Hadoop集群搭建及运行自带的wordcount程序
slave1,slave2的配置与master1的所有配置均一致(除了静态ip不同),以下所有配置,三台主机都需配置。
1.搭建环境
在虚拟机中搭建hadoop集群。
| 软件 |
版本 |
| 操作系统 |
centOS Linux7、Windows 10 |
| JDK |
jdk1.8.0_162 |
| Hadoop |
hadoop-2.7.1 |
| Xshell |
Xshell6(连接集群) |
| 浏览器 |
Chorme |
| VMware |
12.5.6 build-5528349 |
集群(由于我电脑上已有master,在这里主机为master1)
| 主机名 |
主机ip |
| master1 |
192.168.205.120 |
| slave1 |
192.168.205.121 |
| slave2 |
192.168.205.122 |
2.在VMware中安装centos
2.1安装中硬件配置只保留这几个就ok

2.2修改系统-安装位置及网络和主机名
路径:系统-安装位置-其它存储选项-分区-(选中)我要配置分区-完成
点击完成会弹出手动分区选项,修改新挂载点将使用的分区方案为:标准分区。
点击+号,新增挂载点如下图:
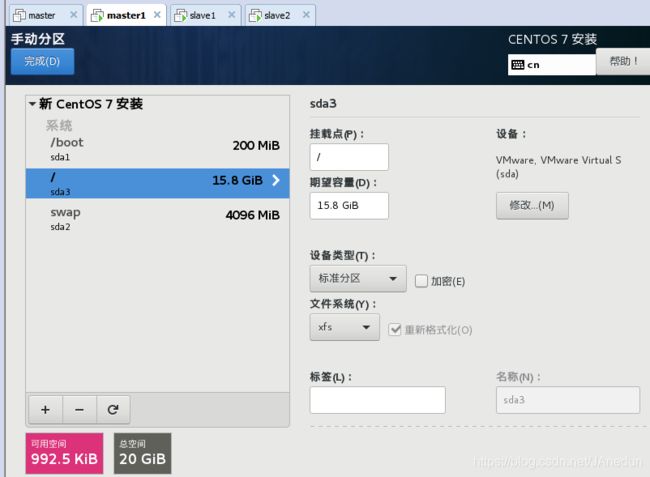
修改:网络和主机名

点击完成后要设置ROOT密码。
2.3配置静态ip
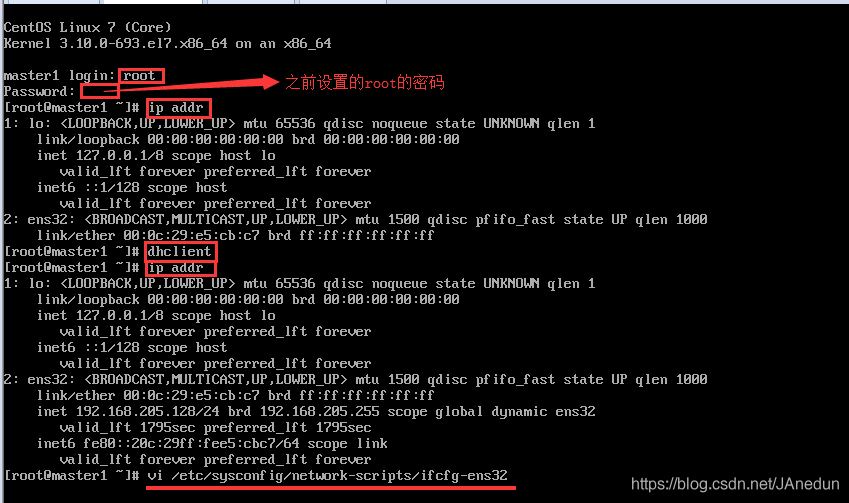

如何 查看自己虚拟机的子网:状态栏中的编辑-虚拟网络编辑器

配置好以后用命令::wq保存退出
执行命令重启服务:systemctl restart network.service
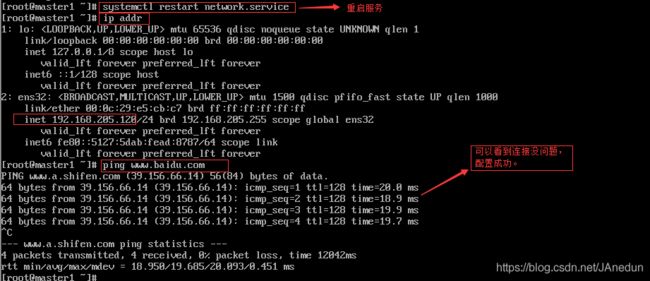
用xshell6软件连接集群后,配置jdk和hadoop
3.配置jdk和hadoop前期工作
3.1下载好jdk和hadoop安装包
jdk下载地址:http://www.oracle.com/technetwork/java/javase/archive-139210.html
hadoop下载地址:http://hadoop.apache.org/releases.html
3.2下载文件上传(rz)下载(sz)工具
[root@master1 ~]# yum -y install lrzsz
3.3关闭防火墙
查看防火墙状态
[root@master1 ~]systemctl status firewalld
#关闭防火墙
[root@master1 ~]# systemctl stop firewalld
#禁止开机启动防火墙
[root@master1 ~]# systemctl disable firewalld
3.4配置免密登录
三台主机同样操作
3.4.1修改hosts文件
在后面加上主机ip及主机名
可以删掉:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@master1 ~]# vi /etc/hosts
192.168.205.120 master1
192.168.205.121 slave1
192.168.205.122 slave23.4.2配置ssh免密登录
[root@master1 ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:emcGL2aUsSkVIVJRWDNd/DtGGajjei3tAxYnnfAn/+g root@master1
The key's randomart image is:
+---[RSA 2048]----+
| ..+=Bo o.. |
| ... +o o . |
| o = o o |
| . == * = |
| . S. = = . |
| + o+ = |
| . =o=+ . + |
| +.=o + . .|
| . o.oE |
+----[SHA256]-----+
[root@master1 ~]# ssh-copy-id master1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'master1 (192.168.205.120)' can't be established.
ECDSA key fingerprint is SHA256:o5DYw4b3NNPrwquWQeP1gXrgiEkEUcb1LtgBrLivopw.
ECDSA key fingerprint is MD5:b7:af:37:e3:25:b4:e3:d2:0d:91:9b:70:b6:d6:45:1c.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@master1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'master1'"
and check to make sure that only the key(s) you wanted were added.
[root@master1 ~]# ssh-copy-id slave1
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'slave1 (192.168.205.121)' can't be established.
ECDSA key fingerprint is SHA256:U4UJmBi5mMQ4nkuKOGSUMsB/orqpleoocAfvJVrYKow.
ECDSA key fingerprint is MD5:dc:38:a3:32:1d:55:11:31:b3:04:2a:79:4e:e1:ea:fa.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'slave1'"
and check to make sure that only the key(s) you wanted were added.
[root@master1 ~]# ssh-copy-id slave2
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'slave2 (192.168.205.122)' can't be established.
ECDSA key fingerprint is SHA256:QkxrLeadFv9zRaGn98qZ8BULGsTg/0bmI1SjtPmeSTg.
ECDSA key fingerprint is MD5:4b:cc:27:67:96:42:27:73:29:89:28:c8:fa:19:95:6b.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'slave2'"
and check to make sure that only the key(s) you wanted were added.
[root@master1 ~]# ssh slave1
Last login: Thu Jul 18 11:51:41 2019 from 192.168.205.1
[root@slave1 ~]# ssh slave2
Last login: Thu Jul 18 11:52:38 2019 from 192.168.205.1
[root@slave2 ~]# ssh master1
Last login: Thu Jul 18 11:50:21 2019 from 192.168.205.1
[root@master1 ~]# 4.配置jdk
三台主机同样操作
#创建指定目录
[root@master1 ~]# mkdir -p /SoftWare/Java
#进入Java目录里
[root@master1 ~]# cd /SoftWare/Java
#上传jdk包
[root@master1 Java]# rz
#解压到当前目录
[root@master1 Java]# tar -zxvf jdk-8u162-linux-x64.tar.gz
#配置环境变量
[root@master1 Java]# vi /etc/profile
#将以下内容添加至文件最后
export JAVA_HOME=/SoftWare/Java/jdk1.8.0_162
export JRE_HOME=/SoftWare/Java/jdk1.8.0_162/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib/rt.jar
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
#重启配置
[root@master1 Java]# source /etc/profile
#查看配置是否生效
[root@master1 Java]# java -version
java version "1.8.0_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)5.配置hadoop
5.1 修改环境变量
#创建指定目录
