360网络自动化运维
女主宣言
当网络设备从数以百计快速发展到数以千计、万计时,当量变引发质变时,要采用什么样的模式才能先于业务发现网络问题和瓶颈呢?本文带来的就是360公司网络自动化运维的一些理念,希望这些设计理念可以帮到需要的小伙伴。
PS:丰富的一线技术、多元化的表现形式,尽在“HULK一线技术杂谈”,点关注哦!
网络自动化
关于网络自动化,有的看法是网络自动化无非是写一些脚本,网工从会敲命令行到会写脚本就完成了自动化的转身;有的看法是网络自动化必须依靠SDN,没有SDN不可能实现网络自动化。其实可以将网络自动化看的更广义一点,不拘泥何种具体的技术,而是一种思想,任何提高效率,解放网工生产力的,都可以称之为自动化。
既然是网络自动化,对象必然是网络设备,现在谈及网络设备不仅包含传统的三大件路由,交换,防火墙,必然还包含各种NFV设备,虚拟化中使用广泛得到linux-bridge,OVS等。自动化操作行为分为:
1. 脚本自动化,比如使用一些telnet/SSH库自动进行一些批量操作,比如设备配置备份,设备健康检查等;
2. 自动化上线: 使用ZTP等技术让设备自动加入网络等;
3. 自动化操作是进一步的抽象,将一系列的操作都自动化,比如网络设备和openstack对接,openstack创建网络,创建虚拟机等操作均变成自动的。 在此之上可以存在资源编排系统,资源编排系统对北向为业务提供接口,对下整合自动化,满足业务上线监控需求。

为什么需要网络自动化
爆炸性增长,结构更加复杂
网络设备从数以百计快速发展到数以千计,量变引发质变。网络结构也从简单的二层网络,发展到以三层网络为主要架构的大型机房,骨干网络从无到有,从大到小,从简单到复杂的流量工程;业务类型也从单纯的提供物理服务器,也变成需要支撑openstack虚拟化环境,container环境。设备数量发生了指数型的变化,但是运维人员没有跟随设备的增长指数变化,只是平滑增长。如果还按照老的模式运维,不但满足不了业务需求,而且团队也会处于天天灭火状态,技术无法提升,无法跟上业务发展,从而恶性循环。
利于运维
基本上每个公司,业务都是处于食物链的顶层,运维处于底层。如果自己不修炼的跑的快一些,终究一天会被业务淹没。所以基础建设运维必须走在业务前面,建设要快,维护要稳,要先于业务发现问题和瓶颈。
网络设备的考量
1
如何考量网络设备
设备是一个稳定网络的基石。不管这个设备是购买专业厂家的设备,还是购买白牌交换机,都需要对设备按照统一的标准进行考量。
对设备的考量除了基本的满足数据中心的冗余性设计,buffer需求,各种表项外(如果是大二层的网络,你需要大的MAC,如果是三层clos的结构,你需要是大的路由表象,如果你有大量安全需求,你需要大acl),也要充分是否支持各种自动化的技术。
比如说支持ZTP可以实现交换机零配置上线,支持API可以方便进行网络自动化,支持EVPN和VXLAN可以方便部署虚拟化结合的业务。为了着眼于未来,我们还需要考量采购的软硬件是否还支持未来技术发展的方向。有了设备作为基础,我们才方便开展后续的网络规划,设计,运维。

