Python敏感词过滤DFA算法+免费附带敏感词库
DFA简介参考:https://blog.csdn.net/chenssy/article/details/26961957
此篇是上述JAVA敏感词过滤的python版本,完整版本,修改版本
首先我们看看最终处理效果
实例1:
输入字符串
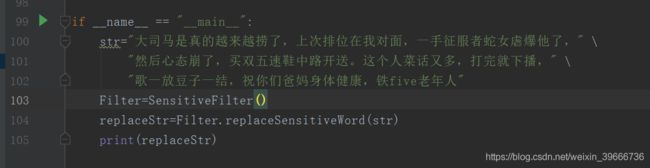
处理结果

核心代码:
SensitiveFilter类
框架如下
class SensitiveFilter:
#初始化
def __init__(self):
self.initSensitiveWordMap(self.sensitiveWordList)
...
#构建敏感词库
def initSensitiveWordMap(self,sensitiveWordList):
...
#检测文本中存在的敏感词
def checkSensitiveWord(self,txt,beginIndex=0):
...
#得到输入字符串中敏感词列表
def getSensitiveWord(self,txt):
...
#替换文本中的敏感词
def replaceSensitiveWord(self,txt,replaceChar='*'):
...
下面看具体的每个函数
Part 1
init函数 初始化
def __init__(self):
# file把敏感词库加载到列表中
file = open(Dir_sensitive, 'r', encoding = 'ANSI')
file_lst = file.readlines()
self.sensitiveWordList = [i.split('\n')[0] for i in file_lst]
# print(sensitiveWordList[:10])
# file1把停用词加载到列表中
file1 = open(Dir_stopWord, 'r', encoding = 'ANSI')
file1_lst = file1.readlines()
self.stopWordList = [i.split('\n')[0] for i in file1_lst]
##得到sensitive字典
self.sensitiveWordMap = self.initSensitiveWordMap(self.sensitiveWordList)
Part 2
initSensitiveWordMap函数 构建敏感词库
#构建敏感词库
def initSensitiveWordMap(self,sensitiveWordList):
sensitiveWordMap = {}
# 读取每一行,每一个word都是一个敏感词
for word in sensitiveWordList:
nowMap=sensitiveWordMap
#遍历该敏感词的每一个特定字符
for i in range(len(word)):
keychar=word[i]
wordMap=nowMap.get(keychar)
if wordMap !=None:
#nowMap更新为下一层
nowMap=wordMap
else:
#不存在则构建一个map,isEnd设置为0,因为不是最后一个
newNextMap={}
newNextMap["isEnd"]=0
nowMap[keychar]=newNextMap
nowMap=newNextMap
#到这个词末尾字符
if i==len(word)-1:
nowMap["isEnd"]=1
#print(sensitiveWordMap)
return sensitiveWordMap
Part 3
checkSensitiveWord函数 检测输入文本,并返回敏感词长度
def checkSensitiveWord(self,txt,beginIndex=0):
'''
:param txt: 输入待检测的文本
:param beginIndex:输入文本开始的下标
:return:返回敏感词字符的长度
'''
nowMap=self.sensitiveWordMap
sensitiveWordLen=0 #敏感词的长度
containChar_sensitiveWordLen=0 #包括特殊字符敏感词的长度
endFlag=False #结束标记位
for i in range(beginIndex,len(txt)):
char=txt[i]
if char in self.stopWordList:
containChar_sensitiveWordLen+=1
continue
nowMap=nowMap.get(char)
if nowMap != None:
sensitiveWordLen+=1
containChar_sensitiveWordLen+=1
#结束位置为True
if nowMap.get("isEnd")==1:
endFlag=True
else:
break
if endFlag==False:
containChar_sensitiveWordLen=0
#print(sensitiveWordLen)
return containChar_sensitiveWordLen
Part 4
getSensitiveWord函数 得到输入文本中存在的敏感词列表
def getSensitiveWord(self,txt):
cur_txt_sensitiveList=[]
#注意,并不是一个个char查找的,找到敏感词会i增强敏感词的长度
for i in range(len(txt)):
length=self.checkSensitiveWord(txt,i)
if length>0:
word=txt[i:i+length]
cur_txt_sensitiveList.append(word)
i=i+length-1
#出了循环还要+1 i+length是没有检测到的,
#下次直接从i+length开始
return cur_txt_sensitiveList
Part 5
replaceSensitiveWord函数 敏感词替换部分
def replaceSensitiveWord(self,txt,replaceChar='*'):
Lst=self.getSensitiveWord(txt)
#print(Lst)
for word in Lst:
replaceStr=len(word)*replaceChar
txt=txt.replace(word,replaceStr)
return txt
敏感词和停用词可以自定义
格式如下
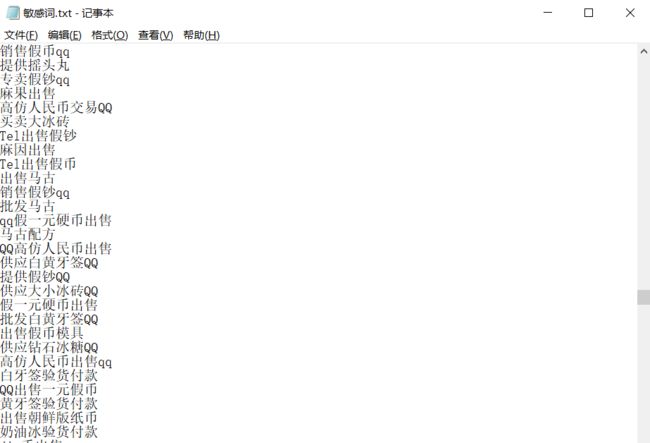

完整代码
#!/usr/bin/env python
#-*- coding:utf-8 -*-
# author:zbt
# datetime:2020-03-16 11:53
# software: PyCharm
Dir_sensitive='C:\\Users\\zbt\\Desktop\\X实习\\敏感词【ing】\\敏感词.txt'
Dir_stopWord='C:\\Users\\zbt\\Desktop\\X实习\\敏感词【ing】\\停用词.txt'
class SensitiveFilter:
def __init__(self):
# file把敏感词库加载到列表中
file = open(Dir_sensitive, 'r', encoding = 'ANSI')
file_lst = file.readlines()
self.sensitiveWordList = [i.split('\n')[0] for i in file_lst]
# print(sensitiveWordList[:10])
# >>['1234', '12345', '123456', '甲基麻黄碱', '来曲唑', '依西美坦', '阿那曲唑', '螺内酯', '沙美特罗', '丙磺舒']
# file1把停用词加载到列表中
file1 = open(Dir_stopWord, 'r', encoding = 'ANSI')
file1_lst = file1.readlines()
self.stopWordList = [i.split('\n')[0] for i in file1_lst]
##得到sensitive字典
self.sensitiveWordMap = self.initSensitiveWordMap(self.sensitiveWordList)
#构建敏感词库
def initSensitiveWordMap(self,sensitiveWordList):
sensitiveWordMap = {}
# 读取每一行,每一个word都是一个敏感词
for word in sensitiveWordList:
nowMap=sensitiveWordMap
#遍历该敏感词的每一个特定字符
for i in range(len(word)):
keychar=word[i]
wordMap=nowMap.get(keychar)
if wordMap !=None:
#nowMap更新为下一层
nowMap=wordMap
else:
#不存在则构建一个map,isEnd设置为0,因为不是最后一个
newNextMap={}
newNextMap["isEnd"]=0
nowMap[keychar]=newNextMap
nowMap=newNextMap
#到这个词末尾字符
if i==len(word)-1:
nowMap["isEnd"]=1
#print(sensitiveWordMap)
return sensitiveWordMap
def checkSensitiveWord(self,txt,beginIndex=0):
'''
:param txt: 输入待检测的文本
:param beginIndex:输入文本开始的下标
:return:返回敏感词字符的长度
'''
nowMap=self.sensitiveWordMap
sensitiveWordLen=0 #敏感词的长度
containChar_sensitiveWordLen=0 #包括特殊字符敏感词的长度
endFlag=False #结束标记位
for i in range(beginIndex,len(txt)):
char=txt[i]
if char in self.stopWordList:
containChar_sensitiveWordLen+=1
continue
nowMap=nowMap.get(char)
if nowMap != None:
sensitiveWordLen+=1
containChar_sensitiveWordLen+=1
#结束位置为True
if nowMap.get("isEnd")==1:
endFlag=True
else:
break
if endFlag==False:
containChar_sensitiveWordLen=0
#print(sensitiveWordLen)
return containChar_sensitiveWordLen
def getSensitiveWord(self,txt):
cur_txt_sensitiveList=[]
#注意,并不是一个个char查找的,找到敏感词会i增强敏感词的长度
for i in range(len(txt)):
length=self.checkSensitiveWord(txt,i)
if length>0:
word=txt[i:i+length]
cur_txt_sensitiveList.append(word)
i=i+length-1 #出了循环还要+1 i+length是没有检测到的,下次直接从i+length开始
return cur_txt_sensitiveList
def replaceSensitiveWord(self,txt,replaceChar='*'):
Lst=self.getSensitiveWord(txt)
#print(Lst)
for word in Lst:
replaceStr=len(word)*replaceChar
txt=txt.replace(word,replaceStr)
return txt
if __name__ == "__main__":
str="blablablabla"
Filter=SensitiveFilter()
replaceStr=Filter.replaceSensitiveWord(str)
print(replaceStr)
最后免费附带敏感词和停用词
https://pan.baidu.com/s/1AftA45Zdz2_AtVJEuI5jHA
密码
b0rs