qq音乐推荐下载器(一)——模拟搜索,下载,读取评论制作词云并将下载数据传至数据库
模拟qq音乐网页的搜索和下载功能
第一步:模拟搜索功能
其中需要掌握request库进行爬虫
关键是获取存有歌曲信息的地址
其中第一个url的获取不能直接复制搜索网址
我在一开始直接使用搜索网址,发现无论搜什么,都是

第一个url要通过F12,获得调试网页的开发者工具,在Network中的XHR中找到文件client_search

其中的Request URL就是我们需要的歌曲信息地址,通过多次搜索,我们可以发现地址中的变量的作用,最后得到
‘https://c.y.qq.com/soso/fcgi-bin/client_search_cp?p=1&n=10&w=%s’%(name)
其中第一个p是第一页,第二个p是搜索条数,w是搜索名
以下是搜索对象函数代码
def searchMusic(self): #搜索歌曲或歌手信息
try:
name = input("请输入歌名或者歌手:")
#导入相关信息
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?p=1&n=10&w=%s'%(name)
html = self.getHTMLText(url).text
#解码
html = html[9:]
html = html[:-1]
js = json.loads(html)
#获取歌曲信息
songlist = js['data']['song']['list']
#访问song字典
for song in songlist:
songmid = song['songmid']
songname = song['songname']
songsinger = song['singer'][0]['name']
songid = song['songid']
self.songname.append(songname) #获取歌曲名信息
self.songsinger.append(songsinger) #获取歌手信息
self.songid.append(songid) #获取歌曲id用以获取评论地址
self.songmid.append(songmid) #获取歌曲mid用以获取歌曲下载地址
if song['pay']['paydownload']: #获取歌曲VIP信息,打印歌曲实现搜索功能
self.songlist.append([songname,songsinger,songmid,'[VIP]'])
print(songname,songsinger,songmid,'[VIP]')
else:
self.songlist.append([songname,songsinger,songmid])
print(songname,songsinger,songmid)
except:
print("搜索功能出错!")
第二步:模拟下载功能
这一步骤的关键是得到下载地址
其中我们需要获得key_url和url
首先随便找首歌播放进入播放页面,F12+F5
在其中通过size找到最大的type是media的


我们想要下载这个文件,需要找到它的地址,其中uin和guin登录后获得,不同歌曲的vkey不同,显然我们要找到放vkey的地方,而文件中刚好有一个get vkey
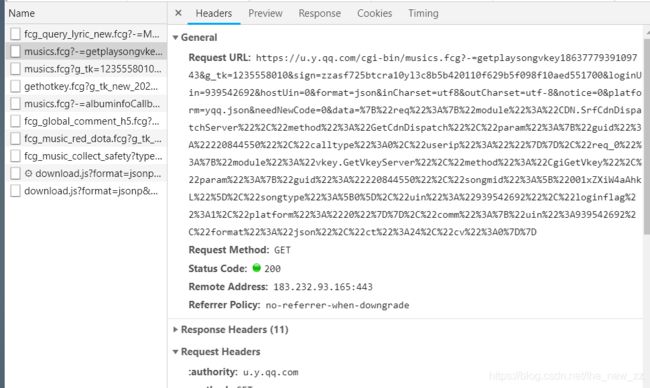
进入这个url,就可以找到purl

