spark内存计算框架基础
目录
1. spark是什么
2. spark的四大特性
2.1 速度快
2.2 易用性
2.3 通用性
2.4 兼容性
3. spark集群架构
3.1 Driver
3.2 Application
3.3 ClusterManager
3.4 Master
3.5 Worker
3.6 Executor
3.7 Task
4.Spark与MapReduce的区别?spark比mapreduce快的2个主要原因
4.1 区别
4.2 spark快的原因
5.spark提交任务命令
5.1 普通模式提交 (指定活着的master地址)
5.2 高可用模式提交 (集群有很多个master)
6.spark-shell使用
6.1 运行spark-shell --master local[N] 读取本地文件进行单词统计
6.2运行spark-shell --master local[N] 读取HDFS上文件进行单词统计
6.3 运行spark-shell 指定集群中活着master 读取HDFS上文件进行单词统计
7.Spark 代码流程
8.spark程序的序列化
8.1、transformation操作为什么需要序列化
8.2、 spark的任务序列化异常
8.3、spark中解决序列化的办法
1. spark是什么
Apache Spark™ is a unified analytics engine for large-scale data processing。即:spark是针对于大规模数据处理的统一分析引擎。
2. spark的四大特性
2.1 速度快

运行速度提高100倍:
Apache Spark使用最先进的DAG调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。
2.2 易用性

可以快速去编写spark程序通过 java/scala/python/R/SQL等不同语言。
2.3 通用性

spark框架不在是一个简单的框架,可以把spark理解成一个生态系统,它内部是包含了很多模块,基于不同的应用场景可以选择对应的模块去使用。
(1)sparksql:通过sql去开发spark程序做一些离线分析(类似于hive)。
(2)sparkStreaming:主要是用来解决公司有实时计算的这种场景。
(3)Mlib:它封装了一些机器学习的算法库。
(4)Graphx:图计算
2.4 兼容性

spark程序就是一个计算逻辑程序,这个任务要运行就需要计算资源(内存、cpu、磁盘),哪里可以给当前这个任务提供计算资源,就可以把spark程序提交到哪里去运行。
3. spark集群架构

3.1 Driver
它会执行客户端写好的main方法,它会构建SparkContext对象;该对象是所有spark程序的执行入口。
3.2 Application
spark的应用程序,它是包含了客户端的代码和任务运行的资源信息。
3.3 ClusterManager
它是给程序提供计算资源的外部服务。
(1)standAlone
spark自带的集群模式,整个任务的资源分配由spark集群的Master负责。
(2)yarn
可以把spark程序提交到yarn中运行,整个任务的资源分配由yarn中的ResourceManager负责。
(3)mesos
它也是apache开源的一个类似于yarn的资源调度平台。
3.4 Master
它是整个spark集群的主节点,负责任务资源的分配。
3.5 Worker
它是整个spark集群的从节点,负责任务计算的节点。
3.6 Executor
它是一个进程,它会在worker节点启动该进程(计算资源)。
3.7 Task
spark任务是以task线程的方式运行在worker节点对应的executor进程中。
4.Spark与MapReduce的区别?spark比mapreduce快的2个主要原因
4.1 区别
相同点:都是分布式计算框架;
不同点:
(1)Spark可以基于内存处理数据,MR基于磁盘迭代处理数据(hdfs);
(2)Spark中有DAG有向无环图;
(3)MR中只有map reduce ,Spark中有各种场景的算子;
(4)Spark是粗粒度资源申请,MR是细粒度资源申请。
4.2 spark快的原因
1、spark基于内存
(1)mapreduce任务后期在计算的时候,每一个job的输出结果会落地到磁盘,后续有其他的job需要依赖于前面job的输出结果,这个时候就需要进行大量的磁盘io操作。性能就比较低。
(2)spark任务后期在计算的时候,job的输出结果可以保存在内存中,后续有其他的job需要依赖于前面job的输出结果,这个时候就直接从内存中获取得到,避免了磁盘io操作,性能比较高。
(3)对于spark程序和mapreduce程序都会产生shuffle阶段,在shuffle阶段中产生的数据都会落地到磁盘。
2、进程与线程
(1)mapreduce任务以进程的方式运行在yarn集群中,比如程序中有100个MapTask,一个task就需要一个进程,这些task要运行就需要开启100个进程。
(2)spark任务以线程的方式运行在进程中,比如程序中有100个MapTask,后期一个task就对应一个线程,只需要开启1个进程,在这个进程中启动100个线程就可以了。
进程中可以启动很多个线程,而开启一个进程与开启一个线程需要的时间和调度代价是不一样。 开启一个进程需要的时间远远大于开启一个线程。
5.spark提交任务命令
5.1 普通模式提交 (指定活着的master地址)
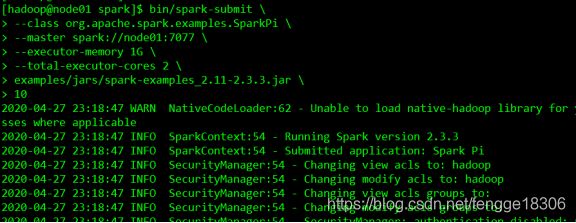
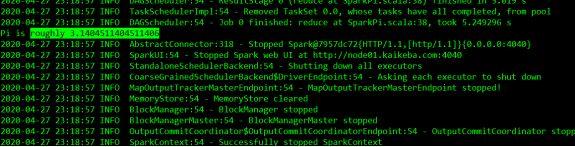
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.3.3.jar \
10####参数说明
--class:指定包含main方法的主类
--master:指定spark集群master地址
--executor-memory:指定任务在运行的时候需要的每一个executor内存大小
--total-executor-cores: 指定任务在运行的时候需要总的cpu核数

