数据分析学习笔记2020/7/22——numpy
numpy创建数组(矩阵)
import numpy as np
import random
#使用numpy生成数组,得到ndarray的类型
t1 = np.array([1,2,3,])
print(t1) #[1 2 3]
print(type(t1)) #

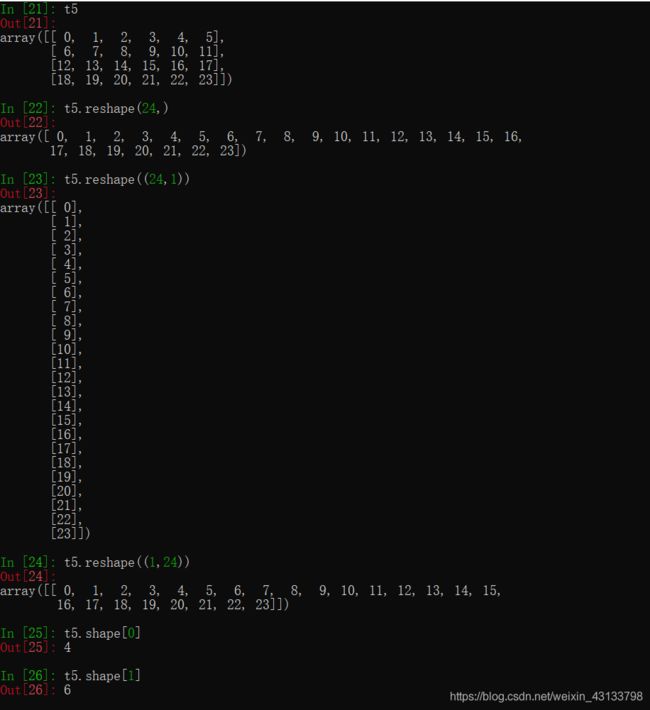

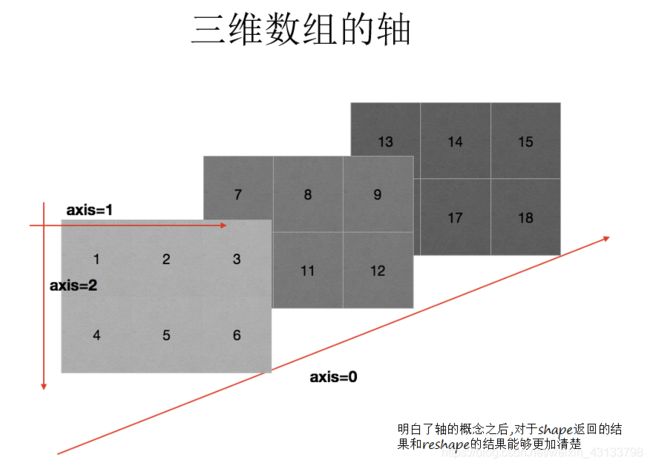
shape[0]就是读取矩阵第一维度的长度。








# coding=utf-8
import numpy as np
us_file_path = "./youtube_video_data/US_video_data_numbers.csv"
uk_file_path = "./youtube_video_data/GB_video_data_numbers.csv"
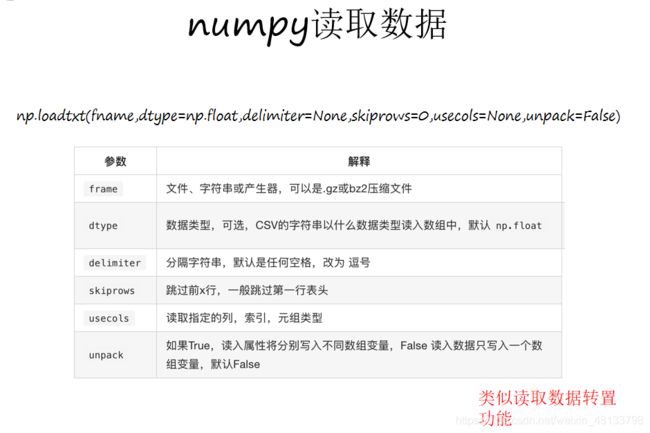
# t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
# print(t1)
print(t2)
print("*"*100)
#取行
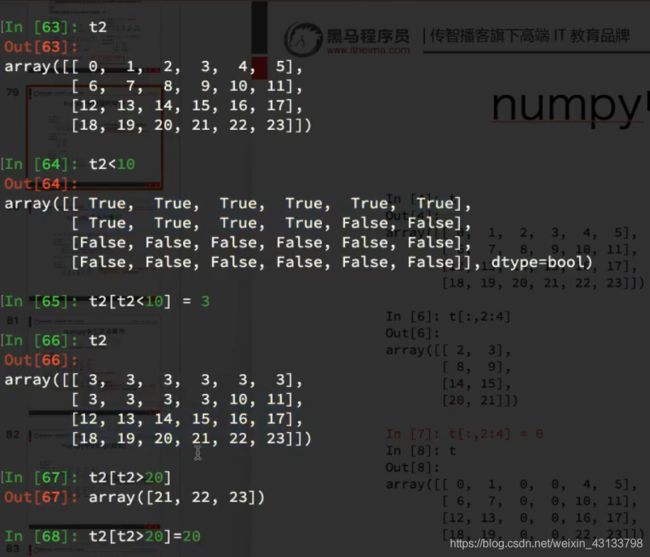
# print(t2[2])
#取连续的多行
# print(t2[2:])
#取不连续的多行;注意方括号的使用
# print(t2[[2,8,10]])
# print(t2[1,:])
# print(t2[2:,:])
# print(t2[[2,10,3],:])
#取列
# print(t2[:,0])
#取连续的多列
# print(t2[:,2:])
#取不连续的多列
# print(t2[:,[0,2]])
#取行和列,取第3行,第四列的值
# a = t2[2,3]
# print(a) #170708
# print(type(a)) #