2
设备自动上线
目前主流厂家均支持了ZTP。就是零配置上线。
使用ZTP上线设备有2种方法:一种是提前知道设备的MAC地址,将MAC地址和配置进行一一映射。然后上线的时候,让实施人员按照MAC地址和机柜的对应关系进行布放。然后设备启动后就可以从dhcp服务器读取到对应的配置。如果设备出现故障的话,也需要工程师进行mac地址的更新,才能进行设备替换。
另外一种实现是ZTP结合LLDP。因为规划先行,每个交换机放置到哪个机柜,连接哪个核心交换机都已经固定了。交换机第一次启动的时候,通过ZTP获得一个基础配置,然后通过LLDP协议发现自己的位置,然后再次请求一个正确的配置。这种方法的好处是不需要提前录入MAC和交换机的对应换机,当设备出现问题的时候进行替换也不需要工程师介入。
3
与业务的自动联动
奇虎网络的自动上线主要是和openstack结合。
奇虎是F版本就开始在生产环境部署。刚开始的时候使用VLAN模式,但是在一个ip CLOS的环境下使用VLAN模式有很多不方便的地方。比如网络必须切的很小,虚拟机无法漂移。
随着芯片的发展,大部分厂家在2016年都支持了VXLAN和EVPN。 使用EVPN作为VXLAN的控制信令有很多优势,比如自动发现,更新控制,使得VXLAN在数据中心大规模部署成为可能。结合VXLAN的分布式网关,可以实现虚拟化的随意漂移。使用虚拟机本来就是为了追求快速部署,如果是为了满足业务还需要找网络团队配置网络,就有点跟不上节奏了。所以我们为openstack团队提供了基于neutron的插件,让openstack直接控制网络。
在这种模式下,我们探讨了2条路线,一种是使用厂家的根据奇虎需求定制的插件,一种是我们自己写的插件。
使用厂家的查件好处是不用自己写代码了,但是坏处也显而易见就是代码是别人的,修改bug要跟着他们的版本走。自己写的好处是,代码是自己的,可以快速迭代,前提是团队有人对openstack,网络,编程的积累。
这种模式,虽然是插件的形式,但是我们的代码也是和业务耦合在一起的,我们和设备交互的代码业务可以直接看到,我们要更新这些代码,业务也需要跟着迭代。如果需要对接openstack外的其他平台,还需要写driver,显得就不够灵活。所以,我们又开展了另外一种模式,把openstack,docker平台的需求进行抽象,把抽象完毕的动作都写成API,然后让各种不同的平台按照业务逻辑进行调用。
这样就把设备操作从业务代码解耦出来了,再升级设备操作的代码,只要保证接口不变,就不用让业务代码跟着迭代了,也提供了代码的重用率。
4
故障诊断
快速定位突发流量
日常中我们经常会发现某台交换机一个端口或多个端口会出现流量突发。为了找出这些端口对应的服务器,一般的操作是查看端口对应的MAC地址,然后根据MAC地址查询出对应的服务器情况。
有时候业务部门需要了解服务器所在交换机上行接口的流量情况,以对业务调度进行调整。
将CMDB系统、交换机表项、CACTI或其他流量监控系统进行整合,可以方便的根据服务器或交换机查询到对应的端口及流量信息,减少无用的重复操作。
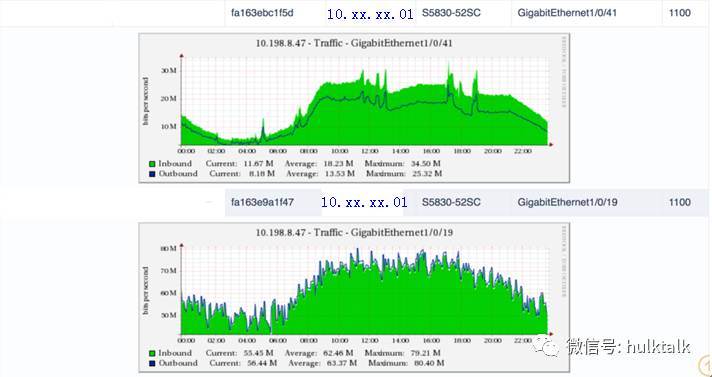
骨干网监控
传统的网管设备主要是对网络设备的运行状况进行监控,发现一些端口丢包,设备硬件异常等问题。但是这些不能发现网络运行的健康状况。我们使用分布式PING监控的方式来对网络进行监控,根据相关阈值进行告警,记录历史数据方便回溯。这种监控包含IDC内部监控,IDC间监控,对运营商网络质量的监控。做到先于业务发现网络问题。

主机间网络快速诊断
随着网络规模的扩大,定位网络问题耗费的时间也越来越多。当业务出现跨机房调度的时候,可能会经过数十个网络设备。如果出现跨机房网络丢包,慢的情况,要精确定位问题可能需要把数十个设备都检查一遍,这样效率是很低的,而且很多情况下是重复性的劳动。为了提高定位问题的效率,我们使用路径查询工具,输入业务IP地址就可以直接获得业务经过的路径,并同时对常见问题进行自动诊断。比如端口错包,端口流量高等情况会直接反馈出来,节省故障排查时间。
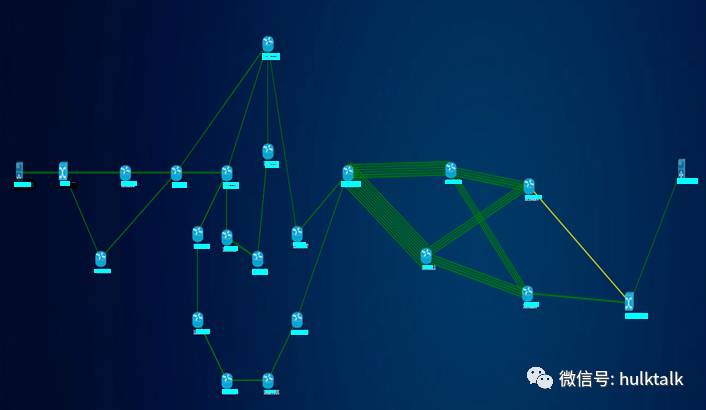
黄色的线代表出现了问题,点开后可以具体看到是出现了CRC错误。

总结
奇虎网络团队一直以来的宗旨是为业务提供稳定的服务,为业务提供看得见的网络服务;致力于让网络工程师摆脱重复性的工作,从而有时间进行创造性的工作。我们开展的网络自动化工作也是围绕此宗旨开展的,目前看取得了阶段性的成果,摆脱了原始阶段。此外我们也一直投入精力在为上层业务提供API上,能够让业务与网络无障碍的直接交流,进一步提高效率。我们将持续在这方面投入,在Netdevops之路上继续探索, 做一切符合业务需求和发展的事情。
扫描下方二维码了解更多内容 