查点的LSN。
2)在进行增量备份时,比较表空间中每个页的LSN是否大于上次备份时的LSN,如果是,则备份该页,同时记录当前检查点的LSN。
(3) xtrabackup优点
备份和恢复的速度比较快
(4) xtrabackup安装
//这里以ubuntu 18.04 为例:
shell > apt search xtrabackup
shell > apt install xtrabackup
shell > xtrabackup --help
(5) xtrabackup使用
官网地址
//查看备份文件的位置
shell > xtrabackup --help | grep target
target-dir /root/xtrabackup_backupfiles/
//1. 创建 xtrabackup 完全备份
shell > xtrabackup --backup --target-dir=/root/xtrabackup_backupfiles/ -uroot -p密码
shell > cd /root/xtrabackup_backupfiles/
//2. 创建 xtrabackup 增量备份
//创建增量备份1和2(这里分2个仅为测试)
shell > xtrabackup --backup --target-dir=~/incr1 --incremental-basedir=/root/xtrabackup_backupfiles -uroot -p密码
shell > xtrabackup --backup --target-dir=~/incr2 --incremental-basedir=~/incr1 -uroot -p密码
//3. 准备增量备份
shell > xtrabackup --prepare --apply-log-only --target-dir=/root/xtrabackup_backupfiles
//将第一个增量备份运用到完全备份中
shell > xtrabackup --prepare --apply-log-only --target-dir=/root/xtrabackup_backupfiles --incremental-dir=~/incr1
//将第二个增量备份运用到完全备份中
shell > xtrabackup --prepare --target-dir=/root/xtrabackup_backupfiles --incremental-dir=~/incr2
//4.恢复备份到mysql
//删除msyql原来数据文件夹中的所有文件
shell > cd /var/lib/mysql
shell > tar -zcvf mysql_benfen.tar.gz *
shell > rm -rf *
shell > service mysql stop
//恢复数据
shell > xtrabackup --copy-back --target-dir=/root/xtrabackup_backupfiles
shell > chown -R mysql:mysql /var/lib/mysql
//重启mysql
shell > service mysql start
六、快照备份
1. 介绍
MySQL数据库本身并不支持快照功能,因此快照备份是指通过文件系统支持的快照功能对数据库进行备份。
支持快照功能的文件系统和设备包括FreeBSD的UFS文件系统,Solaris的ZFS文件系统,GNU/Linux的逻辑管理器(Logical Volume Manager,LVM)等。
2. 条件
备份的前提是将所有数据库文件放在同一文件分区中,然后对该分区进行快照操作