5.2 高可用模式提交 (集群有很多个master)
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077,node02:7077,node03:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
examples/jars/spark-examples_2.11-2.3.3.jar \
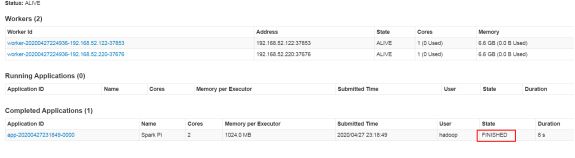
10spark集群中有很多个master,并不知道哪一个master是活着的master,即使你知道哪一个master是活着的master,它也有可能下一秒就挂掉,这里就可以把所有master都罗列出来
--master spark://node01:7077,node02:7077,node03:7077
后期程序会轮询整个master列表,最终找到活着的master,然后向它申请计算资源,最后运行程序。
(1) 如何恢复到上一次活着master挂掉之前的状态?
在高可用模式下,spark集群有多个master,其中只有一个master被zk选举成活着的master,其他的多个master都处于standby,同时把整个spark集群的元数据信息通过zk中节点进行保存。
后期如果活着的master挂掉。首先zk会感知到活着的master挂掉,下面开始在多个处于standby中的master进行选举,再次产生一个活着的master,这个活着的master会读取保存在zk节点中的spark集群元数据信息,恢复到上一次master的状态。整个过程在恢复的时候经历过了很多个不同的阶段,每个阶段都需要一定时间,最终恢复到上个活着的master的转态,整个恢复过程一般需要1-2分钟。
(2) 在master的恢复阶段对任务的影响?
a)对已经运行的任务是没有任何影响
由于该任务正在运行,说明它已经拿到了计算资源,这个时候就不需要master。
b) 对即将要提交的任务是有影响
由于该任务需要有计算资源,这个时候会找活着的master去申请计算资源,由于没有一个活着的master,该任务是获取不到计算资源,也就是任务无法运行。
6.spark-shell使用
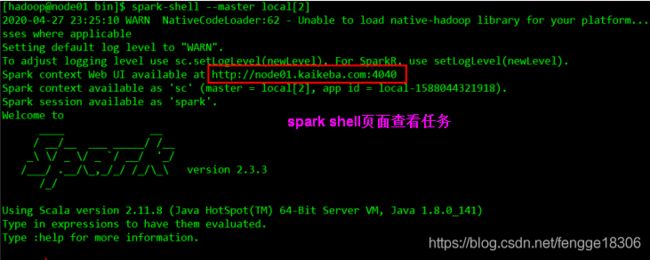
6.1 运行spark-shell --master local[N] 读取本地文件进行单词统计
--master local[N]
–local 表示程序在本地进行计算,跟spark集群目前没有任何关系;
–N 它是一个正整数,表示使用N个线程参与任务计算;
–local[N] 表示本地采用N个线程计算任务;
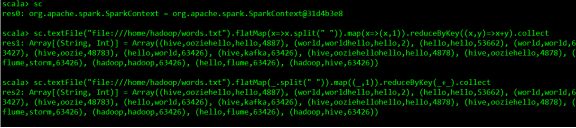
textFile("file:///home/hadoop/words.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).collect
sc.textFile("file:///home/hadoop/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
6.2运行spark-shell --master local[N] 读取HDFS上文件进行单词统计
(1)spark整合HDFS
1、在node01上修改配置文件
vim spark-env.sh
HADOOP_CONF_DIR=/install/hadoop-2.6.0-cdh5.14.2/etc/hadoop/2、分发到其他节点
2、分发到其他节点
scp spark-env.sh node02:/install/spark/conf
scp spark-env.sh node03:/install/spark/conf
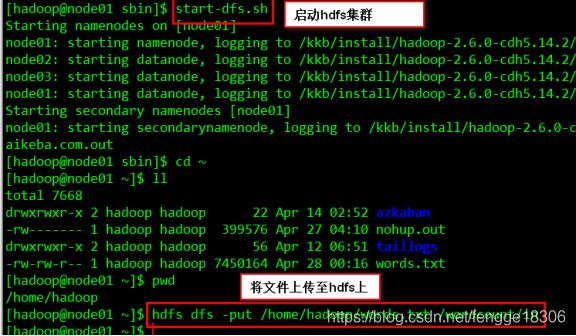
(2)启动hadoop集群,再将文件word.txt上传至hdfs上
hadoop集群:
cd /install/hadoop-2.6.0-cdh5.14.2/sbin
start-all.sh
将文件word.txt上传至hdfs上:
hdfs dfs -put /home/hadoop/word.txt /
(2)输入命令:spark-shell --master local[2]
textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
sc.textFile("hdfs://node01:8020/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
6.3 运行spark-shell 指定集群中活着master 读取HDFS上文件进行单词统计
(1)输入命令spark-shell --master spark://node01:7077 --executor-memory 1g --total-executor-cores 4
参数说明:
--master spark://node01:7077 指定活着的master地址
--executor-memory 1g 指定每一个executor进程的内存大小
--total-executor-cores 4 指定总的executor进程cpu核数
(2)输入如下算子
sc.textFile("hdfs://node01:8020/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
//实现读取hdfs上文件之后,需要把计算的结果保存到hdfs上
sc.textFile("/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/out")
![]()


