JavaSE学习过程中问题总结 —— 集合框架、IO流、多线程等
回顾完基本概念和一些常用类,进入重点:
(内容很多但没有分文章写,主要是自己的知识巩固和做下笔记,不够负责任,算不上知识分享)
一、集合框架
1、集合引入
(1)对象数组的概念:将多个类对象存放为数组
特点:长度固定,不适应变化的需求。
(2)面向对象强调的是对象,需要容器来进行存储和操作
之前提过StringBuffer虽然是一种容器,但只存放字符串
如果没有集合,我们只能选择对象数组,但并不能满足需求
所以Java提供了集合,方便对多个对象进行操作
(3)集合与数组的区别
数组可以存储对象,也可以存储基本类型,并且存放的都是同一类型元素
集合是可变的,但只能存储对象,可以存储不同类型元素(但其实一般还是同类型)
(4)集合框架的继承体系
存放多个元素时,我们可能有不同的需求
例如是否允许有重复元素,是否需要有序存放,或是是否需要进行排序等
针对多样的需求,Java也为我们提供了不同的集合类
这些类数据结构不同,功能不同;但也存在共性,所以他们存在一个继承体系
基类:Collection
两个分支:List与Set
List分支下三个子类:ArrayList、Vector、LinkedList
Set分支下两个子类:HashSet、TreeSet
* 继承体系:
* Collection
* / \
* List Set
* / | \ | \
* ArrayList Vector LinkedList HashSet TreeSet所以我们从基类开始学起。
2、Collection集合
(1)集合框架体系的基类
它是一个接口,表示一组对象
一些允许重复元素出现,另一些则不允许;一些有序,另一些无序
Jdk不提供该接口的任何具体实现,提供了子接口:List和Set
(2)基本功能
添加和删除:
boolean add(E e);添加功能,而返回布尔类型,表示是否添加成功。例如当集合发生了改变,则返回true;再比如集合中出现了原来有的元素,而子实现类集合不允许重复,则返回false。
addAll(Collection c);将指定集合中的元素都添加到该集合,也返回布尔类型
clear();清空集合,很暴力的方法
remove(obj);删除指定元素的单个实例
removeAll(c);删除集合中也包含在指定集合的所有元素,可以说是删除交集;只要有一个元素被移除了,就会返回true
一些简单的判断和获取一些值的方法:
contains(obj);判断是否包含指定元素,也有对应的all方法
equals、isEmpty、hashCode、size;都是字面就能理解的方法,其实都是API内容,写一遍加深印象
这里要注意的是长度这个属性,在各个容器中都有区别:
数组是直接以点号调用length属性来获取长度,没有length()方法
字符串是length()方法获取长度,所以可能经常习惯性把集合也记为length
集合中是用size()方法返回长度
其他方法:
iterator();返回迭代器
retainAll();保留两个集合都有的元素,可以说是取交集;但是要注意这里返回的布尔类型值,并不是根据有无交集判断true还是false,而是判断集合是否发生了改变,首先要明白,取了交集后,结果是体现在调用该方法的集合中,也就是该集合变成了最后的交集,只要他发生了改变,就返回true,所以即使没有交集,他成为了空集合,也是true的结果
toArray();集合转为数组
(3)集合的遍历方式
方式一:通过toArray方法,转换为数组遍历
方式二:迭代器遍历,iterator方法返回迭代器对象
Iterator是一个接口,有两个方法组合使用可以实现遍历
next();获取下一个元素;如果不进行判断一直获取,到集合末尾会产生异常NoSuchElementException
hasNext();判断是否还有下一个元素,有了这个作为判断,可以防止异常发生
迭代器遍历有两种写法:
假设我有一个集合c存放了一些学生对象,那么遍历基本格式如下
Iterator i = c.iterator();// 这个方法返回的是Iterator子类对象
while (i.hasNext()) {//判断是否有下一个元素,有就一直循环遍历
// 此时没有加入泛型,返回的都是object对象,最好进行向下转型
Student s = (Student) i.next();
System.out.println(s.getName() + "-------" + s.getAge());//拿到每个对象输出属性值
}
这种while循环的结构较清晰,但为了让迭代器对象用完就能被回收,经常还有一种for循环写法
// for改写
for (Iterator ii = c.iterator(); ii.hasNext();) {
Student s = (Student) ii.next();
System.out.println(s.getName() + "---------" + s.getAge());
}//for循环结束,迭代器对象立马变为垃圾,节省空间方式三:JDK5新特性,增强for循环遍历,简单方便
(4)小结
集合的一般使用步骤:
创建集合对象、创建元素对象、将元素添加到集合中、遍历集合进行使用。
迭代器原理:
集合的种类很多,数据结构不同,功能也不同,所以存储和遍历的方式肯定也有差异;所以迭代器被定义为一个抽象接口,只提供共性的功能,而不提供具体实现;而我们为什么能使用他,他的具体实现又是怎么来的,就要去结合源码理解,其实是在集合各种具体子类中以内部类的方式实现的,这样就满足了不同的需求。
3、List集合
(1)Collection下的一个子接口
所以Collection理解之后,List就几乎等于理解了,但既然他是一个分支,就必然有特殊之处。
(2)特点
List是有序的集合,但集合中的有序,并不是平时所说的排序
而是指添加元素时什么顺序,输出是就是什么顺序,可以通过索引进行精准操作
List允许重复元素的出现,他的三个子类也都具有这些特点
(3)扩展功能
正因为他有序的特性,就有一些对应的根据索引操作的方法
add(int index,Object element);可以在指定位置添加元素;可能产生IndexOutOfBounds异常,但可以在结尾添加
get(index);根据索引获取元素;反之有根据元素获取索引的indexOf方法
set(index,element);将指定位置元素替换为指定元素
subList();结合substring理解,截取集合
特殊的迭代器ListIterator
继承于普通迭代器,用法也基本相同,但有特殊的方法
对应于hasNext和next,提供了hasPrevious和previous方法
字面上很好理解,就是向前遍历;鸡肋的是,这两个方法必须在用完了向后遍历后才能使用,类似于一个指针,刚开始都是指在集合前端,只有遍历到最后,指针也指在结尾时才能向前遍历,所以似乎并没有什么用处。
4、简单数据结构
(1)理解集合
说完了List,就要开始提他的具体子类了,而他们大多是根据底层数据结构来划分的,所以为了更好的理解他们各自的特性和功能的差异,不得不先简单回顾下一些常见数据结构。
(2)栈与队列,数组
栈,是一种先进后出的结构(例如弹夹)
队列,先进先出(就像排队)
数组,存储同一类型元素的固定容器
他们有共同的特点,因为有序,所以能够根据索引进行精准的定位,查询快
但如果想要添加或删除元素,需要进行大量的移位操作,还要分配空间,增删效率较慢
(3)链表
由数据域和指针域组成,用一条链把多个结点连在一起
查找时,每次都要从头遍历直到找到元素
增删时,只需要操作指针域进行指向的修改
所以链表的特点是查询慢,增删快
理解了这些基本内容,就可以来说List三个具体子类了。
5、ArrayList集合
(1)List分支下应用最多的集合
继承于List,元素有序,允许出现重复元素
(2)特点
底层数据结构为数组,查询快,增删慢
线程不安全,效率高
(3)用法
Collection理解之后,看完了List,ArrayList基本就相当于掌握了,用法基本一致
6、Vector集合
(1)可以说是ArrayList的前身
从1.0出现的集合类,其他类还是1.2才出现。
(2)特点
线程安全,效率较低
(3)方法
addElement(obj);添加元素
elementAt(index);获取元素
elements();早期的迭代器,返回Enumeration对象
(4)jdk升级原因
从这个类可以看出,jdk进行升级原因一般有,安全问题,效率问题,还有就是想要简化书写;Vector类中的方法名过于长,不方便使用。
7、LinkedList集合
(1)特点
底层数据结构为链表,查询慢,增删快
线程不安全,效率高
(2)特有功能
addFirst(obj);将元素添加到集合开头,有对应的last方法添加到末尾
getFirst();获取第一个元素,也有对应的last方法获取最后一个元素
removeFirst();删除第一个元素,也有removeLast方法
8、List分支下集合的一些小问题
(1)有序、允许重复
虽然有专门的集合不允许重复元素出现,但例如就是想要去除ArrayList中重复元素怎么做
思路一:创建一个新的集合,遍历旧集合往新集合里添加,每次进行判断,新集合中是否包含要添加的元素
for (Iterator i = list.iterator(); i.hasNext();) {//遍历旧集合
String s = (String) i.next();
if (!newList.contains(s)) {//判断新集合是否包含每个集合
nl.add(s);//有则添加
}
}思路二:在原集合上操作,根据选择排序的思想,每个元素与后面元素比较,相同则移除后面的元素
for (int i = 0; i < list.size() - 1; i++) {//外层循环控制拿到每个元素
for (int j = i + 1; j < list.size(); j++) {//内层循环与外层元素后面所有元素比较
if (list.get(i).equals(list.get(j))) {//判断是否相同
list.remove(j);//相同则移除后面的元素
j--;// 一定要注意,移除了一个元素之后,后面的元素补上来,所以内层要重新从对应位置再比较一次
}
}
}要注意的是思路一中,contains方法源码中,判断是否包含指定元素时,调用的是equals方法,例子中是以字符串元素对象举例,重写过equals方法;如果元素是自定义类,一定要记得重写equals方法,否则Object类中,equals就相当于==,即使对象属性值都相同,地址值不同的话也不能被检测出来。