3. 写时复制
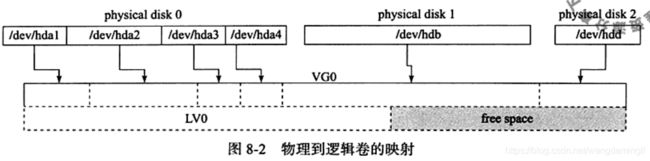
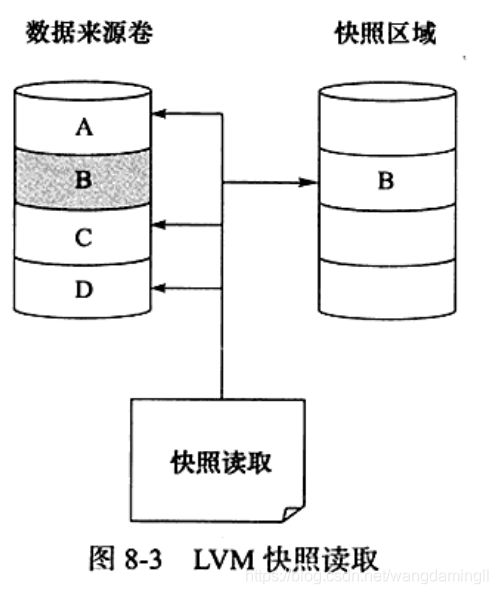
LVM使用了写时复制(Copy-on-write)技术来创建快照。当创建一个快照时,仅复制原始卷中数据的元数据(meta data),并不会有数据的物理操作,因此快照的创建过程是非常快的。当快照创建完成,原始卷上有写操作时,快照会跟踪原始卷块的改变,将要改变的数据在改变之前复制到快照预留的空间里,因此这个原理的实现叫做写时复制。而对于快照的读取操作,如果读取的数据块是创建快照后没有修改过的,那么会将读操作直接重定向到原始卷上,如果要读取的是已经修改过的块,则将读取保存在快照中该块在原始卷上改变之前的数据。因此,采用写时复制机制保证了读取快照时得到的数据与快照创建时一致。
4. 图解

七、复制(replication)
1. 复制的功能
复制可以用来作为备份,但功能不仅限于备份,其主要功能如下:
- 数据分布。由于MySQL数据库提供的复制并不需要很大的带宽要求,因此可以在不同的数据中心之间实现数据的复制。
- 读取的负载平衡。通过建立多个从服务器,可将读取平均地分布到这些从服务器中,并且减少了主服务器的压力。一般通过DNS的Round-Robin和Linux的LVS功能都可以实现负载平衡。
- 数据库备份。复制对备份很有帮助,但是从服务器不是备份,不能完全代替备份。
- 高可用性和故障转移。通过复制建立的从服务器有助于故障转移,减少故障的停机时间和恢复时间。
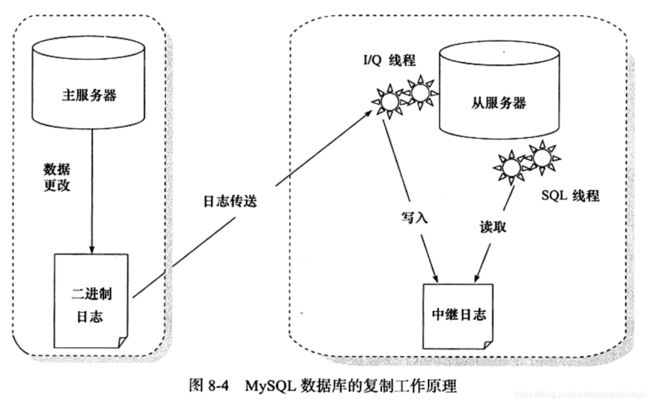
2. 复制的原理
1)主服务器(master)把数据更改记录到二进制日志(binlog)中。
2)从服务器(slave)把主服务器的二进制日志复制到自己的中继日志(relay log)中。
3)从服务器重做中继日志中的日志,把更改应用到自己的数据库上,以达到数据的最终一致性。
复制的工作原理并不复杂,其实就是一个完全备份加上二进制日志备份的还原。不同的是这个二进制日志的还原操作基本上实时在进行中。这里特别需要注意的是,复制不是完全实时地进行同步,而是异步实时。这中间存在主从服务器之间的执行延时,如果主服务器的压力很大,则可能导致主从服务器延时较大。
3. 查看主从服务的延迟
MySQL的复制是异步实时的,并非完全的主从同步。若用户要想得知当前的延迟,可以通过命令SHOW SLAVE STATUS和SHOW MASTER STATUS得知:
SHOW MASTER STATUS 中的Position 减去 SHOW SLAVE STATUS 中的 Read_Master_Log_Pos,就可以得知I/O线程的延时
对于一个优秀的MySQL数据库复制的监控,用户不应该仅仅监控从服务器上I/O线程和SQL线程运行得是否正常,同时也应该监控从服务器和主服务器之间的延迟,确保从服务器上的数据库总是尽可能地接近于主服务器上数据库的状态。
八、快照+复制的备份架构
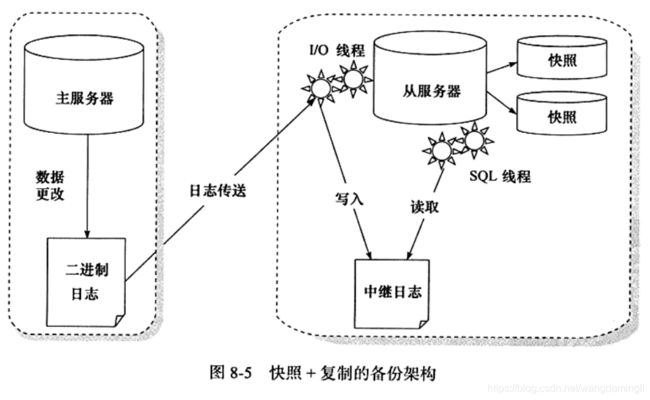
1. 一个异步实时的在线MySQL备份解决方案:快照+复制的备份架构描述
(1) 概述
当前应用采用了主从的复制架构,从服务器作为备份,并且对从服务器上的数据库所在分区做快照,建议将从服务器配置成只读
(2) 架构示意图
(3) 从服务器配置只读
在配置文件中加入:
[mysqld]
read-only
(4) 从服务器恢复
当发生主服务器上的误操作时,只需要将从服务器上的快照进行恢复,然后再根据二进制日志进行point-in-time的恢复即可