05-树9 Huffman Codes
题目
In 1953, David A. Huffman published his paper "A Method for the Construction of Minimum-Redundancy Codes", and hence printed his name in the history of computer science. As a professor who gives the final exam problem on Huffman codes, I am encountering a big problem: the Huffman codes are NOT unique. For example, given a string "aaaxuaxz", we can observe that the frequencies of the characters 'a', 'x', 'u' and 'z' are 4, 2, 1 and 1, respectively. We may either encode the symbols as {'a'=0, 'x'=10, 'u'=110, 'z'=111}, or in another way as {'a'=1, 'x'=01, 'u'=001, 'z'=000}, both compress the string into 14 bits. Another set of code can be given as {'a'=0, 'x'=11, 'u'=100, 'z'=101}, but {'a'=0, 'x'=01, 'u'=011, 'z'=001} is NOT correct since "aaaxuaxz" and "aazuaxax" can both be decoded from the code 00001011001001. The students are submitting all kinds of codes, and I need a computer program to help me determine which ones are correct and which ones are not.
Input Specification:
Each input file contains one test case. For each case, the first line gives an integer N (2≤N≤63), then followed by a line that contains all the N distinct characters and their frequencies in the following format:
c[1] f[1] c[2] f[2] ... c[N] f[N]
where c[i] is a character chosen from {'0' - '9', 'a' - 'z', 'A' - 'Z', '_'}, and f[i] is the frequency of c[i] and is an integer no more than 1000. The next line gives a positive integer M (≤1000), then followed by M student submissions. Each student submission consists of Nlines, each in the format:
c[i] code[i]
where c[i] is the i-th character and code[i] is an non-empty string of no more than 63 '0's and '1's.
Output Specification:
For each test case, print in each line either "Yes" if the student's submission is correct, or "No" if not.
Note: The optimal solution is not necessarily generated by Huffman algorithm. Any prefix code with code length being optimal is considered correct.
Sample Input:
7
A 1 B 1 C 1 D 3 E 3 F 6 G 6
4
A 00000
B 00001
C 0001
D 001
E 01
F 10
G 11
A 01010
B 01011
C 0100
D 011
E 10
F 11
G 00
A 000
B 001
C 010
D 011
E 100
F 101
G 110
A 00000
B 00001
C 0001
D 001
E 00
F 10
G 11
Sample Output:
Yes
Yes
No
No要求
时间限制: 400 ms
内存限制: 64 MB
代码长度限制: 16 KB题意理解
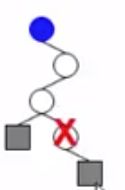
Huffman编码不唯一。
比如 1 1 2 2,可以有如下Huffman树:

都是最优Huffman编码。
需要注意的是通过Huffman算法得到的编码是最优编码,但是最优编码不一定通过Huffman算法得到。
而且题目中提到“Note: The optimal solution is not necessarily generated by Huffman algorithm.” 翻译为中文就是-----“注意:最优编码不一定通过Huffman算法得到!”
反例:

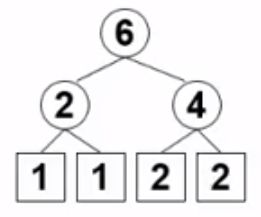
两个等长编码的效果是一样的,所以最优编码可以通过其他方式得到。
Huffman Codes的特点
- 最优编码 ---- 总长度(WPL)最小
- 无歧义解码 ---- 前缀码:数据仅存于叶子结点
- 没有度为1的结点 --- 满足1、2则必然有3
注意:满足2、3可不一定有1!
反例:

核心算法
计算最优编码长度



对每位学生的提交,检查
a) 长度是否正确![Len = \sum_{i = 0}^{N-1}strlen(code[i]) \times f[i]](http://img.e-com-net.com/image/info8/96eea7b4c719427d9bdd9e9dcaa9d0ac.gif)
注意:(如果编码是正确的,那么每个字符对应的编码的最大长度应该是多少)Code[i]的最大长度为 ?
 最极端情况Huffman树长这样,那么编码的最长编码长度为N-1,即Code[i]的最大长度为N - 1
最极端情况Huffman树长这样,那么编码的最长编码长度为N-1,即Code[i]的最大长度为N - 1
读的时候如果发现长度超过N-1,那后续就不用操作了,可以直接给出结论,但是当前字符串还是要读完,不然会影响读取下一个字符串。
b) 建树的过程中检查是否满足前缀码要求
最简单的方法就是根据读进来的Code[i]建树。
例:先建立一个根结点,然后逐行检查Code。
(1)读入Code[i] = "1011"
- 1、从第一个字符"1"开始。就要从当前结点向右拓展一层,当前结点检查一下无右子树,就直接建立一个右孩子。
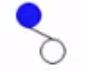
- 2、读入下一个字符"0"。从当前结点“1”向左拓展一层,检查当前结点无左子树,就直接建立一个左孩子。
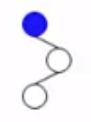
- 3、读入下一个字符"1"。当前结点无右孩子,直接建立一个右孩子。
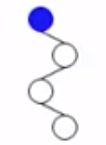
- 4、读入下一个字符"1"。当前结点无右孩子,直接建立一个右孩子。

- 5、此时读到了字符串的结尾,意味着现在这个结点上应该把字符的权重(即频率)放入,放入之前要慎重检查一下这个结点是否为叶子结点,就现在来看,这个结点是叶子结点,于是就将频率写到这个结点上。

(2)读入Code[i] = "100"
- 1、读入字符"1",从根结点出发,往右边拓展一层,发现根结点的右孩子已经存在了,检查发现当前这个孩子是无权重的结点(那就对了),那就继续往下走。
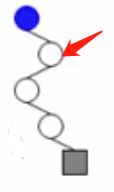
- 2、读入字符"0"当前结点(即1中访问过的)的左孩子是无权重的,继续往下走。
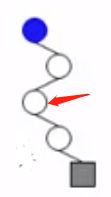
- 3、读入字符"0",当前结点(2中的结点)的左孩子为空,于是建一个左孩子。
- 4、读到了字符串的结尾,检查当前结点(3中的结点)的确是叶子结点,于是将权重写到这个结点中。

