c++: 2.编译链接原理
编译链接原理
书籍推荐:编译技术与原理(李文生)
![]()
以下面代码为例:


1.预编译处理内容(.i)
1.1主要处理以“#”开头的表达式:例如:宏,头文件,预编译指令,具体如下:
1.1.1宏:预编译删除宏定义并做文本替换,如上图的宏MAX,代码中所有MAX自动替换为20
1.1.2头文件:头文件打开一般还包含其他头文件(嵌套关系)。预编译递归展开头文件
1.1.3预编译指令:#if 0 部分跳过,#if 1 部分保留

1.2删除注释 (/* */)
1.3添加行号,文件标识。方便直接跳到错误位置
1.4保留#pragma
2.编译处理内容(.s)
2.1词法分析
处理c语言源程序,过滤掉无用符号,判断源程序中单词的合法性,并分解出正确的单词,以二元组形式存放在文件中。
词法分析器代码:
参照维秀博客:https://www.cnblogs.com/zyrblog/p/6885922.html
2.2语法分析:
语法分析是根据源语言的语法规则从源程序词法分析阶段的结果中识别出各种语法成分,同时进行语法检查,为语义分析和代码生成做准备。目前语法分析常用的方法有自顶向下分析和自底向上分析两大类。
如下图重定义:

语法分析器代码:
参照cabbage_bird博客:https://www.cnblogs.com/poi-kexin/p/11761987.html
2.3语义分析:

如下图语法正确,但语句无意义
![]()
2.4代码优化:提高程序运行效率
2.5生成汇编指令
3…汇编(.o 目标文件又叫可重入的二进制文件)
越接近人的语言越高级C,C++等,越接近机器越低级机器语言,中间还有个汇编语言。汇编主要翻译指令成二进制文件.o
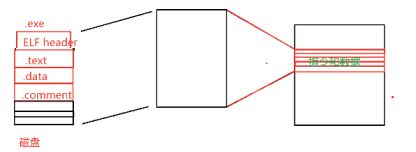
unix中上面代码的.o文件布局查看:
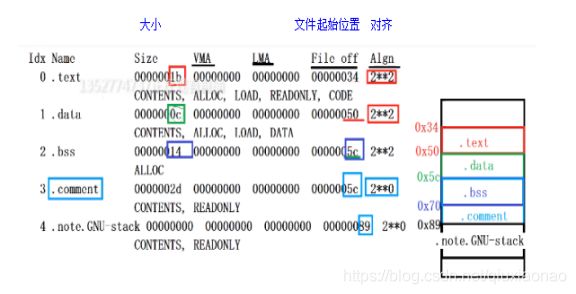
上图有两个问题:
1…bss与.comment两个起始位置一样。其实.bss不存在而是.comment存在。但文件布局中还是显示其起始位置和大小
2. .bss大小0x14为20个字节,但上面代码中int main()里有24个字节,少了一个变量?
原因如下:(下图为虚拟空间)