7.Spark 代码流程
1)创建sparkConf对象,设置Spark运行模式,运行参数,运行资源,spark名称;
2)创建SparkContext对象,是所有spark程序的执行入口(内部会构建DAGScheduler和TaskScheduler对象);
3)基于Spark上下文创建一个RDD,对RDD进行处理;
4)对RDD使用transformation类算子进行数据转换;
5)对RDD使用action类算子触发transformation类算子的执行(触发job执行);
6)关闭spark上下文对象SparkContext。
8.spark程序的序列化
8.1、transformation操作为什么需要序列化
Spark的计算有如下执行过程:
(1)代码中对象在driver本地序列化;
(2)对象序列化后传输到远程executor节点;
(3)远程executor节点反序列化对象;
(4)最终远程节点执行。
故对象在执行中要进行网络传输,则必须经过序列化过程。
8.2、 spark的任务序列化异常
(1)在map,foreachPartition等算子内部使用了外部定义的变量和函数,从而引发Task未序列化问题;
(2)出现“org.apache.spark.SparkException: Task not serializable”这个错误,其原因就在于这些算子使用了外部的变量,但是这个变量不能序列化。
(3)当前类使用了“extends Serializable”声明支持序列化,但是由于某些字段不支持序列化,仍然会导致整个类序列化时出现问题,最终导致出现Task未序列化问题。
8.3、spark中解决序列化的办法
(1) 如果函数中使用了该类对象,该类要实现序列化,需继承extends Serializable;
(2) 如果函数中使用了该类对象的成员变量,该类除了要实现序列化之外,所有的成员变量必须要实现序列化;
(3) 对于不能序列化的成员变量使用“@transient”标注,告诉编译器不需要序列化;
(4) 也可将依赖的变量独立放到一个小的class中,让这个class支持序列化,这样做可以减少网络传输量,提高效率;
(5) 可以把对象的创建直接在该函数中构建,这样避免需要序列化。