拼接后得到下载地址,具体代码如下
def downloadMusic(self): #下载音乐
try:
want = int(input('您想下载第几首歌曲(1-10):'))
self.want = want
#排除VIP歌曲
while want<=0:
print("数据错误!,请重新输入一个大于0的数")
while ['VIP'] in self.songlist[want-1]:
want = int(input('抱歉,VIP歌曲无法下载,请重新输入想下载的歌曲:'))
print('获取歌曲资源中,请稍等...')
#获取purl链接
key_url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?&data={"req":{"param":{"guid":"220844550"}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"220844550","songmid":["%s"],"uin":"2212"}},"comm":{"uin":2212}}'%(self.songmid[want-1])
html = self.getHTMLText(key_url).text
#解码
key_json = json.loads(html)
final_url =key_json['req_0']['data']['midurlinfo'][0]['purl']
#拼接url获得下载地址
url = 'http://dl.stream.qqmusic.qq.com/' + final_url
print("成功获取资源!")
print("正在下载歌曲中......")
#设置下载名称
name = self.songlist[want-1][0] + '-' + self.songlist[want-1][1] + '-' + self.songlist[want-1][2]
music = self.getHTMLText(url).content
with open(name + '.mp4','wb') as f:
f.write(music)
print("成功下载歌曲!")
f.close()
except:
print("下载音乐出错!")
传入数据库代码
def connectDataBase(self):
print("开始连接数据库...")
#连接数据库
db = pymysql.connect(host='localhost', user='root', password='root', port=3306, db='qqmusic', charset='utf8')
cur = db.cursor()
print("成功连接数据库")
sqlc = ''' #创建音乐下载表
create table if not exists download(
id int(20) not null auto_increment primary key comment '编号',
songname varchar(20) not null comment '歌曲名',
songsinger varchar(20) not null comment '歌手',
songmid varchar(30) not null comment '歌曲mid'
)'''
cur.execute(sqlc)
warnings.filterwarnings('ignore') #用于忽视重复建表警告
songname = self.songname[self.want-1]
songsinger = self.songsinger[self.want-1]
songmid = self.songmid[self.want-1]
#插入数据,可检测重复下载
sqli = '''replace into download(songname,songsinger,songmid)
values('%s','%s','%s')''' % (songname, songsinger, songmid)
try:
cur.execute(sqli)
db.commit()
print("导入数据库成功!")
except:
db.rollback()
print("导入数据库失败!")
cur.close()
扩展功能:读取评论并制作词云
第一步:读取评论:
获取评论链接:在评论界面

对比后发现topid不同,偶然发现topid和songid一致(运气好… .)
由之前得到的songid得到url
第二步:制作词云
使用wordcloud,jieba,matplotlib.pyplot模块搞定
下面是全部的代码:
import requests
import json
import jieba
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
import pymysql
import warnings
class QQmusic:
def __init__(self, want=0, commentwant=0):
self.songlist = []
self.songname = []
self.songsinger = []
self.songmid = []
self.songid = []
self.commentwant = commentwant
self.want = want
def getHTMLText(self,url): #获取信息页面
try:
r = requests.get(url,headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'},timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r
except:
print("无法获得网页信息!")
def searchMusic(self): #搜索歌曲或歌手信息
try:
name = input("请输入歌名或者歌手:")
#导入相关信息
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?p=1&n=10&w=%s'%(name)
html = self.getHTMLText(url).text
#解码
html = html[9:]
html = html[:-1]
js = json.loads(html)
#获取歌曲信息
songlist = js['data']['song']['list']
#访问song字典
for song in songlist:
songmid = song['songmid']
songname = song['songname']
songsinger = song['singer'][0]['name']
songid = song['songid']
self.songname.append(songname) #获取歌曲名信息
self.songsinger.append(songsinger) #获取歌手信息
self.songid.append(songid) #获取歌曲id用以获取评论地址
self.songmid.append(songmid) #获取歌曲mid用以获取歌曲下载地址
if song['pay']['paydownload']: #获取歌曲VIP信息,打印歌曲实现搜索功能
self.songlist.append([songname,songsinger,songmid,'[VIP]'])
print(songname,songsinger,songmid,'[VIP]')
else:
self.songlist.append([songname,songsinger,songmid])
print(songname,songsinger,songmid)
except:
print("搜索功能出错!")
def downloadMusic(self): #下载音乐
try:
want = int(input('您想下载第几首歌曲(1-10):'))
self.want = want
#排除VIP歌曲
while want<=0:
print("数据错误!,请重新输入一个大于0的数")
while ['VIP'] in self.songlist[want-1]:
want = int(input('抱歉,VIP歌曲无法下载,请重新输入想下载的歌曲:'))
print('获取歌曲资源中,请稍等...')
#获取purl链接
key_url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?&data={"req":{"param":{"guid":"220844550"}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"220844550","songmid":["%s"],"uin":"2212"}},"comm":{"uin":2212}}'%(self.songmid[want-1])
html = self.getHTMLText(key_url).text
#解码
key_json = json.loads(html)
final_url =key_json['req_0']['data']['midurlinfo'][0]['purl']
#拼接url获得下载地址
url = 'http://dl.stream.qqmusic.qq.com/' + final_url
print("成功获取资源!")
print("正在下载歌曲中......")
#设置下载名称
name = self.songlist[want-1][0] + '-' + self.songlist[want-1][1] + '-' + self.songlist[want-1][2]
music = self.getHTMLText(url).content
with open(name + '.mp4','wb') as f:
f.write(music)
print("成功下载歌曲!")
f.close()
except:
print("下载音乐出错!")
def getMusicReviews(self):
try:
want = int(input("请输入想要获得评论的歌曲(1-10):"))
self.commentwant = want
#获取前10页评论
for pagenum in range(0,10):
#获取评论连接
url = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk_new_20200303=5381&g_tk=5381&loginUin=939542692&hostUin=0&format=json&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=%s&cmd=8&needmusiccrit=0&pagenum=%d&pagesize=25&lasthotcommentid=&domain=qq.com&ct=24&cv=10101010'%(self.songid[want-1],pagenum)
r = self.getHTMLText(url)
html = str(r.content,'UTF-8')
#解码
js = json.loads(html)
commentlist = js['comment']['commentlist']
content = []
#保存评论并删去特定字符
for i in commentlist:
try:
content.append(i['rootcommentcontent'].replace("[em]", "").replace("[/em]", "").replace("e400", "").replace("\r",""))
except KeyError:
content = []
break
name = self.songlist[want - 1][0] + '-' + self.songlist[want - 1][1]
print("正在将评论保存到文本中......")
with open(name + '-' + 'comment' + '.txt', 'a', encoding='UTF-8') as f:
for i in range(len(content)):
string = content[i].split("\\n")
for i in string:
i = i.replace("该评论已经被删除", "")
f.writelines(i)
f.write("\n")
print("保存成功!")
except:
print("评论查询功能出错!")
def createWordCloud(self):
print("根据评论开始生成词云...")
name = self.songlist[self.commentwant - 1][0] + '-' + self.songlist[self.commentwant - 1][1]
with open(name + '-' + 'comment' + '.txt', 'r', encoding='UTF-8') as f:
str = f.read()
f.close()
word = " ".join(jieba.cut(str)) #将评论句子以空格将一些关键字词分开
wordcloud = WordCloud(
background_color='white', #设置词云背景为白色
max_words=300, #最大字数300
stopwords=STOPWORDS,
font_path='C:\Windows\Fonts\simsun.ttc', #使用字体为微软雅黑
width=1200, #设置宽度
height=800, #设置高度
max_font_size=120, #设置字体型号
random_state=45, #随机颜色数量
collocations=False,
margin=2).generate(word)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
def connectDataBase(self):
print("开始连接数据库...")
#连接数据库
db = pymysql.connect(host='localhost', user='root', password='root', port=3306, db='qqmusic', charset='utf8')
cur = db.cursor()
print("成功连接数据库")
sqlc = ''' #创建音乐下载表
create table if not exists download(
id int(20) not null auto_increment primary key comment '编号',
songname varchar(20) not null comment '歌曲名',
songsinger varchar(20) not null comment '歌手',
songmid varchar(30) not null comment '歌曲mid'
)'''
cur.execute(sqlc)
warnings.filterwarnings('ignore') #用于忽视重复建表警告
songname = self.songname[self.want-1]
songsinger = self.songsinger[self.want-1]
songmid = self.songmid[self.want-1]
#插入数据,可检测重复下载
sqli = '''replace into download(songname,songsinger,songmid)
values('%s','%s','%s')''' % (songname, songsinger, songmid)
try:
cur.execute(sqli)
db.commit()
print("导入数据库成功!")
except:
db.rollback()
print("导入数据库失败!")
cur.close()
QQ = QQmusic()
QQ.searchMusic()
QQ.downloadMusic()
QQ.connectDataBase()
print("是否需要读取评论并制作词云?")
ans = input("回复yes 或 no:")
if ans == 'yes':
QQ.getMusicReviews()
QQ.createWordCloud()
while 1:
print("请问是否继续下载?")
answer = input("回复yes 或 no:")
if answer == 'yes':
QQ = QQmusic()
QQ.searchMusic()
QQ.downloadMusic()
QQ.connectDataBase()
print("是否需要读取评论并制作词云?")
ans = input("回复yes 或 no:")
if ans == 'yes':
QQ.getMusicReviews()
QQ.createWordCloud()
else:
break
目前正在做推荐系统。。。书里的代码有点怪,估计要自己想办法- –