(2)根据LinkedList特点,模拟栈数据结构
思路:LinkedList底层数据结构为链表,有addFirst方法,可以模拟压栈
// 思路:自己写一个集合类,基本方法有add和get,具体实现直接用Link模拟
class MyList {
// 创建一个LinkedList用于模拟方法
private LinkedList list;
public MyList() {
// 构造时才创建对象
list = new LinkedList();
}
public void add(Object obj) {
// 直接用LinkedList特有的方法模拟压栈
list.addFirst(obj);
}
public Object get() {
// 如果用getFirst,永远获取第一个
// 而用remove,返回被移除对象,也模拟了弹栈过程
return list.removeFirst();
}
// 最好加一个判断为空,输出时更严谨
public boolean isEmpty() {
return list.isEmpty();
}
}测试
public static void main(String[] args) {
MyList l = new MyList();
l.add("world");
l.add("hello");
while (!l.isEmpty()) {
System.out.println(l.get());
}注意事项:
首先是问题的理解,刚开始我会理解为,用LinkedList集合模拟出栈结构的出入栈过程
而这个题目的点在于自定义集合,所以意思其实是让你写一个类出来,只是可以用LinkedList作为底层
压栈用addFirst方法比较容易想到,但弹栈如果用getFirst,就只能一直获取第一个元素
所以采用了特有的removeFirst,这个方法正好返回被移除的元素,并且也模拟了弹栈过程
一个小细节就是重写一下isEmpty,这样输出时让while循环有一个出口
9、泛型
(1)引入
之前说集合可以存放不同类型的元素,但其实并不会这样用,但如果不小心添加了不同元素,编译期不会报错,只有在运行时,到了向下转型的阶段,才会被发现有问题,那么怎么解决?集合中提供了泛型的概念,可以对类型进行约束。可以有效避免ClassCastException。
(2)优点
将运行期才会被发现的问题提前到了编译时期
避免了强制类型转换,因为从一开始就限定了元素类型
优化程序设计,减少黄色警告线,使编程更严谨
(3)其他应用
除了集合中用泛型,还有泛型类、方法、接口,可以自己随便写几个理解一下,注意一下格式即可
//自己写一个泛型类
class MyGenericList {
private ArrayList list;
public MyGenericList() {
list = new ArrayList();
}
//泛型方法
public void add(E e) {
list.add(e);
}
public E get(int index) {
return list.get(index);
}
}
//非泛型类中使用泛型方法
class Tool {
//要在方法中定义出泛型
public void show(E e) {
System.out.println(e);
}
}
//泛型定义在接口上
interface Inter {
public abstract void show(E e);
}
//实现类,如果直接知道用什么类型实现,实现类名后不用跟泛型
class InterDemo implements Inter {
@Override
public void show(E e) {
// TODO Auto-generated method stub
System.out.println(e);
}
} (4)高级通配符
在泛型声明时,要求前后必须要一致,即使后面泛型与前面有继承关系,也不能这样声明
所以Java提供了一个通配符“?”,表示任意类型,默认都继承与Object
? extends E,表示向下限定,可以声明E继承体系之下的泛型
? super E,表示向上限定,可以声明E以及E父类的泛型
10、集合与数组
(1)集合转换为数组
之前提过集合有一个方法toArray可以转换为数组
(2)数组转换为集合
Arrays工具类中,提供了一个方法可以把数组转换为集合
public static
(3)注意事项
数组转换为集合之后,本质上还是一个数组,保留了数组长度固定的特性
这个集合只能修改,不能增删
11、一些练习
(1)获取十个1-20随机数,要求不能重复,但使用ArrayList存放
//获取随机数方法
public static void getRandom () {
//创建一个集合存放随机数
ArrayList list = new ArrayList();
//产生与添加
for (int i = 0; i < 10;i++) {
int num = (int) (Math.random()*20 + 1);
if (!list.contains(num)) {
list.add(num);
} else {
i--;//注意点:如果包含,这次循环不算数
}
}
//遍历输出
for (int i : list) {
System.out.println(i);
}
} (2)键盘录入一些值,取最大
public static int getMax() {
int max = 0;
Scanner sc = new Scanner(System.in);
ArrayList list = new ArrayList();
System.out.println("输入多个数字,以0结束");
while (true) {
int num = sc.nextInt();
if (num == 0) {//以0为结束,做排序后跳出循环
//转换成数组,让数组中的方法帮我们做排序
Integer[] i = new Integer[list.size()];
list.toArray(i);
Arrays.sort(i);
max = i[i.length-1];
break;
} else {//输入0之前一直添加
list.add(num);
}
}
return max;
} 12、Set集合
(1)Collection的另一个分支
元素无序、唯一的集合
(2)方法差异
add方法会判断是否包含该元素,保证元素唯一性
没有get方法,因为无序不能使用索引定位
遍历只能使用迭代器或增强for,不能使用普通for,原因也是因为无序
13、HashSet
(1)继承于Set集合
不保证set的迭代顺序,特别是不保证该顺序恒久不变
元素唯一,底层数据结构是哈希表,依赖于哈希值存储
(2)保证元素唯一
添加功能依赖于两个方法hashCode与equals
字符串中重写了这些方法,测试时可以直接添加保证唯一
如果要存放自定义对象,自定义类中一定要记得重写两个方法
否则默认调用Object类中equals,比较的是地址值,而内容是否一致没有比较
(3)一个子类集合LinkedHashSet
由链表和哈希表结构组成,综合了他们的特点
由链表保证了元素有序
由哈希表保证了元素唯一
14、TreeSet集合
(1)Set分支下的另一个集合
底层是红黑树结构(一种自平衡二叉树)
元素唯一,能够对元素按照规则进行排序(是排序不是有序)
(2)排序方式
方式一:自然排序
调用无参构造默认使用自然排序
是通过类实现comparable接口,重写compareTo方法,在方法中规定排序规则
基本类型的包装类和String类都实现了自然排序,所以集合存放这些元素时输出会默认采取自然排序
而如果存放自定义对象,就需要自己在类中实现接口,重写方法,例如:一个简单的学生类
class Student implements Comparable {//实现接口,注意泛型
private String name;
private int age;
// 一定要重写hashCode与equals方法才能比较出成员变量是否相同
...中间代码省略
@Override
public int compareTo(Student o) {//重写方法
// TODO Auto-generated method stub
//根据自己想要的规则进行重写
int num = this.age - o.age;//这样可以根据年龄排序
//但是依旧不够完善,如果年龄一样,会无法添加,怎么办
//分析次要条件,年龄一样时,再比较姓名是否一致
int num2 = num==0?this.name.compareTo(o.name):num;//直接使用String类中compareTo方法比较
return num2;//正负可以控制正序还是逆序输出
}
} 方式二:排序器排序
TreeSet构造方法中,可以传入一个排序器作为参数,最后输出也是按照排序器的规则进行。
通过Comparator接口,采用匿名内部类的方式,直接重写compare方法,定义自己的规则
例如:我有一个Person类,有两个属性,name和age,定义规则为:按名字长度排序
TreeSet set = new TreeSet(new Comparator() {
public int compare(Person o1, Person o2) {
int num = o1.getName().length()-o2.getName().length();//比较名字长度
int num2 = num==0?o1.getAge()-o2.getAge():num;//要考虑主要的规则如果相同,次要规则怎么写
int num3 = num2==0?o1.getName().compareTo(o2.getName()):num2;
return num3;//如果所有规则都返回0,则可以说明元素相同,就不进行添加
}
}); 其实就是将自然排序中实现接口与重写方法单独的拿出来当做参数传入,原理是相同的
15、Map集合
(1)与Collection的比较
Map集合不在Collection集合的继承体系中
实际开发中,例如学生类,我们存放的不应该只是每个学生的对象,还会有学号进行管理,获取学生信息时,大多是通过学号来进行的,但如果学号直接定义在学生类中,就意味着能拿到学号肯定也能直接拿到学生其他属性,学号就没有了存在的意义,所以Collection这样的单列集合很显然不满足我们的需求,Java提供了一种双列的集合,可以存放键值对的对象,能够将学号与学生的每个对象一一对应。
Map集合最大的特点就在于这个键值对,元素是成对出现的,数据结构仅针对键有效,跟值无关,键是唯一的,而值可以重复