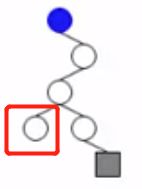
(3)读入Code[i] = "1001"
- 1、读入字符"1"。从根结点出发,可以发现1是OK的。
- 2、读入字符"0",也是OK的。
- 3、读入字符"0",发现一个带权重的结点,意味之前那个字符的编码是当前这个编码的前缀,事实也是这样,"100"是"1001"的前缀。读到这里,就知道错了。
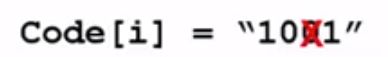
(4)读入Code[i] = "101"
- 依次读入"1"、"0"、"1",从根结点出发,发现1、0、1都没问题,发现已经到了字符串的结尾,而当前结点不是叶子结点,已经有左孩子了,这就意味着101一定是某个代码(本例中的1011)的前缀码。所以走到这个结点时,它不是叶子结点,就出错了。
核心思路
- 利用最小堆构建Huffman树;
- 利用Huffman树计算最优编码长度(WPL)
- 对学生的提交编码检查是否符合要求(1.编码长度是否与Huffman编码长度一致 2. 构建树,判断是否为前缀编码)
代码
#include
#include
#include
#define HeapCapacity 64
typedef struct TreeNode *HuffmanTree;
struct TreeNode
{
int Weight;
HuffmanTree Left;
HuffmanTree Right;
};
typedef struct HeapNode *MinHeap;
struct HeapNode
{
HuffmanTree *Data; //堆中存放TreeNode结点的数组
int Size;
};
MinHeap createHeap(); //创建最小堆
HuffmanTree createHuffman(); //创建Huffman树
MinHeap initHeap(int N, int F[]); //读取数据,并将数据插入到最小堆中
HuffmanTree deleteMin(MinHeap H); //堆的删除,获取最小堆中的最小值
void insertHeap(MinHeap H, HuffmanTree huff); //堆的插入
HuffmanTree huffman(MinHeap H);//Huffman树的构造
int WPL(HuffmanTree huff, int depth);//计算Huffman树的编码长度
int checkSubmit(char code[], HuffmanTree current); //检查学生的提交
int main()
{
int N;
scanf("%d", &N);
int F[N];
MinHeap H = initHeap(N, F);
HuffmanTree huff = huffman(H);
int codeLen = WPL(huff, 0);
int M;
scanf("%d", &M);
char ch;
char code[N+1];
int i;
for(i = 0; i < M; i++) {
int counter = 0;
int result = 1;
int flag = 0;
HuffmanTree head = createHuffman();
HuffmanTree current;
int k;
for(k = 0; k < N; k++) {
current = head;
getchar();
scanf("%c", &ch);
scanf("%s", code);
counter += strlen(code) * F[k]; //记录总的编码长度
if(flag == 0) {
result = checkSubmit(code, current);
if(result == 0)
flag = 1;
}
}
if(counter == codeLen && result == 1) {
printf("Yes\n");
} else {
printf("No\n");
}
}
return 0;
}
MinHeap createHeap()
{
MinHeap H = (MinHeap)malloc(sizeof(struct HeapNode));
H->Data = (HuffmanTree*)malloc(sizeof(struct TreeNode) * HeapCapacity); //最小堆存储数据是从下标为1开始的
H->Size = 0;
HuffmanTree huff = createHuffman();
H->Data[0] = huff;
return H;
}
HuffmanTree createHuffman()
{
HuffmanTree T = (HuffmanTree)malloc(sizeof(struct TreeNode));
T->Weight = 0;
T->Left = NULL;
T->Right = NULL;
return T;
}
MinHeap initHeap(int N, int F[])
{
MinHeap H = createHeap();
HuffmanTree huff;
char c;
int f;
int i;
for(i = 0; i < N; i++) {
getchar();
scanf("%c %d", &c, &f);
F[i] = f; //将频率保存到数组freq中
huff = createHuffman();
huff->Weight = f;
insertHeap(H, huff); //将频率插入到堆中
}
return H;
}
HuffmanTree deleteMin(MinHeap H)
{
HuffmanTree minItem = H->Data[1];
HuffmanTree temp = H->Data[H->Size--];
int parent, child;
for(parent = 1; parent * 2 <= H->Size; parent = child) {
child = parent * 2;
if((child != H->Size) && (H->Data[child]->Weight > H->Data[child + 1]->Weight))
child++;
if(temp->Weight <= H->Data[child]->Weight)
break;
H->Data[parent] = H->Data[child];
}
H->Data[parent] = temp;
return minItem;
}
void insertHeap(MinHeap H,HuffmanTree huff) //堆的插入操作
{
int i = ++H->Size;
for(; H->Data[i/2]->Weight > huff->Weight; i/=2) {
H->Data[i] = H->Data[i/2];
}
H->Data[i] = huff;
}
HuffmanTree huffman(MinHeap H) //形成Huffman树
{
HuffmanTree huff;
int i;
int times = H->Size; //一定要用临时变量记录,因为在deleteMin函数执行时,H->Size发生了变化
for(i = 1; i < times; i++) {
huff = createHuffman();
huff->Left = deleteMin(H);
huff->Right = deleteMin(H);
huff->Weight = huff->Left->Weight + huff->Right->Weight;
insertHeap(H, huff); //重新插入堆中
}
huff = deleteMin(H);
return huff;
}
int WPL(HuffmanTree huff, int depth)
{
if(huff->Left == NULL && huff->Right == NULL)
return depth * huff->Weight;
else
return WPL(huff->Left,depth + 1) + WPL(huff->Right, depth + 1);
}
int checkSubmit(char code[], HuffmanTree current) //建树的过程中检查是否满足前缀码要求
{
int i;
for(i = 0; i < strlen(code); i++) {
if(code[i] == '0') {//向左拓展一层
if(current->Left == NULL) {
current->Left = createHuffman();
} else if(current->Left->Weight == -1) { //已经访问到之前访问过的结点,即之前访问过的结点编码是当前字符串的前缀
return 0;
}
current = current->Left;
} else if (code[i] == '1') {
if(current->Right == NULL) {
current->Right = createHuffman();
} else if(current->Right->Weight == -1) {
return 0;
}
current = current->Right;
}
}
current->Weight = -1; //当前字符串遍历结束后,给当前结点赋值-1,那么后续一旦访问到结点的Weight = -1,就表明之前访问的某个字符串是当前字符串编码的前缀,就可以直接判断结果
if(current->Left == NULL && current->Right == NULL) //如果字符串遍历结束时,当前是叶子结点,那么当前字符串的编码是正确的
return 1;
else
return 0;
} 运行结果:
