MHA实现图书借阅系统的后端mysql集群存储且利用Zabbix+OA实现云警告
在学校的数据库课程实验中老师让做一个程序,要求必须连接mysql,然后我就写了一个python程序,实现了一个简单的图书借阅系统,具体请看python连接数据库实现简单的图书借阅系统。在实验后,我就想到既然已经使用数据库存储数据了,那么作为一个想要成为运维工程师的我来说何不利用所学知识,将整个后端数据库做的复杂一点,模拟企业中的mysql的集群,利用mha实现mysql的GTID的主从复制,高可用,最后再添加一个读写分离。最后再用Zabbix+OA实现云报警平台,实时监控我们的mysql存储状态。话不多说,下面就是我们的实际部署。
我们首先将整个mysql集群搭建出来,然后再应用我们的python程序。
实验环境:
| 节点 | ip | 节点属性 |
|---|---|---|
| server1 | 172.25.66.1 | master |
| server2 | 172.25.66.2 | slave |
| server3 | 172.25.66.3 | slave |
| server4 | 172.25.66.4 | mha |
| server5 | 172.25.66.5 | Zabbix+OA |
各节点关闭selnux,firewalld
实验部署:
一、部署server1-3的GTID主从复制
1.三个节点均安装mysql

2.三个节点均启动mysql,然后做安全初始化,修改密码

注意以上标示的地方,当我们第一次启动mysql时系统嗯会给一个临时密码,我们需要通过查看日志得知密码,否则再重设密码时没有旧密码改不了,还有就是新密码的强度一定要高,一般得由字母+数字+特殊字符组成,长度大于8位,否则就会出现我们以上的这种情况。
2.更改master的配置文件信息(server1)
vim /etc/my.cnf

3.更改slave配置文件信息(server2和server3)
vim /etc/my.conf

server3的server-id设置为3
4.master做授权


5.在slave做gtid授权,并开启slave(server2和server3相同)

查看状态:
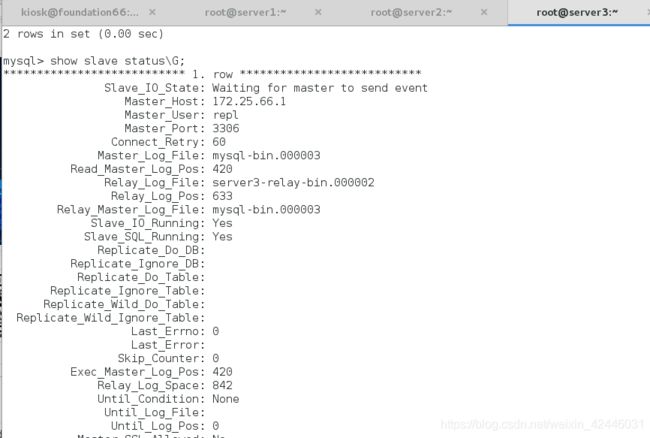

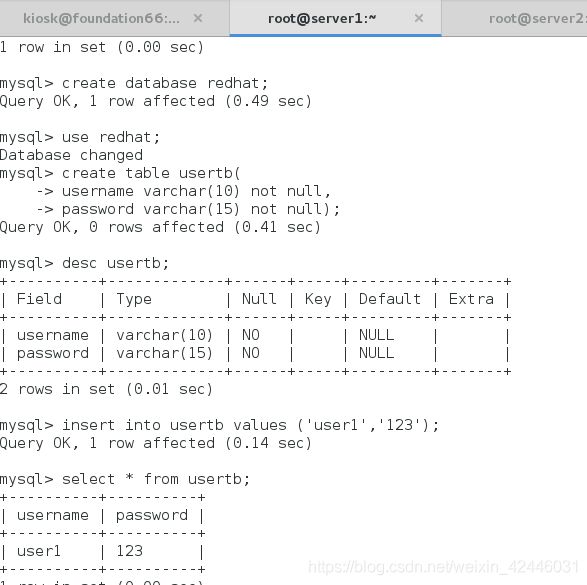
然后进行测试:

二、更改主从复制为半同步复制
1)正常的复制为:事务一(t1)写入binlog buffer;dumper线程通知slave有新的事务t1;binlog buffer进行checkpoint;slave的io线程接收到t1并写入到自己的的relay log;slave的sql线程写入到本地数据库。 这时,master和slave都能看到这条新的事务,即使master挂了,slave可以提升为新的master。
2)异常的复制为:事务一(t1)写入binlog buffer;dumper线程通知slave有新的事务t1;binlog buffer进行checkpoint;slave因为网络不稳定,一直没有收到t1;master挂掉,slave提升为新的master,t1丢失。
3)很大的问题是:主机和从机事务更新的不同步,就算是没有网络或者其他系统的异常,当业务并发上来时,slave因为要顺序执行master批量事务,导致很大的延迟。
为了弥补以上几种场景的不足,MySQL从5.5开始推出了半同步复制。相比异步复制,半同步复制提高了数据完整性,因为很明确知道,在一个事务提交成功之后,这个事务就至少会存在于两个地方。即在master的dumper线程通知slave后,增加了一个ack(消息确认),即是否成功收到t1的标志码,也就是dumper线程除了发送t1到slave,还承担了接收slave的ack工作。如果出现异常,没有收到ack,那么将自动降级为普通的复制,直到异常修复后又会自动变为半同步复制。
半同步复制的配置:(我们在这里设置为等待10秒,如果没有收到ack就转为异步)
1.在master安装插件,激活插件
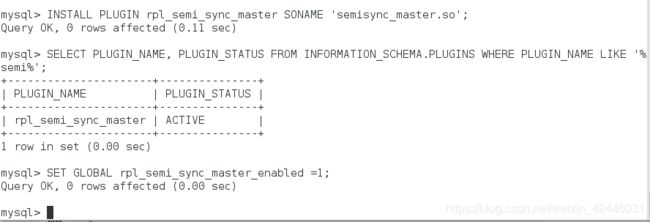
2.两个从库添加插件并激活