Collection元素时单独出现的,数据结构针对每个元素有效,并有不同分支来存放是否有序和是否唯一的元素
(2)方法
put(key,value);添加映射关系,同时也是修改,当键存在时,值被替换
clear();清除所有映射关系,清空集合
remove(key);移除指定键的映射,返回对应的值,若键不存在,返回null
containsKey();判断是否包含指定键,也有containsValue判断是否含有值
get(key);根据键获取值
keySet();获取集合中键的集合,返回一个set集合,保证了元素唯一
value();获取集合中值的集合,返回一个collection集合,保证值可重复
entrySet();返回映射中包含映射关系的set视图
(3)遍历
方式一:keySet方法获取键的集合,通过get方法用键找值
Map m = new HashMap();
m.put("1", "hello");
m.put("2", "world");
m.put("3", "Java");
// 获取所有键,遍历键集合,根据键找值
Set s = m.keySet();
for (String key : s) {
System.out.println(key + "---" + m.get(key));
} 方式二:entrySet获取每个映射,遍历键值对集合,分别找到键和值
// 获取键值对对象,遍历键值对集合,找到键和值
Set> set = m.entrySet();
for (Map.Entry map : set) {
System.out.println(map.getKey() + "---" + map.getValue());
} 16、HashMap
(1)Map的实现类
基于哈希表的Map接口实现类,哈希表结构保证了元素唯一
理解Map之后,之前的例子也基本都是通过HashMap作为实现类来做,没什么特殊说明
(2)注意事项
如果使用自定义对象作为键值,与HashSet一样要注意重写自定义对象的hashCode和equals方法保证唯一性
(3)子类LinkedHashMap
结合了链表与哈希表结构,链表保证有序,哈希保证唯一,但都是针对键来说的,与值无关
17、TreeMap
(1)Map的另一个子类
同样根据TreeSet理解,红黑树结构,保证唯一性并且进行了排序
(2)排序
一样是两个方式,自然排序和比较器排序,跟TreeSet原理相同,只注意这个排序是针对键即可
一个例子,学生类对象作为键,根据名字进行排序,采用匿名内部类传递比较器参数
TreeMap map = new TreeMap(new Comparator() {
public int compare(Student s1, Student s2) {
int num = s1.getName().compareTo(s2.getName());//根据名字排序
int num2 = num == 0 ? s1.getAge() - s2.getAge() : num;//注意次要条件,同名按照年龄再进行排序
return num2;//返回0则表示键相同,put时变为替换值
}
}); 18、一些案例练习:
(1)输入一串字符,统计各字符出现的次数
思路:定义一个Map集合,将得到的字符串转换为数组,遍历该数组拿到每个字符去集合中找,找不到则将其定义为键,把对应值设定为1,找到则将对应值加一,这样遍历结束后Map中就存放了每个字符和对应的出现次数,并且为了保证按照字母的自然顺序进行结果输出,采用TreeMap进行存放
Scanner sc = new Scanner(System.in);
String line = sc.nextLine();//获取键盘录入字符串
TreeMap map = new TreeMap();
char[] arr = line.toCharArray();//转为数组并遍历
for (char ch : arr) {
Integer i = map.get(ch);//通过键找值
if (i == null) {
map.put(ch, 1);//找不到则添加这个映射,计数1
} else {
i++;
map.put(ch, i);//找到值+1后put修改
}
}
StringBuilder sb = new StringBuilder();
Set set = map.keySet();//获取键集合
for (Character key : set) {//增强for遍历
sb.append(key).append("(").append(map.get(key)).append(")");//按照一定的格式输出
}
System.out.println(sb); (2)Hashtable问题
Hashtable也是Map接口下哈希结构的子实现类
可以结合ArrayList与Vector来理解
Hashtable就相当于Vector,HashMap就相当于ArrayList
Hashtable键或值不能为null,而HashMap可以
Hashtable是线程安全,效率低,HashMap线程不安全,效率高
除了这两个区别,其他使用基本相同,同ArrayList理解相同,基本上HashMap是Hashtable的替代品
(3)集合继承的混淆
面试可能经常会问List、Set、Map是否都继承自同一个接口
如果不够熟悉,加上他们都是集合框架,就容易弄混
List、Set是Collection下的接口,Map本身就是顶层接口
19、Collections工具类
(1)针对集合操作的工具类
会经常被问到与Collection的区别,他们完全不同,一个是工具类,负责集合的操作;另一个是一个顶层集合接口
(2)方法
sort(List
binary(List
reverse(list);反转顺序
shuffle(list);随机洗牌
这些方法都是要List分支下子类才能使用,因为都需要有序才可以进行
max(c);获取最大值,也有获取最小值方法,集合都可以使用
20、集合框架总结
(1)单列集合Collection
List:元素有序,可重复,三个常见子类
ArrayList:底层数据结构为数组,查询快,增删慢,线程不安全,效率高
Vector:底层数据结构为数组,查询快,增删慢,线程安全,效率高
LinkedList:底层数据结构为链表,查询慢,增删快,线程不安全,效率高
Set:元素不保证有序,但唯一,两个常见子类
HashSet:底层数据结构为哈希表,依赖于hashCode与equals方法保证唯一;有一个子类LinkedHashSet,结合链表结构,实现了set集合的有序。
TreeSet:底层数据结构为红黑树,元素唯一并进行排序,默认进行自然排序,通过类实现comparable接口并重写compareTo方法,也可自定义排序器,通过匿名内部类重写compare方法实现。
(2)双列集合Map
Map:数据结构仅针对键有效,与值无关;键唯一,值可重复,两个常用子类
HashMap:哈希表结构,保证键唯一;有一个子类LinkedHashMap,通过链表结构实现了有序。
Hashtable:不常用子类,除了键值不能为null,其他用法与HashMap相同,并且线程安全,效率低,基本被代替
TreeMap:红黑树结构,通过compare保证键唯一和排序
(3)注意事项和问题
集合框架中的有序,都只是指传入和取出的顺序一致,而不是排序的顺序
集合框架的选择需要考虑需求:单列还是双列、是否需要有序,是否需要元素唯一、是否需要排序、线程安全与否、增删多还是查询多等等。使用较多的有:ArrayList 、HashSet 、HashMap
二、IO流
1、异常
(1)引入
IO流会产生很多异常,所以先要了解什么是异常
就是程序出现的不正常的情况
(2)分类
Throwable是所有问题和异常的超类
严重问题Error,不能进行处理,需要修改代码
异常问题Exception,有运行时异常,编译期间不报错,但运行起来就会出问题,这类异常一般也不进行处理,因为大多数因为自己的代码不够研究;除了运行时异常意外的异常,就是编译期异常,需要进行处理。
(3)处理异常方式
方式一:try...catch...finally块处理异常
注意事项:
原则上来说,try内的代码越少越好
catch中必须写内容,不处理也至少是信息的输出
多个catch块时,一个块捕捉到异常,则后面catch不再执行
平级异常顺序可以随意,但如果异常由继承关系,父类要在子类的后面catch
格式上,必须有try,catch和finally必有其一,catch可以有多个,finally只有一个
方式二:throws关键字抛出异常
在异常不能处理或不想处理,抛出异常让使用方法的人去处理,平时测试中会节省一些编写时间
注意事项:
抛出运行时异常,可以不进行处理
可以抛出多个异常,用逗号隔开
与throw关键字的区别
throws用在方法声明后,跟异常类名,可以有多个,逗号隔开;表示抛出异常,由方法调用者处理,是一种异常发生的可能性,而不是一定会发生
throw用在具体方法体内,后面跟异常对象,只能抛出一个;表示代码走到这里一定会抛出这个异常
(4)特别说一下finally关键字
在异常处理块中最后的位置,被finally控制的语句体不管是否发生异常都会执行(除非异常处理中使用了exit方法关闭了虚拟机),虚拟机关闭了则不执行。
与final和finalize的区别
final是修饰符,修饰类时表示不能被继承,修饰变量则是变为常量,修饰方法不能被重写
finally是异常处理中的一部分,可用于释放资源,一般情况下不管异常是否发生都会执行
finalize是Object中方法,用于垃圾回收。
finally与return的执行顺序问题
finally之前如果有return语句,finally依然会运行,但会在return前运行,不过这里其实只是这样说。真正的运行顺序,应该理解为,return拆分成两次,finally在两次之间运行,例子:
public static int getInt() {
int a = 10;
try {
System.out.println(a / 0);
a = 20;
} catch (ArithmeticException e) {
a = 30;
return a;//结果为30
} finally {
a = 40;
}
return a;
}分析:除以0之后,捕捉到异常,进入catch块,a赋值为30后返回了30,这里其实已经形成了一种类似映射的返回路径,相当于形成了return 30;这个语句,但finally要执行,a的值确实变为了40,但再次返回return时,还是走原来形成的返回路径,所以结果还是30.