[root@master1 ~]# mkdir -p /SoftWare/Hadoop
#进入Hadoop目录里
[root@master1 ~]# cd /SoftWare/Hadoop
#上传hadoop包
[root@master1 Hadoop]# rz
#解压到当前目录
[root@master1 Hadoop]# tar zxvf hadoop-2.7.1.tar.gz
#进入hadoop目录里
[root@master1 Hadoop]# cd hadoop-2.7.1
#配置环境变量
[root@master1 hadoop-2.7.1]# vi /etc/profile
#将以下内容添加至文件最后
export HADOOP_HOME=/SoftWare/Hadoop/hadoop-2.7.1
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#重启配置
[root@master1 hadoop-2.7.1]# source /etc/profile
#查看配置是否生效
[root@master1 hadoop-2.7.1]# hadoop version
Hadoop 2.7.1
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 15ecc87ccf4a0228f35af08fc56de536e6ce657a
Compiled by jenkins on 2015-06-29T06:04Z
Compiled with protoc 2.5.0
From source with checksum fc0a1a23fc1868e4d5ee7fa2b28a58a
This command was run using /SoftWare/Hadoop/hadoop-2.7.1/share/hadoop/common/hadoop-common-2.7.1.jar5.2修改hdfs-site.xml文件
在
[root@master1 hadoop-2.7.1]# vi etc/hadoop/hdfs-site.xml
dfs.namenode.name.dir
file:/SoftWare/Hadoop/hadoop-2.7.1/hdfs/name
dfs.datanode.data.dir
file:/SoftWare/Hadoop/hadoop-2.7.1/hdfs/data
dfs.replication
2
dfs.namenode.secondary.http-address
master1:50090
dfs.namenode.secondary.https-address
192.168.10.250:50091
dfs.webhdfs.enabled
true
5.3修改core-site.xml文件
在
[root@master1 hadoop-2.7.1]# vi etc/hadoop/core-site.xml
fs.default.name
hdfs://master1:9000
5.4修改mapred-site.xml文件
在
[root@master1 hadoop-2.7.1]# cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[root@master1 hadoop-2.7.1]# vi etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
5.5修改yarn-site.xml文件
在
[root@master1 hadoop-2.7.1]# vi etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
master1
yarn.nodemanager.aux-services
mapreduce_shuffle
5.6修改slaves文件
将里面的localhost改为以下内容:
[root@master1 hadoop-2.7.1]# vi etc/hadoop/slaves
slave1
slave25.7修改hadoop-env.sh文件
[root@master1 hadoop-2.7.1]# vi etc/hadoop/hadoop-env.sh
将:
export JAVA_HOME=${JAVA_HOME}
改为:
export JAVA_HOME=/SoftWare/Java/jdk1.8.0_1625.8格式化节点
[root@master1 hadoop-2.7.1]# bin/hdfs namenode -format
#倒数几行会出现successfully,证明格式化成功
19/07/18 13:23:45 INFO common.Storage: Storage directory /SoftWare/Hadoop/hadoop-2.7.1/hdfs/name has been successfully formatted.
5.9启动hdfs
[root@master1 hadoop-2.7.1]# sbin/start-dfs.sh
Starting namenodes on [master1]
master1: starting namenode, logging to /SoftWare/Hadoop/hadoop-2.7.1/logs/hadoop-root-namenode-master1.out
slave2: starting datanode, logging to /SoftWare/Hadoop/hadoop-2.7.1/logs/hadoop-root-datanode-slave2.out
slave1: starting datanode, logging to /SoftWare/Hadoop/hadoop-2.7.1/logs/hadoop-root-datanode-slave1.out
Starting secondary namenodes [master1]
master1: starting secondarynamenode, logging to /SoftWare/Hadoop/hadoop-2.7.1/logs/hadoop-root-secondarynamenode-master1.out5.10启动yarn
[root@master1 hadoop-2.7.1]# sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /SoftWare/Hadoop/hadoop-2.7.1/logs/yarn-root-resourcemanager-master1.out
slave2: starting nodemanager, logging to /SoftWare/Hadoop/hadoop-2.7.1/logs/yarn-root-nodemanager-slave2.out
slave1: starting nodemanager, logging to /SoftWare/Hadoop/hadoop-2.7.1/logs/yarn-root-nodemanager-slave1.out
#启动完成后,在各个节点输入jps查看是否启动成功。出现以下信息则证明成功
[root@master1 hadoop-2.7.1]# jps
9430 NameNode
9577 SecondaryNameNode
9754 ResourceManager
9838 Jps
[root@slave1 hadoop-2.7.1]# jps
9162 NodeManager
9006 DataNode
9215 Jps
[root@slave2 hadoop-2.7.1]# jps
9217 Jps
9139 NodeManager
8983 DataNode5.11 使用WEB界面访问
在浏览器地址栏中输入http://192.168.205.120:50070