3.重起从库的IO线程

4.主库查看相关信息

可以看到主库的半同步是打开的

5.查看从库信息

6.测试半同步复制
1.关闭从库的IO线程,在主库添加信息,模拟网络卡顿
slave:

在这里我们关闭了从库的io线程,这样主库就收不到从库发送的ack了。
master:
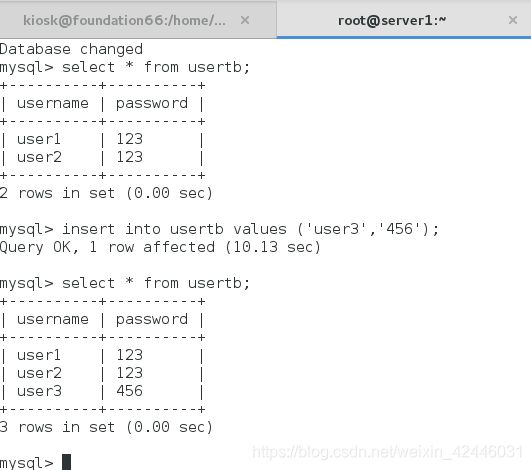
slave查看:信息同步不到

在主库查看半同步状态
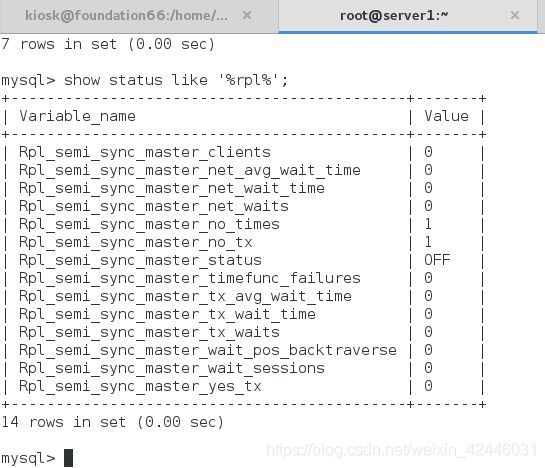
可以看到半同步已经关闭,已经变成异步
slave打开IO线程,重新查看数据同步
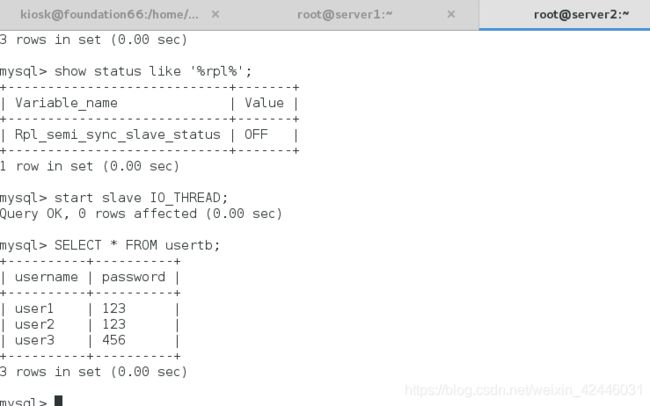
我们看到当我们重新打开io线程后数据就恢复了,然后又恢复到半同步状态。
三、利用MHA做mysql的高可用
首先在一开始我们因为做的是高可用,当master宕机后就要从slave选出一台主机顶替master主机,所以我们的slave节点也要打开log-bin
所以我们要修改server2和server3的/etc/my.cnf文件



然后在三台主机上重起mysqld
然后配置mysqld的关于GTID的半同步复制
server1:
mysql> grant replication slave on *.* to repl@'172.25.66.%' identified by 'Ljz+123up';
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
mysql> set global rpl_semi_sync_master_enabled=1;
mysql> show variables like '%rpl%';
+-------------------------------------------+------------+
| Variable_name | Value |
+-------------------------------------------+------------+
| rpl_semi_sync_master_enabled | ON |
| rpl_semi_sync_master_timeout | 10000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_for_slave_count | 1 |
| rpl_semi_sync_master_wait_no_slave | ON |
| rpl_semi_sync_master_wait_point | AFTER_SYNC |
| rpl_semi_sync_slave_enabled | OFF |
| rpl_semi_sync_slave_trace_level | 32 |
| rpl_stop_slave_timeout | 31536000 |
+-------------------------------------------+------------+
server2(备份master):
mysql> stop slave;
mysql> change master to master_host='172.25.66.1',master_user='repl',master_password='Ljz+123up',MASTER_AUTO_POSITION=1;
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
mysql> set global rpl_semi_sync_slave_enabled=1;
mysql> start slave;
server3:同server2完全相同。
1.在server4安装MHA及相关依赖包

2.server4给server1-3的免密登陆
[root@server4 ~]# ssh-keygen ##先生成密钥
[root@server4 ~]# ssh-copy-id server1:
[root@server4 ~]# ssh-copy-id server2: #发送密钥
[root@server4 ~]# ssh-copy-id server3:
server1,2,3之间互相也要免密
3.server1-3安装mha的节点安装包
[root@server1 ~]# yum install -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm 这里的包和server4里的节点包是一样的
4.在server4上配置nha工作目录以及配置文件
[root@server4 MHA-7]# mkdir /etc/masterha
[root@server4 MHA-7]# cd /etc/masterha/
[root@server4 masterha]# ls
[root@server4 masterha]# vim /etc/masterha/ljz.cnf
[server default]
manager_workdir=/etc/masterha ##设置manager的工作目录
manager_log=/var/log/masterha.log #manager日志文件
master_binlog_dir=/var/lib/mysql ##设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录
#master_ip_failover_script= /usr/local/bin/master_ip_failover
#master_ip_online_change_script= /usr/local/bin/master_ip_online_change
password=Ljz+123up #mysql管理帐号和密码
user=root
ping_interval=1 ##设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行railover
remote_workdir=/tmp ##设置远端mysql在发生切换时binlog的保存位置
repl_password=Ljz+123up #复制的帐号和密码
repl_user=repl #复制的用户
#report_script=/usr/local/send_report
#secondary_check_script= /usr/local/bin/masterha_secondary_check -s server03 -s server02
#shutdown_script=""
ssh_user=root #系统ssh用户
[server1]
hostname=172.25.66.1
port=3306
[server2]
hostname=172.25.66.2
port=3306
candidate_master=1 ##设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
check_repl_delay=0 ##默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
[server3]
hostname=173.25.66.3
port=3306
no_master=1 #表示这个节点不能用作master
5.检测ssh连接

6.检测复制功能

我们发现有报错,可以清晰的看出我们在去连接server1时被拒绝了,这是因为我们在做复制的授权的时候是授权给repl用户的,而我们的server4的连接默认使用的是root用户
解决办法:server1上授权用户

同时我们还需要注意一个问题,MHA帐号系统必须要一致,所以不能给开发两个帐号,所以在控制开发的权限的时候只有一种办法就是:给从库设置只读。然而当主库宕机后,从库进行切换时,MHA在进行切换时可以设置只读或者解除只读

再次测试:
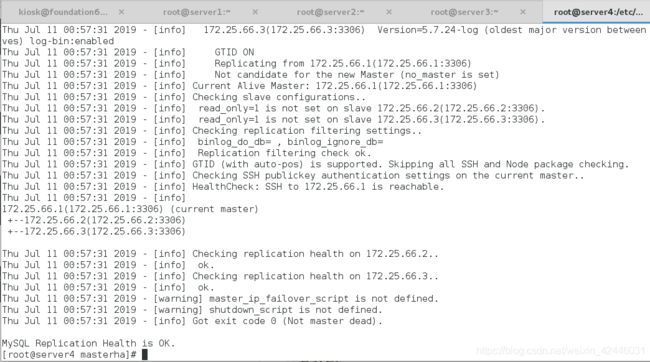
这里显示ok
7.测试:手动同步
(1)手动关闭server1(master)的msql
[root@server1 ~]# systemctl stop mysqld
(2)在mha节点上手动将master同步到server2上
[root@server4 masterha]# masterha_master_switch --master_state=dead --conf=/etc/masterha/ljz.cnf --dead_master_host=172.25.66.1 --dead_master_port=3306 --new_master_host=172.25.66.2 --new_master_port=3306

(3)在server2和server3上查看slave状态
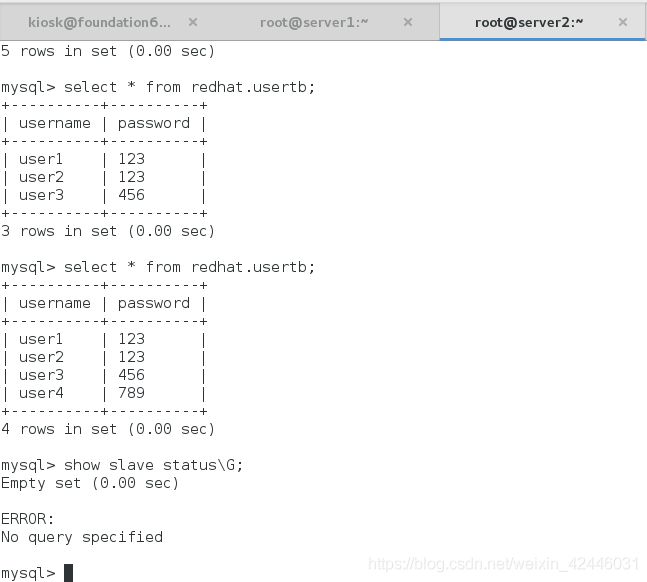

我们可以发现server3上的master主机已经变成了server2,说明手动转换成功
(4)然后打开server1的mysqld,在sever1上重新添加master,查看slave的状态,显示master是server2,切换成功
[root@server1 ~]# systemctl start mysqld

(5)手动切换master(直接切换)
首先mha节点要删除之前手动切换产生的failover.complete文件,否则再次转换则不会成功
[root@server4 masterha]# ls
ljz.cnf ljz.failover.complete
[root@server4 masterha]# rm -fr ljz.failover.complete
手动切换新的master——>server1
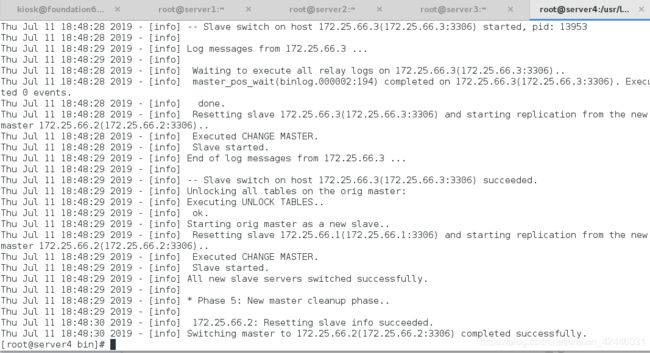
[root@server4 masterha]# masterha_master_switch --conf=/etc/masterha/ljz.cnf --master_state=alive --new_master_host=172.25.66.1 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
这次server2不用添加master。
server1:
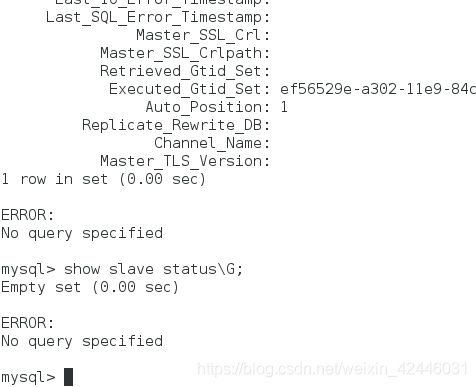
server2:
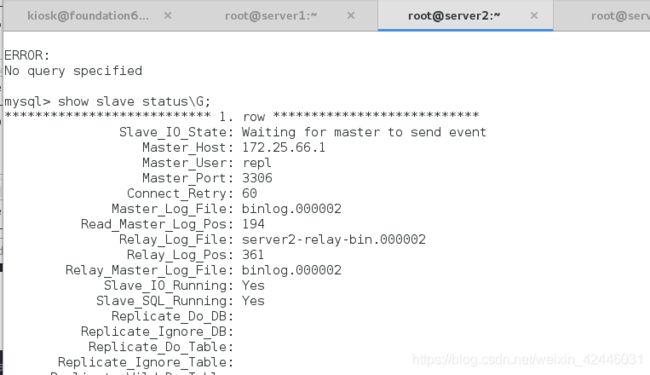
server3:
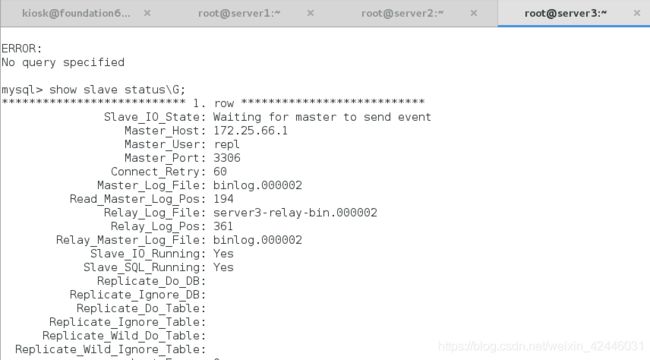
当然mha的切换还可以利用nohup自动切换,由于我们这里只是测试我们的mha,所以自动切换就不做过多叙述了
四、实现动态vip
我们在这里有一各问题,我们的master切换后主机的ip就变了,那么这样明显对于我们的数据库访问是不对的,所以我们需要设置VIP,就如同之前学习过的Keepalived的高可用一样,所以我们就可以安装mha的管理工具来设置VIP,然后通过访问可以漂移的VIP去访问数据库,这样我们的访问的主机就好像一直是同一台主机一样
1.编辑配置文件
[root@server4 masterha]# ls
ljz.cnf
[root@server4 masterha]# vim ljz.cnf
添加
master_ip_failover_script= /usr/local/bin/master_ip_failover
master_ip_online_change_script= /usr/local/bin/master_ip_online_change
2.找到mha的管理工具包,然后解压缩
[root@server4 masterha]# cd
[root@server4 ~]# ls
mha4mysql-manager-0.58.tar.gz MHA-7
[root@server4 ~]# tar zxf mha4mysql-manager-0.58.tar.gz
3.在 /usr/local/bin添加两个文件,并给两个文件添加执行权限

[root@server4 bin]# vim master_ip_online_change
#!/usr/bin/env perl
use strict;
use warnings FATAL =>'all';
use Getopt::Long;
my $vip = '172.25.66.100/24'; # Virtual IP
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
my $exit_code = 0;
my (
$command, $orig_master_is_new_slave, $orig_master_host,
$orig_master_ip, $orig_master_port, $orig_master_user,
$orig_master_password, $orig_master_ssh_user, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password, $new_master_ssh_user,
);
GetOptions(
'command=s' => \$command,
'orig_master_is_new_slave' => \$orig_master_is_new_slave,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'orig_master_user=s' => \$orig_master_user,
'orig_master_password=s' => \$orig_master_password,
'orig_master_ssh_user=s' => \$orig_master_ssh_user,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
'new_master_ssh_user=s' => \$new_master_ssh_user,
);
exit &main();
sub main {
#print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
print "\n\n\n***************************************************************\n";
print "Disabling the VIP - $vip on old master: $orig_master_host\n";
print "***************************************************************\n\n\n\n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
print "\n\n\n***************************************************************\n";
print "Enabling the VIP - $vip on new master: $new_master_host \n";
print "***************************************************************\n\n\n\n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
`ssh $orig_master_ssh_user\@$orig_master_host \" $ssh_start_vip \"`;
exit 0;
}
else {
&usage();
exit 1;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $new_master_ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $orig_master_ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
[root@server4 bin]# vim master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
my $vip = '172.25.66.100/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
给两个配置文件添加执行权限

4.由于我们目前server1是master,所以我们先给server1添加vip

5.测试vip
1.在server4上开启热切换
[root@server4 bin]# masterha_master_switch --conf=/etc/masterha/ljz.cnf --master_state=alive --new_master_host=172.25.66.2 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
我们可以发现master已经切换到了server2上,并且vip也漂到了server2上。
6.测试自动转换:
1.发起自动转换命令
[root@server4 bin]# nohup masterha_manager --conf=/etc/masterha/ljz.cnf &> /dev/null &
[1] 14126
2.然后关闭我们现在的master(server2)的mysqld
[root@server2 ~]# systemctl stop mysqld.service
3.查看我们的vip
 我们可以发现其成功的漂移到了server1上,我们的高可用配置完成。
我们可以发现其成功的漂移到了server1上,我们的高可用配置完成。
7.恢复server2的mysqld,继续充当slave节点

配置读写分离
我们知道在企业中当业务访问量过高的时候,我们的后端服务器的压力是很大的,同样我们的后端存储的压力也是非常大的,数据库的写操作相对读操作是比较耗时的,而且我们的大多数访问量中有很多的操作其实都是读操作,那么我们就可以设置读写分离,让我们的master主要处理写操作,让slave处理读操作,这样就可以减轻我们的master的压力,在这里我们使用mysql-proxy来实现读写分离
使用mysql-proxy实现mysql的读写分离,mysql-proxy实际上是作为后端mysql主从服务器的代理,它直接接受客户端的请求,对SQL语句进行分析,判断出是读操作还是写操作,然后分发至对应的mysql服务器上。
实验环境:
在这里我们将我们的server4作为我们的mysql-proxy,server1和server2看成是master,ip为172.25.66.100,server3作为slave。
实验步骤:
1.主从复制的设置
由于之前我们已经做好了,所以这里不做叙述。
2.在master上设置授权,我们在这里授予所有权线(当然在现实的生产环境中肯定不能这样。)
mysql> grant all privileges on *.* to 'root'@'%' identified by 'Ljz+123up';
server1和srver2都这样做
3.安装mysql-proxy

4.mysql-proxy的配置
1.建立目录存放读写分离的配置文件和目录

2.将mysql-proxy的二进制命令放进系统的环境变量中
[root@server4 mysql-proxy]# vim ~/.bash_profile
PATH=$PATH:$HOME/bin:/usr/local/mysql-proxy/bin
[root@server4 mysql-proxy]# source ~/.bash_profile
3.修改数据库发生读写分离时的最大值和最小值
[root@server4 mysql-proxy]# cd /usr/local/mysql-proxy/share/doc/mysql-proxy/
[root@server4 mysql-proxy]# vim rw-splitting.lua
40 min_idle_connections = 1, 这里我们设置最小连接数为1
41 max_idle_connections = 2, 最大连接数为2,最大连接数大于二时发生读写分离
实现读写分离是lua脚本实现的,现在mysql-proxy里面已经集成,无需再安装
4.创建配置文件
[root@server4 mysql-proxy]# cd /usr/local/mysql-proxy/conf/
[root@server4 conf]# vim mysql-proxy.conf
[mysql-proxy]
user=root ##运行mysql-proxy的用户
proxy-address=0.0.0.0:3306 ##运行mysql-proxy运行的ip和端口
proxy-read-only-backend-addresses=172.25.66.3:3306 ##slave用户:只读
proxy-backend-addresses=172.25.66.100:3306 ##master用户:可读写
proxy-lua-script=/usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua ##lua脚本地址
log-file=/usr/local/mysql-proxy/logs/mysql-proxy.log ##日志位置
log-level=debug ##定义log日志级别,由高到低分别有(error|warning|info|message|debug)
daemon=true ##打入后台
keepalive=true ##mysql-proxy崩溃时,尝试重起(持续连接)
5.给文件设置权限,再启动mysql-proxy(否则会启动失败)

5.用tcpdump抓取读写分离
[root@server4 conf]# yum install -y tcpdump
[root@server4 conf]# tcpdump -i eth0 port 3306
6.然后我们用物理机打开三个shell,连接ip为server4的ip的数据库,然欧分别进行读写操作查看抓包情况

像这样打开三个shell去登陆mysql,模拟访问连接数大于2的情况

写操作:


可以看到我们写入数据后真正进行写操作的是172.25.66.100,也就是我们的master
读操作:
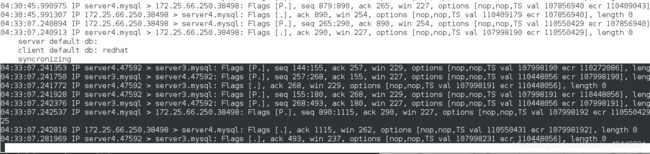
可以看到我们的数据包请求是通过server3的,也就是说我们的读操作是在server3上进行的。
至此,我们的读写分离也做完了,可以说我们的整个后端存储集群已经做好了,但是一名运维人员,不能只部署好我们的环境,我们还需要对我们的服务进行监控,如果有服务挂掉了,或许我们的备用机顶上去了,但是我们依然需要去修复挂掉的服务,那么此时,我们就需要一个监控,当发生故障时它可以向我们报警,让运维人员能够即使的处理问题。
那么在这里我就来做一个zabbix监控,来监控我们的mha高可用,当发生宕机,vip转移时向我们发送警告,以便能够分析问题,处理宕机的服务器。
zabbix监控的添加
在这里我们选择再建一台虚拟机server5(172.25.66.5)作为zabbix监控主机,由于我们的mha,proxy都在server4上,那么我们就可以把zabbix-agent部署在server4上,我们通过监控mha的状态来分析我们的后端存储的状态与报警。
1.zabbix的安装以及配置
本机安装agent
安装数据库,创建zabbix用户并授权
[root@server5 4.0]# yum install -y mariadb-server
[root@server5 4.0]# systemctl start mariadb.service
[root@server5 4.0]# mysql_secure_installation
MariaDB [(none)]> create database zabbix character set utf8 collate utf8_bin;
Query OK, 1 row affected (0.00 sec)
MariaDB [(none)]> grant all privileges on zabbix.* to zabbix@localhost identified by 'redhat';
Query OK, 0 rows affected (0.00 sec)
导入zabix数据
[root@server5 4.0]# zcat /usr/share/doc/zabbix-server-mysql-4.0.5/create.sql.gz | mysql -uzabbix -predhat zabbix

更改配置文件
[root@server5 4.0]# vim /etc/zabbix/zabbix_server.conf

开启zabbix

更改zabbix的配置文件,启动http
[root@server5 4.0]# vim /etc/httpd/conf.d/zabbix.conf
20 php_value date.timezone Asia/Shanghai
[root@server5 4.0]# systemctl start httpd
2.浏览器访问zabbix的前端
登陆的时候我们选择使用admin用户,密码默认是zabbix
3.添加agent节点,在这里我们添加server4

[root@server4 ~]# vim /etc/zabbix/zabbix_agentd.conf
98 Server=172.25.66.5
139 ServerActive=172.25.66.5
150 Hostname=server4
[root@server4 ~]# systemctl start zabbix-agent.service
4.前端添加主机

5.创建监控项
在这里我们的mha其实就只是一个进程,那么如果发生了主从切换,实现了高可用,那么我们的mha进程也就结束了,也就是说我们其实对于高可用的监控只需要监控mha进程即可。

这里我们监控我们的mha进程的数量,当然这里的进程可以是含关键字的,只要有唯一标示即可,但是我在这里输入的是整个进程的名称
6.创建触发器

这里的表达式我们选择后面的添加,选择监控项,然后最后的值为0,即进程消失时报警。
7.创建mha进程的自启动
如果发生了单点故障,及时实现了主从切换,这时我们的mha进程就结束了,这样明显是不合理的,那么我们就需要设置一个开机自启动,这样就可以预防发生单点故障后我们的服务器继续出问题。
首先我们得给我们需要在server4上给我们的zabbix添加相应的权限,并且开启远程命令的支持
[root@server4 ~]# vim /etc/zabbix/zabbix_agentd.conf
73 EnableRemoteCommands=1
[root@server4 ~]# vim /etc/sudoers

[root@server4 ~]# systemctl restart zabbix-agent
然后我们创建动作

测试:
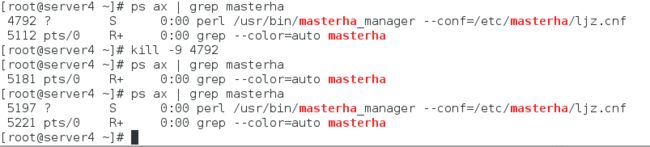
我们可以看到我们的关闭了mha后它还是又起来了,并且进程号完全不一样,这就说明我们的mha进程是一个新的,是通过zabbix发送的远程命令执行的。

那么问题又来了,我又觉得我们光对其监控还是远远不够的,我们完全可以再加一个报警,否则即使我们mha进程重新起来了,我们可能无法在短时间内知道我们的服务已经出现了问题,那么此时我结合了OA来实现一个云警告报警,让其直接将服务出问题的消息发到我们的微信上
OA实现云警告(微信)
地址:http://wiki.onealert.com/
如图这样,我们添加一个处理人员。这里面在个人中心添加手机号,微信号等的绑定,用于接受我们的报警信息。
我们在这里要使用zabbix的监控就需要安装Zabbix的探侦
具体看OA的官网:http://wiki.onealert.com/integration/zabbix-new.html
我们在这里将探探针安装在server5上
1.安装部署:
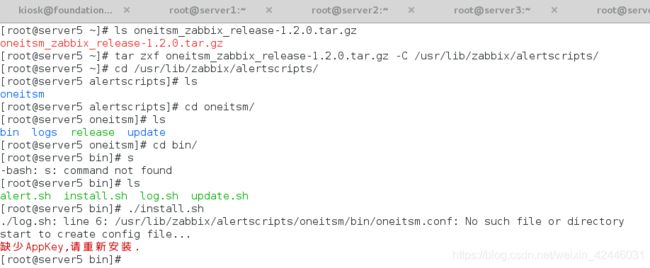
显示缺少appkey
appk必须在网页的CA中添加应用后才有
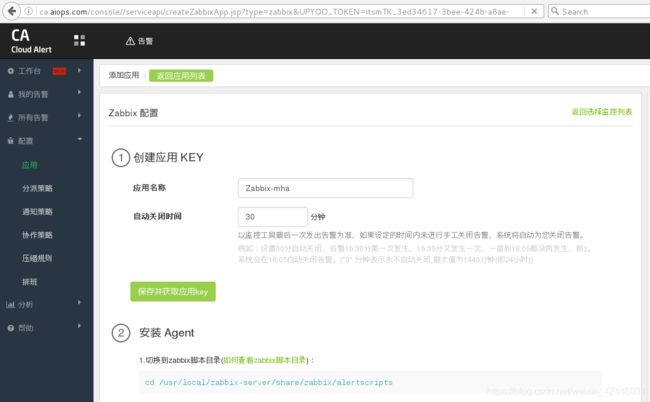
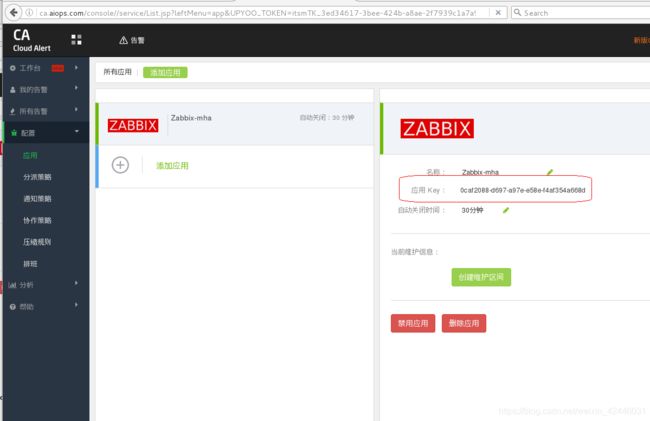
此时我们就有应用key了
重新在zabbix-server端配置
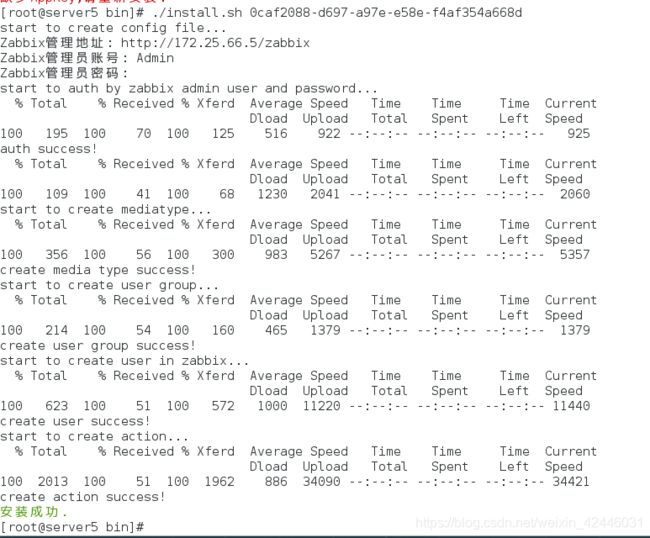
显示安装成功。
2.在web界面添加报警媒介
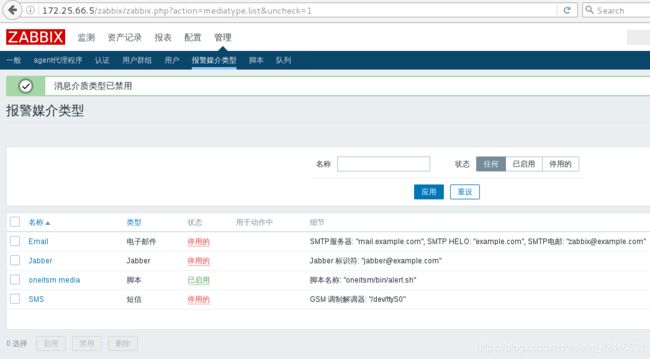
除了OA我们禁用其他的报警媒介
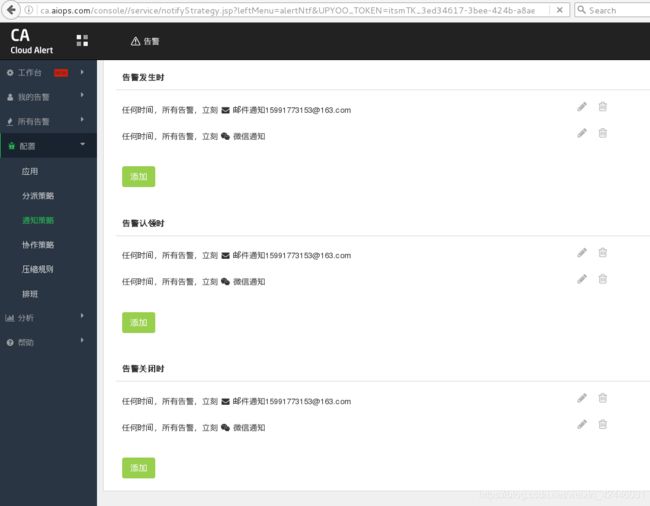
3.在OA配置通知策略
4.测试:
我们关掉mha的进程

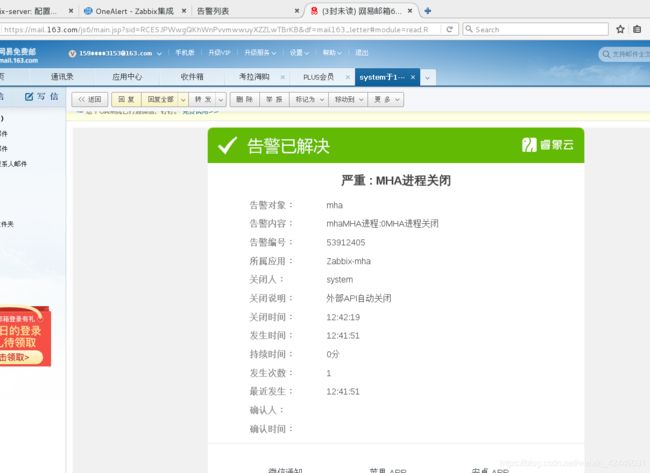
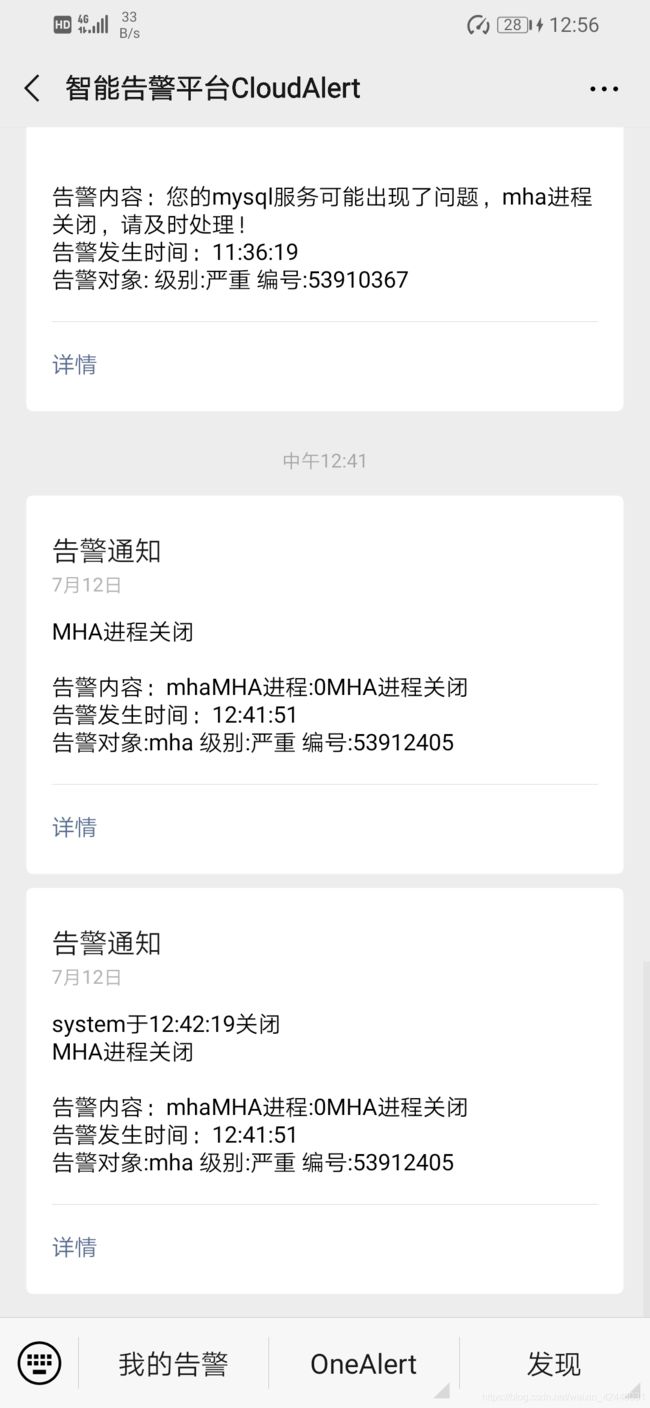
就像这样,我们的微信也可以收到报警信息。
至此,我们的整个一套mysql的后端存储全部做完了,我们接下来只需要把我们的python程序的mysql连接接口设置为server4即可。