(5)异常中的继承问题
子类只能抛出父类中相同的异常或其子类异常,不能抛出父类没有的异常、如果父类中一个异常都没有,子类只能自己用try...catch块处理,不能抛出。
2、File类
(1)IO包下的一个类
是文件和目录的抽象表达形式
(2)方法
creatNewFile();创建文件,返回true
mkdir();创建文件夹,如果存在则返回false
mkdirs();创建多级文件夹
delete();删除文件或目录,注意不走回收站
renameTo(File dest);重命名,需要file路径相同,如果路径不同,就相当于进行了剪切
方法总结似乎没什么用,自己看API就好,后面可能会简写了
有一些判断功能:是否是目录,是否是文件,是否存在等
获取功能:获取绝对路径、相对路径,获取文件名,获取字节数,获取最后一次修改时间
高级获取:listFile();获取目录下所有文件和目录的File对象数组
(3)过滤器接口
FilenameFilter文件名过滤器
list和listFile方法都可以以匿名内部类传入一个filter对象,例如想获取一个目录下txt后缀的文件:
String[] list = file.list(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
// TODO Auto-generated method stub
// 自己限定如何才返回true
// File file = new File(dir, name);
// boolean flag = file.isFile() && name.endsWith(".txt");// 是文件才加入list
// return flag;
//简洁写法
return new File(dir,name).isFile() && name.endsWith(".txt");
}
});3、递归
(1)引入
由于一个目录下,会有目录和文件,还会有多级目录,所以为了能够循环的去判断和操作,需要使用递归
(2)注意事项
递归一定要有出口,否则是死循环
递归次数不能太多否则会内存溢出
构造方法不能递归
(3)简单使用
经典的求阶乘
public static int getJc(int n) {
if (n == 1) {
return 1;
} else {
return n * getJc(n - 1);
}
}斐波那契问题:一串数字,从第三个数开始每个是前两个数相加
// 递归实现 返回 类型int,参数int n
// 出口 第一二月是1
public static int fib(int n) {
if (n == 1 | n == 2) {
return 1;
} else {
return fib(n - 1) + fib(n - 2);
}
}输出指定目录下所有java文件绝对路径
public static void getJava(File file) {
File[] files = file.listFiles();
for (File f : files) {
if (f.isFile()) {
if (f.getName().endsWith(".java")) {
System.out.println(f.getAbsolutePath());
}
} else if (f.isDirectory()) {
getJava(f);
}
}
}4、字节流
(1)抽象基类
InputStream、OutputStream
(2)输出流
FileOutputStream输出步骤
创建字节输出流对象
写数据(向文件中写数据,每次都重新写入,传入true作为第二个参数则为追加写入)
释放资源
(3)输入流
FileInputStream读入步骤
创建字节输入流对象
读数据(可以一次读一个字节,到达文件末尾返回-1,也可以一次读一个字节数组,数组长度一般设为1024的倍数)
关闭流
(4)缓冲流
利用了缓冲区,将字节输入输出流进行包装,可以进行高效传输
BufferedInputStream和BufferedOutputStream
不能直接对文件进行操作,因为只是一种高效的包装,还是需要传入字节流对象
这其实是一种装饰设计模式,最后再进行总结
5、字符流
(1)引入转换流
字节流在文本文件传输中,读出的数据可读性较差,所以针对一些中文的文本文件,Java提供了字符流
字符流其实是字节流加上编码表,所以需要一个转化流,实现字节流到字符流的转换
它是两个流的桥梁,可以指定编码和解码的字符集,默认使用平台的默认字符集
读写方法与字节流相同,但用的是字符和字符数组作为读写中介
(2)注意事项
字节流写入数据时,即使没有关闭流,数据也写入了
而字符流执行完写入操作,只是创建了文件
一个字符是两个字节(中文一般是三个负数),而文件中存储的基本单位是字节
所以执行完写入,写的字符都在缓冲区内
需要用flush()方法刷新一次缓冲区,才能写入数据
而close方法是关闭流,但关闭前其实内置了一次刷新方法
flush方法使用后流还能继续操作,close之后流对象不能再使用
(3)便携字符流
除了通过字节流转换为字符流,Java还提供了能直接操作文件的便携字符流
FileReader和FileWriter
(4)高效字符流
与字节流有高效流对应的,字符流也有高效缓冲流
BufferedReader和BufferedWriter,同样只是包装,不能直接操作文件,需要传入普通字符流对象
很方便的是,这个流可以直接读取文件的一行,写入时也有newLine方法可以换行
6、小结
/*
* IO流的字节与字符流小结
*
* 字节流
* 字节输入流InputStream--FileInputStream
* |--filter--BufferedInputStream传入字节流对象
* 字节输出流OutputStream--FileOutputStream
* |--filter--BufferedOutputStream
* 读写方法:read()/read(byte[] b)
* write(int content)/write(byte[] b,int off,int len)
*
* 转换流:
* 输入:InputStreamReader传入InputStream对象
* 输出:OutputStreamWriter传入OutputStream对象
* 实际传入的为字节流两个子类对象
*
* 字符流
* 字符输入流Reader--InputStreamReader--FileReader
* |--BufferedReader传入字符流对象
* 字节输出流Writer--OutputStreamWriter--FileWriter
* |--BufferedWriter
* 读写方法:read()/read(char[] c)
* write(int ch)/write(char[] c,int off,int len)
* 还可以直接写字符串write(String str)
* 特殊读写方法:readLine()
* newLine()
*
*/一些综合案例:
(1)将一个文件夹复制到指定目录下
public static void main(String[] args) throws IOException {
//数据源
File src = new File("源路径");
//目的地
File dest = new File("目标路径");
copy(src,dest);
}
public static void copy (File src,File dest) throws IOException {
//判断是否是文件夹
if(src.isDirectory()) {
//是文件夹先在目的地创建文件夹
File newFile = new File(dest,src.getName());
newFile.mkdir();
//获取源文件夹下所有文件
File[] fileList = src.listFiles();
//遍历递归
for(File file : fileList) {
copy(file,newFile);
}
} else {
//如果是文件,则复制文件
File newFile = new File(dest,src.getName());
copyFile(src,newFile);//字节流读写文件方式
}
}
private static void copyFile(File src, File newFile) throws IOException {
// TODO Auto-generated method stub
BufferedInputStream in = new BufferedInputStream(new FileInputStream(src));
BufferedOutputStream out= new BufferedOutputStream(new FileOutputStream(newFile));
byte[] b = new byte[1024];
int len;
while((len=in.read(b))!=-1) {
out.write(b, 0, len);
}
in.close();
out.close();
}(2)自定义类模拟BufferedReader的rendLine()方法
class MyBufferedReader {
private Reader reader;
public MyBufferedReader(Reader r) {
reader = r;
}
public String readLine() throws IOException {
StringBuilder sb = new StringBuilder();
int ch;
while ((ch = reader.read()) != -1) {
if (ch == '\r') {
continue;
}
if (ch == '\n') {
return sb.toString();
} else {
sb.append((char)ch);
}
}
//防止数据丢失
if(sb.length()>0) {
return sb.toString();
}
return null;
}
public void close() throws IOException {
reader.close();
}
}注意事项是有可能读取最后一行时,数据已经读到了缓冲区,但没有换行符,用来读取的字节返回了-1,无法通过换行符里的方法返回字符串并跳出循环,那么最后一行的数据就可能丢失,所以在循环外层最后加一个判断,如果缓冲区里还有字符,也进行一次return,这样就保证了数据完整
(3)自定义类模拟LineNumberReader获取行号的方法
class MyLineNumberReader {
private Reader reader;
private int lineNumber = 0;
public int getLineNumber() {
return lineNumber;
}
public void setLineNumber(int lineNumber) {
this.lineNumber = lineNumber;
}
...省略了与上个例子相同的代码
public String readLine() throws IOException {
lineNumber++;
...代码省略
}
}思路是定义一个行号的成员变量,在每次执行readLine方法时,将行号+1,设置和获取就是普通的get/set方法。
7、其他流的简单介绍
(1)针对基本数据类型的数据输入输出流DataInputStream和DataOutputStream
(2)内存操作流:将数据写入缓冲区,是暂时的数据,不需要关闭
操作字节ByteArrayInputStream和ByteArrayOutputStream
操作字符CharArrayReader和CharArrayWriter
操作字符串StringReader和StringWriter
(3)打印流:PrintStream和PrintWriter
有print()方法可以输出任何类型数据,println可以自动换行
构造方法可以传入第二个参数true开启自动刷新
(4)标准输入输出流:System类中的in和out字段
代表了输入输出设备,默认是键盘和显示器
System.in类型是InputStream
System.out类型是PrintStream,所以可以调用println方法,这就解释了最常用输出语句的原理
键盘录入数据的几种实现方式:
main方法中接收的args参数,最早期命令行界面传参数
Scanner对象传入System.in输入流
通过转换流包装System.in,再包装为缓冲流,利用readLine方法读取(输出流也可以这样包装)
(5)随机访问流RandomAccessFile
继承于Object类,不属于流但融合了流的输入输出功能
构造函数传入两个参数,第一个为文件路径,第二个是权限模式(结合linux权限“rwd”理解)
(6)合并流SequenceInputStream可以将两个或多个InputStream输入流同时读取
(7)序列化流与反序列化流
ObjectOutputStream和ObjectInputStream在流中对对象进行读写
对象类需要实现Serializable接口,启用序列化功能,该接口没有任何方法,此类接口被称为标记接口
注意事项:
在进行了一次序列化,存储到文件中之后,如果修改了类,会抛出一个异常InvalidClassException
这是因为此类实现了序列化之后,系统会默认给一个标记值serialVersionUID,修改之后这个标记值就改变了
只有重新存储之后,才能匹配;但实际中,不可能每次修改类都重新写入数据,可以自己限定这个UID
一般点击实现了接口后产生的黄色警告线让他自己生成一个固定的标记值即可
还有一个问题就是,不是所有成员属性都想被序列化,那么要用transient修饰这样的成员变量
8、Properties集合
(1)为什么要放在IO流里
他是Hashtable的子类,是属性集合类,可以和IO流集合使用
(2)特点
可以保存在流中或从流中读出键值对,每个键值对都是字符串,所以不使用泛型,双列都是字符串
集合中添加映射最好不要用put方法,因为有可能传入其他类型,应该用setProperty方法
因为不安全的properties集合对象(包含非String键值)中很多方法都会失效
(3)与流的结合使用
load(Reader reader)把文件中的键值对数据读入到集合中
store(Writer writer,String comments)把集合中数据存储到文件中,第二个参数是注释信息
9、NIO
jdk4出现的NIO使用了不同方式处理输入输出,采用了内存映射文件的方式,将文件或者文件的一段区域映射到内存中,像访问内存一样访问文件,这种方式比普通IO快很多,有Buffer和Channer类
jdk7下有一个接口Path,表示与平台无关的路径
工具类Paths,有一个get方法根据URI返回文件路径对象
工具类Files,copy方法可以直接复制文件,只需要传入源文件路径对象和输出流;write方法可以将集合数据写入文件。
NIO就是jdk升级中,将很多IO的操作变得更简单
三、多线程
1、线程
(1)进程
要了解线程,就要先了解进程,线程依赖于进程而存在
进程就是正在运行的程序,是系统进行资源分配和调用的独立单位
每一个进程都有自己的内存空间和系统资源
多线程的意义在于同一时间运行多个程序,可以同时做很多事,提高资源的利用率
但只是看起来是同一时间运行,单核cpu的一个时间点其实只能做一件事,是在多个进程间高速切换
(2)线程
一个进程中可以执行多个任务,每个任务就可以看成一个线程
线程是一个程序的执行单元,执行路径;是程序使用cpu的最基本单位
有多个执行路径的就是多线程程序,程序的执行其实是对cpu资源的抢夺
所以多线程的意义在于提高应用的使用率,多进程中哪个进程的线程比较多就更有可能有更高的执行权
但并不能保证,因为线程的执行有随机性
(多线程和多进程其实都不是提高效率,而是提高资源利用率)
(3)并行和并发
并行是逻辑上同时发生,指某个时间内同时运行多个程序
并发是物理上同时发生,指某个时间点同时运行多个程序
(4)Java程序的运行原理
启动Jvm,相当于启动了一个进程,然后程序会启动主线程调用main方法,但其实它的启动应该是多线程的,因为除了一个主线程,还应该至少有一个垃圾回收线程
(5)多线程的实现方式
方式一:继承Thread类,重写run()方法;创建线程对象,启动线程
启动线程中的问题:run和start的区别
run是封装在线程中被执行的代码,直接调用就跟普通方法调用没有区别
start则是启动这个线程对象,再由JVM去随机的调用各线程run方法
方式二:实现Runnable接口,重写run方法;创建自定义类对象,使用Thread带参构造传入这个对象,启动线程
这个方式的优势在于,很多时候我们的类本身需要有继承关系,而java没有多继承
实现接口就避免了这个限制,并且他把线程同程序代码、数据有效分离,较好的体现了面向对象思想
只需要创建一个对象,就可以开启多个线程,多个相同的代码处理同一资源,更符合多线程的要求
(6)线程类的方法
线程调度和优先级:java用的是一种抢占式调度
setPriority设置优先级,默认是5,范围是1-10。超过范围报异常IllegalArgumentException
线程控制:sleep,在指定毫秒内让线程暂停
join,等待该线程终止才运行其他线程
yield,礼让性暂停该线程,执行其他线程,但并不能保证一定礼让,只是更和谐
setDeamon,将该线程标记为用户线程,也称后台线程或守护线程,当正在运行的线程都是守护线程时,jvm退出,该方法的调用必须在启动线程前
stop,停止线程,不安全,已经过时因为后面的代码无法执行
interrupt,中断线程,把线程状态终止,抛出异常,后面的代码还能够运行
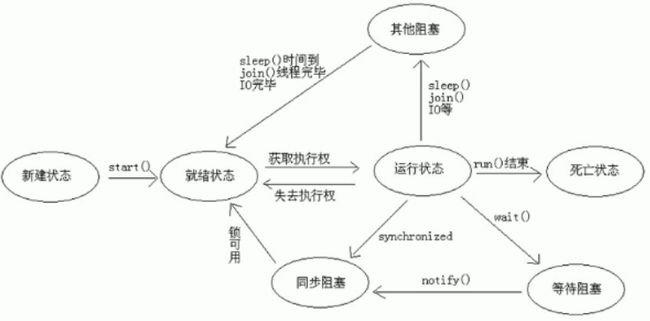
(7)线程生命周期
2、多线程中产生的问题
(1)同步问题
经典的多窗口卖票案例中,三个线程同时处理一个数据,即使限定了循环的跳出条件,但cpu的每次操作是原子性操作,类似票数--,这样的操作实际上并不是一步完成的,所以可能会出现多线程都能进入循环,出循环票数变负、或者同票卖多次的情况。这就是一种线程不安全的问题。
一般出现的原因有:多线程,共享数据,多条语句共同操作共享数据。
而这三个原因,前两个就是多线程的需求,不能通过更改他们来解决问题,所以着手于第三点,让这一块代码执行中,其他线程不能执行;java对此提供了同步机制。
同步代码块的关键字synchronized,格式是小括号里加锁对象,大括号内放需要同步的代码;同步解决安全问题的根本原因在于该锁对象上,可以在类中随意声明一个Object对象做为锁对象,但多个线程应该用同一把锁。
同步的特点:前提是多线程,且共用一把锁;好处是解决了多线程中的安全问题;弊端是当线程很多时,都需要去判断同步中正在使用的锁,很耗资源,降低了运行效率。
当想把一个方法定为为同步的,则在声明中加入synchronized关键字即可,但这时候,他的锁对象是this;如果这个方法是静态方法呢,本身this对象还没有被创建,方法随类的初始化而加载,其实此时锁对象是类的字节码文件本身,这是一种反射,后面还会总结。
(之前提过的Vector,虽然他是List集合下常用三个子类中唯一线程同步的集合,但是当我们需要使用线程安全的集合时,也不会去使用他,而是使用Collections工具类中的方法,将一个其他集合设置为同步集合来使用:List
Jdk5以后,提供了一个Lock接口,用具体实现类ReentrantLock创建一个对象,分别在需要上锁的地方和解锁的地方使用方法lock(),unlock()就可以实现同步了,更清晰的表达了加锁和释放锁。
(2)死锁问题
同步的弊端除了降低了效率,还有一个风险,如果出现了同步嵌套,容易产生死锁问题,指的是在多个线程执行过程中,因互相争夺资源而产生的互相等待现象;例如有两把锁,两边分别进入了一把锁之后,都需要对方解锁后才能继续运行,互相都在等待对方出来,一直僵持。写一个简单的死锁案例:
public class Test {
public static void main(String[] args) {
Thread td1 = new Thread(new DeadLock(true));
Thread td2 = new Thread(new DeadLock(false));
td1.start();
td2.start();//只有理想状态下,这两个才能顺利运行完毕
}
}
//定义两把锁
class MyLock {
public static final Object lock1 = new Object();
public static final Object lock2 = new Object();
}
//一个死锁案例
class DeadLock implements Runnable {
private boolean flag;
public DeadLock(boolean flag) {
this.flag = flag;
}
@Override
public void run() {
//当两个状态不同的线程,走这一段代码,分两条线走
//就可能出现互相等待对方使用的锁又都出不来的情况,即死锁
if (flag) {
synchronized (MyLock.lock1) {
System.out.println();
synchronized (MyLock.lock2) {
System.out.println();
}
}
} else {
synchronized (MyLock.lock2) {
System.out.println();
synchronized (MyLock.lock1) {
System.out.println();
}
}
}
}
}(3)生产者与消费者的问题
不同种类线程针对同一资源操作,由于线程随机性,可能会出现生产者还没生产,消费者就索取,同样也是线程安全问题,解决方法也是加锁,要注意的是不同种类线程加同一把锁。
但这个问题中,虽然加锁解决了同步,但还会有其他情况出现,由于线程调度的随机性,消费者先抢到执行权,但生产者还没生产,数据还处在默认值,就应该通知生产者,并且等待生产完毕再消费;如果生产者抢到执行权,生产完毕后,如果还有执行权,就应该通知消费者来使用,等消费完再生产,而不是一直生产。
对此,java中提供了等待唤醒机制,Object类中有三个方法:wait()/notify()/notifyAll().而这三个方法为什么要定义在Object中,原因是这些方法需要同步中的锁对象来进行调用,而在同步代码块中,这个锁对象可以是任意对象,所以兼容所有对象的Object可以完成这个任务。一个简单的例子:
public class Test2 {
public static void main(String[] args) {
Student s = new Student();
Thread td1 = new Thread(new setStudent(s));
Thread td2 = new Thread(new getStudent(s));
td1.start();
td2.start();
}
}
// 学生类
class Student {
// 方便操作数据
String name;
int age;
// 加一个标记
boolean flag;// 默认是false,代表没数据
}
//生产者
class setStudent implements Runnable {
Student s;
int x;
public setStudent(Student s) {
this.s = s;
}
@Override
public void run() {
while (true) {
synchronized (s) {
if (s.flag) {
// 如果有数据,生产者等待数据被消费
try {
s.wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (x % 2 == 0) {
s.name = "学生A";
s.age = 23;
} else {
s.name = "学生B";
s.age = 22;
}
x++;
// 生产完毕,修改标记,唤醒消费者
s.flag = true;
s.notify();
}
}
}
}
//消费者
class getStudent implements Runnable {
Student s;
public getStudent(Student s) {