6.运行wordcount
统计本地的一个txt文本,文本信息如下:

[root@master1 hadoop-2.7.1]# bin/hadoop fs -mkdir -p /data/wordcount
[root@master1 hadoop-2.7.1]# bin/hadoop fs -mkdir -p /output/
[root@master1 hadoop-2.7.1]# bin/hadoop fs -ls /
Found 2 items
drwxr-xr-x - root supergroup 0 2019-07-18 14:20 /data
drwxr-xr-x - root supergroup 0 2019-07-18 14:20 /output
[root@master1 hadoop-2.7.1]# rz
[root@master1 hadoop-2.7.1]# bin/hadoop fs -put /SoftWare/Hadoop/hadoop-2.7.1/country.txt /data/wordcount/
[root@master1 hadoop-2.7.1]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /data/wordcount /output/count
19/07/18 14:25:10 INFO client.RMProxy: Connecting to ResourceManager at master1/192.168.205.120:8032
19/07/18 14:25:21 INFO input.FileInputFormat: Total input paths to process : 1
19/07/18 14:25:22 INFO mapreduce.JobSubmitter: number of splits:1
19/07/18 14:25:24 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1563430716355_0001
19/07/18 14:25:30 INFO impl.YarnClientImpl: Submitted application application_1563430716355_0001
19/07/18 14:25:30 INFO mapreduce.Job: The url to track the job: http://master1:8088/proxy/application_1563430716355_0001/
19/07/18 14:25:30 INFO mapreduce.Job: Running job: job_1563430716355_0001
19/07/18 14:26:48 INFO mapreduce.Job: Job job_1563430716355_0001 running in uber mode : false
19/07/18 14:26:48 INFO mapreduce.Job: map 0% reduce 0%
19/07/18 14:27:51 INFO mapreduce.Job: map 100% reduce 0%
19/07/18 14:28:30 INFO mapreduce.Job: map 100% reduce 67%
19/07/18 14:28:33 INFO mapreduce.Job: map 100% reduce 100%
19/07/18 14:28:37 INFO mapreduce.Job: Job job_1563430716355_0001 completed successfully
19/07/18 14:28:38 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=174
FILE: Number of bytes written=231127
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=346
HDFS: Number of bytes written=120
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=54725
Total time spent by all reduces in occupied slots (ms)=39536
Total time spent by all map tasks (ms)=54725
Total time spent by all reduce tasks (ms)=39536
Total vcore-seconds taken by all map tasks=54725
Total vcore-seconds taken by all reduce tasks=39536
Total megabyte-seconds taken by all map tasks=56038400
Total megabyte-seconds taken by all reduce tasks=40484864
Map-Reduce Framework
Map input records=20
Map output records=27
Map output bytes=318
Map output materialized bytes=174
Input split bytes=111
Combine input records=27
Combine output records=12
Reduce input groups=12
Reduce shuffle bytes=174
Reduce input records=12
Reduce output records=12
Spilled Records=24
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=1428
CPU time spent (ms)=13450
Physical memory (bytes) snapshot=295804928
Virtual memory (bytes) snapshot=4154818560
Total committed heap usage (bytes)=139227136
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=235
File Output Format Counters
Bytes Written=120
[root@master1 hadoop-2.7.1]# bin/hadoop fs -text /output/count/part-r-00000
中国大陆 2
冰岛 1
加拿大 1
印度 1
德国 1
意大利 2
日本 2
法国 2
瑞士 1
美国 9
英国 3
香港 2如果想将统计后的信息下载到本地,可以采取以下方法下载,下载后可用记事本打开:


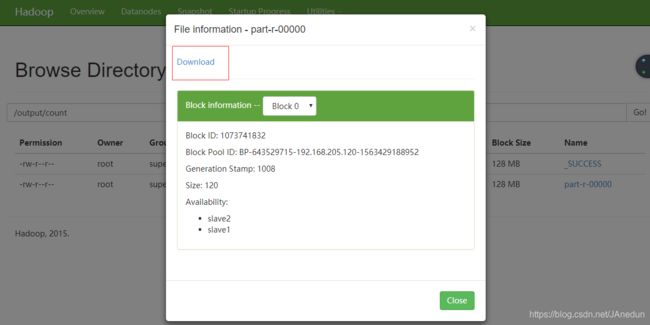
若出现不能访问的情况,在本地hosts文件中添加一下自己配置的集群主机的ip地址。
先将C:\Windows\System32\drivers\etc中hosts复制出来再做修改,然后再复制到原位置。
在hosts最后加上即可:
192.168.205.120 master1
192.168.205.121 slave1
192.168.205.122 slave2