查看文件头部目录section header
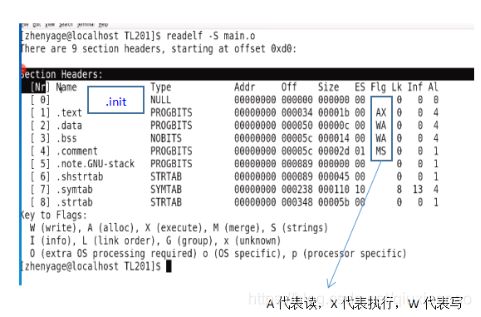
上面的main.o查看main.o的符号表
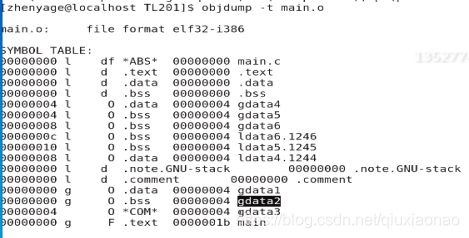
注:gdata3在.comment段,因为:
C中全局变量有强弱符号概念(C++中没有),编译阶段处理强弱符号。预编译。编译。汇编处理源文件时,看不见其他原文件内容,则汇编后看不见其他源文件强符号。弱符号暂时放在com段。全处理完,若有强符号则把com中对应符号剔除,否则把他移入.bss。这就是.bss和.comment存在的意义。第二问中少的是弱变量gdata3。4个字节
注:强弱符号详细理解:
强弱符号概念:
对于C/C++而言,编译器默认函数和已初始化的全局变量为强符号,而未初始化的全局变量为弱符号,在编程者没有显示指定时,编译器对强弱符号的定义会有一些默认行为,同时开发者也可以对符号进行指定,使用"attribute((weak))"来声明一个符号为弱符号。
前弱符号规则:
①不允许有多个同名的强符号
②如果有一个强符号和多个弱符号,那么选择强符号
③如果有多个弱符号,那么从这些弱符号中任选一个
④在默认的符号类型情况下,强符号和弱符号是可以共存的,类似于这样:
int x;
int x = 1;
编译不会报错,在编译时x的取值将会是1.
但是使用__attribute__((weak))将强符号转换为弱符号,却不能与一个强符号共存,类似于这样:
int attribute((weak)) x = 0;
int x = 1;
强弱符号举例:

结果a为100,b为0,原因为a=100,覆盖了b。如下:

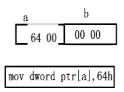
4 .链接:
4.1链接前,汇编后未处理内容: 强弱符号,外部符号,指令段未
4.1.1强弱符号
前文已讲
4.1.2 外部符号

main.o中两个extern外部符号:文件之间独立,gdata和SUM在哪定义不知道,在UND中

4.1.3指令段(虚假地址和偏移)
对于外部符号存在虚假地址和虚假偏移的问题:
代码1:
.![]()
两个指令步骤:
①从gdata对应内存提取数据:用的是零地址(或4,8)代替gdata地址,因为文件之间独立,此时找不到gdata定义,也就不知道其真实地址 ![]()
②把数据放在ldata2的对应内存
代码2:
![]()
指令步骤第一步:调用sum函数(call SUM(sum的地址))
call指令:近址相对位移调用指令(近址指的是下一行指令的地址),例如:

sum函数入口地址:近址(2e)+ 相对位移(ff ff ff fc =(-4))= 2A(0
xFFFF FFFC),为内核地址,(普通函数无法放在内核地址,普通应用程序也无法使用内核地址),因此为虚假地址,不是sum的入口地址(原因也是文件之间独立),说明相对位移为虚假位移(偏移),因此链接阶段需要调整虚假偏移
4.2链接阶段处理内容
4.2.1合并段和符号表
4.2.1.1合并段:
目标文件和可执行文件:lulix:ELF文件;windows:PE文件
假设有三个原文件a,b,c,经过预编译,编译和汇编形成a.o,b.o,c.o三个目标文件,链接要合成一个ELF文件。文件合并方式为相同段合并
4.2.1.2合并符号表:(上面test.o和main.o符号表如下)

①处理强弱符号(COM)
找到各个弱符号对应强符号(找到用强代替弱,找不到把弱符号从COM移到.bss中)
②处理外部符号(NUD)
在符号引用的地方找到符号定义位置,gdata和Sum均在test.o中(又叫符号解析),找到后把符号从NUD删掉
③分配地址和空间
给②处理后的符号表每个符号分配虚拟地址和空间(真实地址)
④符号重定位(处理虚假地址和虚假偏移)
用真实地址和偏移替换指令段原来的虚假地址和偏移
5.运行
①建立虚拟地址空间和物理内存的映射
创建内核映射结构体,创建页表页目录
②加载指令和数据(在磁盘(文件)中存放着)
通loader加载器把数据从磁盘加载到内存中。指令与数据分别加载到一页
③把main函数的入口地址写入下一行指令寄存器。
存储器对应的空间越大,可存放数据越多,造价越便宜但IO效率(读写效率)越差。Cpu和内存运行速度差距太大(cpu快很多),对于cpu来说效率低,寄存器产生。分类很多,其中下一行指令寄存器存在于内存和cpu中间,缓解二者速度差距