this.s = s;
}
@Override
public void run() {
while (true) {
synchronized (s) {
if (!s.flag) {
// 没有数据,消费者就等待
try {
s.wait();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
System.out.println(s.name + "---" + s.age);
// 消费完毕,修改标记,唤醒生产者
s.flag = false;
s.notify();
}
}
}
}3、线程组
可以使用ThreadGroup表示线程组,可以对一批线程进行分类管理
默认情况下,所有线程属于主线程组
给线程设置分组可用Thread类中一个构造方法Thread(ThreadGroup group,Runnable target,String name)
4、线程池
启动新线程的成本较高,因为涉及到与系统功能的交互,而使用线程池可以很好的提高性能,尤其是要创建大量生存周期短的线程时,更要考虑线程池;池中每个线程代码结束后,不会死亡,而是回到池中成为空闲状态,等待下一个对象来使用。
* Executors工厂类产生线程池
* newCachedThreadPool()空线程池
* newFixedThreadPool(int nThreads)创建存放n个线程的线程池
* newSingleThreadExecutor()存放一个线程的池
* 这些方法返回一个ExecutorService对象
* 这种线程池可以执行Runnable对象或Callable对象代表的线程
*
* 线程池使用过程:
* 静态方法传入想要管理的线程数量
* 定义一个实现了Runnable接口的类
* 调用方法Future submit(Runnable task)
* 要结束线程池,用shutdown方法这里提到了第三种实现线程的方式,依赖于线程池,可以使用泛型,所以不经常提:就是类实现Callable接口重写call方法。
5、匿名内部类方式使用线程
如果线程中代码较少,使用次数不多,其实可以不用专门定义一个类去继承或实现接口,可以直接通过匿名内部类,重写Thread中的run方法,或传入接口子实现对象,同样重写run方法。要注意的是,如果同时重写了两个run,执行时是走Thread中的方法。例如:
// Thread类
new Thread() {
@Override
public void run() {
System.out.println("helloworld");
}
}.start();
// Runnable接口
new Thread(new Runnable() {
public void run() {
System.out.println("helloworld");
}
}) {
}.start();
// 两个大括号中都重写run呢?
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("helloworld");
}
}) {
@Override
public void run() {
System.out.println("helloJava");
//线程运行走这里的run
}
}.start();6、Timer定时器
应用广泛的线程工具,可用于调度多个定时任务以后台线程方式执行,但开发中其实是用其他更好的开源框架。
简单使用:一个Timer对象,一个TimerTask任务,通过schedule方法传相应参数设定任务时间。
一个定时删除指定文件夹的例子,应用了递归和定时任务:
public class Test1 {
public static void main(String[] args) {
Timer t = new Timer();
DeleteFiles task = new DeleteFiles();
t.schedule(task, 1000);
}
}
class DeleteFiles extends TimerTask {
@Override
public void run() {
File file = new File("指定目录");
delete(file);
}
public void delete (File file) {
if (file.isDirectory()) {
File[] files = file.listFiles();
for(File f : files) {
delete(f);
}
} else {
file.delete();
}
//删完文件删文件夹
file.delete();
}
}更好的改进是,构造方法传入文件对象。这里只是简单测试
7、总结
(1)多线程实现方式:继承Thread类或实现Runnable接口,重写run方法。(Callable了解)
(2)synchronized关键字实现同步,注意锁对象的使用
(3)注意run和start方法区别,一个是普通调用,另一个才是启动线程
(4)sleep与wait区别:前者必须指定时间,并且睡眠期间不会释放锁;后者不指定时间,用notify唤醒,等待期间会释放锁。
(5)为什么notify、wait、notifyAll定义在Object类中:锁对象的随意性。
(6)线程生命周期:新建、就绪、运行、死亡。运行中可能因为各种原因发生阻塞。
四、网络编程
1、网络相关知识
* 网络模型:计算机网络之间以何种规则进行通信
* OSI:open system interconnection开放系统互联
* TCP/IP参考模型
*
* 七层网络结构
* 应用-表示-会话-传输-网络-数据链路-物理
*
* 网络应用程序组成:网络编程、IO流、多线程(还应该有集合)
*
* 网络编程三要素
* IP地址
* 网络中计算机的唯一标识,用点分十进制技术表示
* IP组成:网络号段+主机号段
* 分类:A-E五类,一般是C类,前三段为网络号+后一段主机号,一个网络号256个
* 其中一般192.168.x.x和10.x.x.x为私有地址,配置局域网用
* 常用dos命令:ipconfig、ping
* 特殊地址:127.0.0.1为本机(回环地址)x.x.x.255广播地址 x.x.x.0网络地址
* 端口
* 这里指的是逻辑端口,每个网络程序都至少有一个逻辑端口
* 是用于标识进程的逻辑地址,不同进程的标识
* 有效端口:0-65535,其中0-1024为系统使用或保留端口
* 协议
* 通信的规则
* UDP:数据打包,大小限制,不需要建立连接,不可靠,但速度快
* TCP:通过三次握手建立连接,可进行大数据量传输,可靠,但效率稍低
* 一般软件都是两种协议都有,tcp保证安全,udp保证速度
* 举例:发短信、qq、微信发消息为udp,需要接听的电话为tcp2、前提知识
(1)InetAddress类
java中表示IP的类,没有构造方法,有一个方法返回该类对象getByName(String name),根据主机名或IP获取对象
(2)Socket套接字
网络上具有唯一标识的IP地址和端口号组合在一起,构成能够唯一识别的标识符套接字
通信的两端都会有socket,网络通信的其实就是数据在socket之间通过IO流传输
3、UDP协议
(1)不需要连接
数据打包,大小有限制,不可靠但速度快;不保证投递,发送端可以直接运行
(2)发送数据的步骤
创建发送端Socket对象
创建数据,打包数据
调用socket对象方法发送数据包
释放资源
* UDP协议用DatagramSocket类,发送和接收端都使用此对象
* 有一个send方法用于发送数据,传入DatagramPacket对象
* DatagramPacket类表示数据包,实现无连接包投递服务,不对投递做出保证
* 包含信息有数据、其长度、远程主机IP和端口号,可通过构造方法传递(3)接收端
创建接收端Socket对象,提供端口
创建一个数据包用于接收数据
调用方法接收数据
解析数据
释放资源
接收端运行之后,receive方法是一个阻塞式方法,直到接收到数据才会继续向下运行。
(4)多线程实现控制台的简单聊天室程序
public class Test {
public static void main(String[] args) throws IOException {
DatagramSocket sendDs = new DatagramSocket();
DatagramSocket receiveDs = new DatagramSocket(10005);
SendSocket s = new SendSocket(sendDs);
ReceiveSocket r = new ReceiveSocket(receiveDs);
Thread td1 = new Thread(s);
Thread td2 = new Thread(r);
td1.start();
td2.start();
}
}
// 发送端
class SendSocket implements Runnable {
private DatagramSocket ds = null;
public SendSocket (DatagramSocket ds) {
this.ds = ds;
}
@Override
public void run() {
try {
// 录入数据
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String text = null;
while ((text = br.readLine()) != null) {
if ("88".equals(text)) {
break;
}
//包装数据
byte[] b = text.getBytes();
DatagramPacket dp = new DatagramPacket(b,b.length,InetAddress.getByName("127.0.0.1"),10005);
ds.send(dp);
}
...省略异常处理代码
} finally {
if (ds != null) {
ds.close();
}
}
}
}
// 接收端
class ReceiveSocket implements Runnable {
private DatagramSocket ds = null;
public ReceiveSocket (DatagramSocket ds) {
this.ds = ds;
}
@Override
public void run() {
try {
while (true) {
// 创建接收数据包
byte[] b = new byte[1024];
DatagramPacket dp = new DatagramPacket(b, b.length);
ds.receive(dp);
// 解析数据
String s = new String(dp.getData(), 0, dp.getLength());
System.out.println(dp.getAddress().getHostName() + ":" + s);
}
}...省略异常处理块
}
}(1)需要三次握手,必须进行连接
协议可靠,但效率较低
(2)发送端-Client客户端
创建Socket对象
获取输出流,写数据
释放资源
不能直接运行,要有接收端建立连接
(3)接收端-Sever
创建Socket对象
监听客户端,返回一个对应的socket对象,accept为阻塞式方法
获取输入流,读数据
释放资源
(4)上传文件例子
客户端
public static void main(String[] args) throws IOException {
//创建客户端socket对象
Socket s = new Socket("127.0.0.1",10005);
//获取图片文件流,需要用字节流
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("test.jpg"));
//包装通道内输出流,也是字节流
BufferedOutputStream bos = new BufferedOutputStream(s.getOutputStream());
//发送数据
byte[] b = new byte[1024];
int len;
while((len=bis.read(b))!=-1) {
bos.write(b, 0, len);
bos.flush();
}
//提醒服务器端,传输完毕
s.shutdownOutput();
//接收反馈
BufferedReader br = new BufferedReader(new InputStreamReader(s.getInputStream()));
System.out.println(br.readLine());
//释放资源
bis.close();
s.close();
} public static void main(String[] args) throws IOException {
//创建服务器端socket对象
ServerSocket ss = new ServerSocket(10005);
//监听客户端连接
Socket s = ss.accept();
//包装通道内输入流
BufferedInputStream bis = new BufferedInputStream(s.getInputStream());
//文件输出流
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.jpg"));
//读取数据,并保存
byte[] b = new byte[1024];
int len;
while((len=bis.read(b))!=-1) {
bos.write(b, 0, len);
bos.flush();
}//接收到shutdown提示,跳出循环
//反馈信息
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(s.getOutputStream()));
bw.write("上传成功!");
bw.flush();
//释放资源
bos.close();
s.close();
}五、反射
1、类加载
* 当程序要使用某个类是,该类还未被加载到内存中,则系统会通过
* 加载、连接、初始化三步来实现对这个类进行初始化。
*
* 加载
* 就是指任何类使用时都会将class文件读入内存,并为之创建一个Class对象
*
* 连接
* 验证,是否有真正的内部结构,并和其他类协调一致
* 准备,负责类的静态成员分配内存,并设置默认初始化值
* 解析,将类的二进制数据中的符号引用替换为直接引用
*
* 初始化时机
* 创建类实例
* 访问类的静态变量或为其赋值
* 调用类的静态方法
* 使用反射方式强制创建某个类或接口对应的java.lang.Class对象
* 初始化某个类的子类时
* 直接使用java.exe命令运行某个主类
*
* 类加载器
* 负责将.class文件加载到内存中,并为之生成对应Class对象
* 而java自带类与自己写的类肯定是不同加载器来完成的
*
* 分类:
* Bootstrap ClassLoader根类加载器:java核心类加载,jdk/jre/lib/rt.jar
* Extension ClassLoader扩展类加载器:jdk/jre/lib/ext目录的扩展包加载
* System ClassLoader系统类加载器:来自java命令的class文件(也就是自己写的类)以及classpath指定的jar包2、反射
(1)定义
在运行状态中,对于任意一个类任意一个对象,都能知道他们的所有属性和方法,这种动态获取信息以及动态调用对象方法的机制就是反射
(2)与new对象的区别
平时是new一个某类对象后,通过这个对象去调用成员
而反射是通过Class文件对象,使用文件中的成员变量、构造方法和成员方法
并且将这些成员都看做类,再通过他们的对象分别来使用
(3)获取类对象的方式
Object类中的getClass方法
数据类型的静态属性class
Class类中静态方法forName,返回该类名的字节码文件对象
(方式三获取对象时,要注意写类的全称,即包括包名;一般放在配置文件中进行读取)
(4)一些应用
通过配置文件运行类中的方法的案例:
//通过键值对集合读取配置文件
Properties prop = new Properties();
prop.load(new FileReader("class.txt"));
String className = prop.getProperty("className");
String methodName = prop.getProperty("methodName");
//根据配置创建字节码文件对象
Class c = Class.forName(className);
Constructor con = c.getConstructor(String.class,int.class);
Object obj = con.newInstance("学生",23);
Method m = c.getMethod(methodName);
m.invoke(obj);
System.out.println(obj);
使用了Properties集合,读取键值对,这里我配置文件里写了一个学生类全名和一个简单的输出方法名,这种反射的方式虽然第一次编写代码会复杂一些。但如果想要对其他类的其他某个方法再这样使用时,只需要修改配置文件中键的对应值即可。为后期维护节省时间。并且能够隐藏设计细节,符合面向对象思想。
通过反射越过泛型检查案例:
//给出一个ArrayList对象,泛型限定存放的数据类型
ArrayList list = new ArrayList();
//反射获取集合字节码对象
Class c = ArrayList.class;
//提取add方法
Method m = c.getMethod("add", Object.class);
//尝试加入
m.invoke(list, "hello");
//输出
System.out.println(list); 通过反射get到的add方法,是不带泛型的原本方法,参数可以传递任意类型,所以能够绕过泛型检查,添加成功,并且编译期和运行时都不会报错。
通过泛型写一个方法可将一个obj对象的名为propertyName的属性值设置为value的案例:
public static void setProperty(Object obj, String propertyName, Object value) {
// 获取该对象的字节码文件对象
Class c = obj.getClass();
try {
//获取该成员变量
Field f = c.getDeclaredField(propertyName);
//暴力访问权限
f.setAccessible(true);
//设置方法
f.set(obj, value);
} catch (Exception e) {
e.printStackTrace();
}
}(5)动态代理
/*
* 代理:本该自己做的事,让别人去做,这个人就是代理对象
* 动态:在程序运行过程中产生的这个对象,其实就是通过反射来生成一个代理
*
* 在Java中java.lang.reflect包下有一个Proxy类和一个InvocationHandler接口
* 通过他们就可以生成动态代理对象,但JDK提供的这个代理只能对接口进行代理
* 开发中还有更强大的cglib
*
* Proxy类中方法创建动态代理对象
* public static Object newProxyInstance
* (ClassLoader loader,Class[] interfaces,InvocationHandler h)
* InvocationHandler接口方法
* Object invoke(Object proxy,Method method,Object[] args)
*
*/
public class TestA {
public static void main(String[] args) {
// 接口调用测试
UserDao ud = new UserDaoImpl();
// 开发中,这些增删改查操作应该是有权限的,并且应该有操作记录
// 修改时,又不应该直接修改原来的代码,要创建新的类来实现
// 并且每个操作所需要添加的权限校验和操作记录是重复代码
// 就应该有类似中介的东西,专门实现这两个功能
// 创建一个动态代理对象
// 第一个参数通过class对象获取loader对象
// 第二个 参数 也是通过class对象获取接口对象
// 第三个参数,传自定义handler的对象
Object proxy = Proxy.newProxyInstance(ud.getClass().getClassLoader(), ud.getClass().getInterfaces(),
new MyInvocationHandler(ud));
//并且这个对象应该是上面的UserDao对象,进行向下转型
UserDao udwp = (UserDao) proxy;
udwp.add();
udwp.delete();
udwp.update();
udwp.select();
//并且这个中介可以对其他接口复用
}
}
// 自定义一个handler
class MyInvocationHandler implements InvocationHandler {
private Object target;// 目标对象
// 写一个带参构造
public MyInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// Method对象调用方法,传入目标对象和参数
// 方法的上下位置编写中介要做的事
// 应返回object对象,所以obj接收
System.out.println("权限校验");
Object result = method.invoke(target, args);
System.out.println("日志记录");
return result;// 其实就是返回代理对象
}
}
// 假设有一个用户操作接口
interface UserDao {
// 增
public abstract void add();
// 删
public abstract void delete();
// 改
public abstract void update();
// 查
public abstract void select();
}
// 一个用户操作接口实现类
class UserDaoImpl implements UserDao {
public void add() {
System.out.println("添加");
}
public void delete() {
System.out.println("删除");
}
public void update() {
System.out.println("修改");
}
public void select() {
System.out.println("查找");
}
}六、JDK新特性总结
(1)JDK5
自动拆装箱、泛型、增强for、静态导入、可变参数、枚举
说一下枚举,关键字enum实现枚举类
优点是声明枚举常量的语句会省略很多,并且默认实现了toString方法
可以自己定义带参构造,声明只要在常量后面括号里传参数即可
可以有抽象方法,在声明后面用匿名内部类实现
一个简单的枚举类:
enum Direct {
//直接写常量
// FRONT,BACK,LEFT,RIGHT;
//还可以自己定义带参构造,常量声明也不同
//有抽象方法,同样用匿名内部类实现
FRONT("前"){
public void show() {
System.out.println("向前");
}
},BACK("后"){
public void show() {
System.out.println("向后");
}
},LEFT("左"){
public void show() {
System.out.println("向左");
}
},RIGHT("右"){
public void show() {
System.out.println("向右");
}
};
//成员变量
private String name;
//带参构造
private Direct(String name) {
this.name = name;
}
//普通方法
public String getName() {
return name;
}
//抽象方法
public abstract void show();
}注意事项:所有枚举类都是Enum子类;枚举类第一行必须是枚举项,最后一个分号可以省略,但如果后面有其他内容,则不能省略,建议都写上;可以自定义构造方法,但必须是private的;可以有抽象方法,在枚举项后面通过匿名内部类实现;枚举在switch语句中是直接使用,不要当成字符串。
(2)JDK7新特性
二进制字面量:可以二进制表示整数,在二进制数前面加0b
数字字面量可以出现下划线:长数字可以用下划线分隔方便阅读,但不能加在特殊位置(标识与数值间、开头结尾、小数点旁边等)
switch:可以使用字符串
泛型简化:前面引用写了泛型之后,new对象时可以直接用<>省略,但建议还是写出来好
异常的多个catch可以合并:catch后括号里用“|”隔开,多个异常必须是平级关系
try...with...resources语句:try后面括号里添加需要关闭的创建对象语句,大多是流体系对象放在这里,这样就可以自动释放资源,不需要finally写close()了。
(3)JDK8新特性
接口中除了抽象方法,可以有default和static方法了
(4)9去年出了,但自己的水平似乎还用不到新特性,在其他网页上搜了一下,大概了解
(5)10也在近期发布了,感觉离自己还很远,加油吧
七、设计模式
1、设计原则
* 实际开发中,要熟悉前人总结过的面向对象思想的设计原则
*
* 单一职责原则:就是常说的低耦合,高内聚。
* 每个类应该只有一个职责,对外只提供一种功能,引起变化的原因应该只有一个
*
* 开闭原则:一个对象对扩展开放,对修改关闭
* 把可能变化的内容抽象出来,使类相对稳定不去修改,而对其具体实现改变或扩展
*
* 里式替换原则:在任何父类出现的地方都可以用它的子类替换
* 其实就是同一个继承体系中的对象应该具有共同的行为特征
*
* 依赖注入原则:依赖于抽象,不要依赖于具体实现
* 要求我们在编程时针对抽象类或者接口编程,而不要针对具体实现编程
*
* 接口分离原则:不应该强迫程序依赖他们不需要的方法
* 一个接口不要提供太多行为,应该只提供一种对外功能,将多个操作分离多个接口
*
* 迪米特原则:一个对象应当给对其他对象尽可能少的了解
* 其实就是低耦合,提高系统维护性,模块之间应该只通过接口编程
*
* 都是为了提高扩展性,维护性,复用性2、简单工厂模式
(1)又称为静态工厂方法模式,定义一个具体的工厂类负责创建类的实例
优点是客户端不需要再负责对象创建,明确了各个类的职责
缺点是这个工厂负责所有对象的创建,如果有新的对象增加,或者对象创建方式不同
就需要不断修改工厂类,不利于后期维护
(2)例子:
// 了解简单工厂模式思想
abstract class Animal {
public abstract void eat();
}
class AnimalFactory {
// 提供静态方法,私有构造函数,不去创建对象
private AnimalFactory() {
}
// 利用多态
public static Animal creatAnimal(String type) {
if ("dog".equals(type)) {
return new Dog();
} else if ("cat".equals(type)) {
return new Cat();
} else {
return null;
}//如果有其他类需要用工厂模式,就需要不断修改这里的代码
}
}
class Dog extends Animal {
@Override
public void eat() {
System.out.println("狗吃肉");
}
}
class Cat extends Animal {
public void eat() {
System.out.println("猫吃鱼");
}
}3、工厂方法模式
(1)抽象工厂类为接口,负责定义一个创建对象方法
具体每个类的创建工作由实现了工厂接口的具体类来实现
优点除了与简单工厂模式相同的好处之外,解决了它的不足,有新的对象时,只需要添加对应的子类工厂,不影响已有的代码,维护容易,增强了系统的扩展性
弊端就是代码更多,增加工作量
(2)例子:
//工厂接口
interface Factory {
public abstract Animal createAnimal ();
}
//抽象父类
abstract class Animal {
public abstract void eat();
}
//动物子类
class Dog extends Animal {
public void eat() {
System.out.println("狗吃肉");
}
}
class Cat extends Animal {
public void eat() {
System.out.println("猫吃鱼");
}
}
//工厂实现类
class DogFactory implements Factory {
public Animal createAnimal () {
return new Dog();
}
}
class CatFactory implements Factory {
public Animal createAnimal() {
return new Cat();
}
}4、单例模式
(1)确保类在内存里只有一个对象,该对象必须自动创建,对外提供
优点是只有一个对象会节省系统资源,对于一些需要频繁创建销毁的对象可以提高性能
缺点是没有抽象层,扩展性差,职责过重,一定程度的违背了单一职责的原则
(2)如何保证内存中只有一个对象
私有构造方法、在成员位置创建一个对象、给出公共方法提供对象的访问。
(3)分类
饿汉式单例模式:
class Student {
//禁止直接修改,加私有
private static Student s = new Student();
//私有构造方法,禁止外界创建对象
private Student () {
}
//提供公共访问方法,并且应该静态,可以通过类名调用
public static Student getStudent() {
return s;
//并且,静态方法只能访问静态成员,成员变量也要静态修饰
}
}饿汉式就是对象在类加载时就创建了,开发中多用这种,一般不会出现问题
懒汉式单例模式:
class Teacher {
//同样的私有静态修饰,保证只有一个不能直接修改的对象,但先不创建
private static Teacher t = null;
//私有构造
private Teacher () {
}
//同样用公共静态修饰方法,提供给外界,但此时才创建对象
public synchronized static Teacher getTeacher() {
if (t==null) {
t = new Teacher();
}
return t;
}
}这里要注意的是懒加载思想,延迟加载,用的时候才去创建对象;会出现一个线程安全问题因为在多线程中,在方法里创建对象属于多条语句操作了共享数据,如果多个线程同时走到方法中,会有很多对象被创建,所以要在方法中加同步关键字synchronized,才是最终版本的懒汉式。
(4)Runtime类
Java中使用了单例模式思想的一个类,每个java程序都应该有一个Runtime实例,使应用程序能够与其运行的环境连接,可以通过getRuntime方法获取当前运行时。一个简单的方法使用:
Runtime r = Runtime.getRuntime();
//有一个方法,可以执行dos命令,很有意思
r.exec("git-bash");
5、适配器设计模式
(1)一个接口中如果提供了多个方法,但我们实现他们时,只想用其中一种方法,却要把所有方法都实现,即使是空实现;似乎很不方便,这个时候就可以先定义一个适配器类,实现该接口的所有方法空实现,再使用该适配器类,就可以选择性的重写我们需要的方法了。
(2)Gui中各种Listener都是用了这样的思想,传入一个适配器匿名内部类,只重写需要的方法即可。
6、模板设计模式
(1)定义一个算法的骨架,其中含有一部分是抽象方法;具体的实现延迟到子类中。
优点是定义算法骨架的同时,灵活的利用算法,满足多变的需求
缺点是如果算法本身需要修改,则需要改动抽象类
(2)例子:
abstract class Tool {
public long getTime() {
// 计算一个代码块的执行时间
long start = System.currentTimeMillis();
code();//把这块代码封装,然后通过子类对象调用该方法
long end = System.currentTimeMillis();
return end-start;
}
//封装为抽象方法,同时类也要抽象
public abstract void code();
}
//使用模板,把需要测试的代码块写到子类重写的code方法中
class ForTest extends Tool {
@Override
public void code() {
for (int i = 0;i<10000;i++) {
System.out.println(i);
}
}
}7、装饰设计模式
(1)使用被装饰的子类实例时,把这个实例交给装饰类,是继承的替代方案
优点是比继承更为灵活,提供多种扩展功能,并且能够随意组合
缺点是正因为太灵活,可能会有逻辑上的不合理
(2)java中IO流的字节流通过转换流变成字符流,再通过缓冲流包装提高效率,其实就是一种装饰模式思想;Scanner的使用,传入System.in输入流,也是这个思想。
(3)例子:
public class Test {
public static void main(String[] args) {
//单装饰类使用
PhoneDecorate phoneDecorated = new CallPhoneDecorate(new Iphone());
phoneDecorated.call();
//多装饰类任意组合,嵌套传入装饰即可
PhoneDecorate pd = new CallPhoneDecorate(new MusicPhoneDecorate(new Iphone()));
pd.call();
}
}
// 举例,一个手机接口
interface Phone {
// 基本功能,打电话
public abstract void call();
}
// 具体的手机类,应该有更多扩展功能,用装饰来实现
class Iphone implements Phone {
public void call() {
System.out.println("打电话");
}
}
// 手机功能应该有装饰,也实现手机接口,先抽象一个总装饰类
abstract class PhoneDecorate implements Phone {
// 需要装饰的手机成员变量
private Phone p;
// 构造函数传入要装饰的手机
public PhoneDecorate(Phone p) {
this.p = p;
}
// 也应有基本功能
public void call() {
this.p.call();
}
}
// 具体装饰:例如打电话前应有彩铃
class CallPhoneDecorate extends PhoneDecorate {
public CallPhoneDecorate(Phone p) {
super(p);
}
public void call() {
//装饰一个其他功能
System.out.println("有彩铃");
//继承基本方法
super.call();
}
}
//假设打电话后去听音乐,第二个具体装饰
class MusicPhoneDecorate extends PhoneDecorate {
public MusicPhoneDecorate(Phone p) {
super(p);
// TODO Auto-generated constructor stub
}
public void call() {
super.call();
System.out.println("听音乐");
}
}八、最后的总结
半个月的时间,回顾了SE基础,下个月巩固web知识,最后看一看框架。
还有两个月毕业,希望最后的挣扎能让我扳回一城。