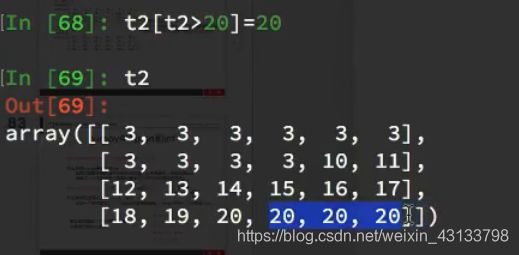
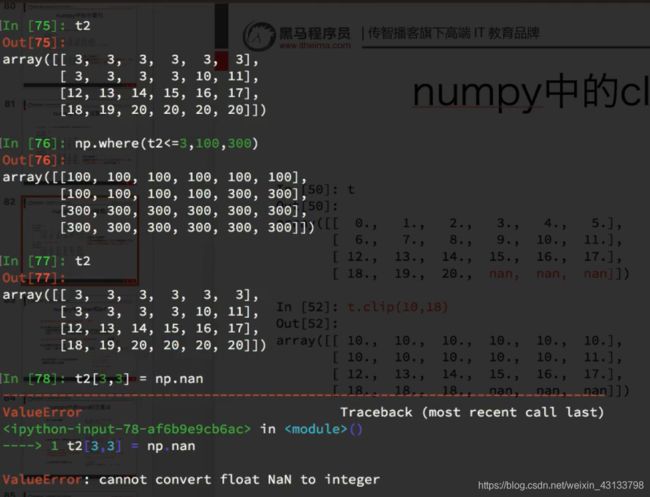


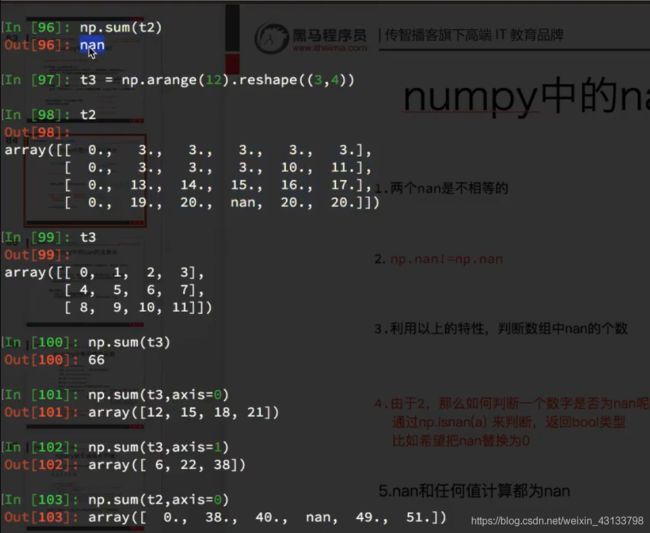
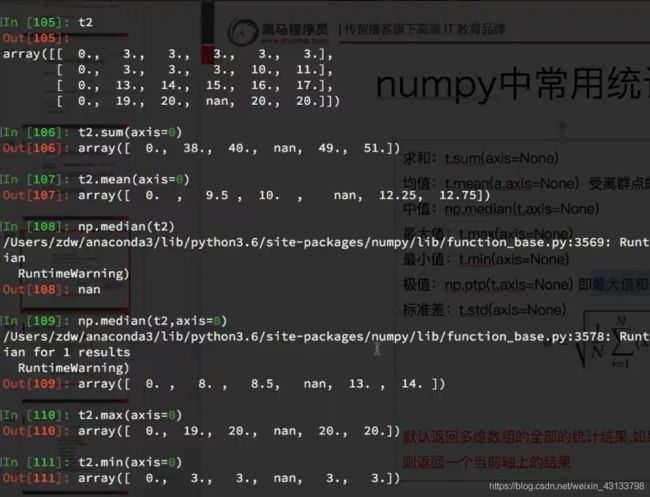


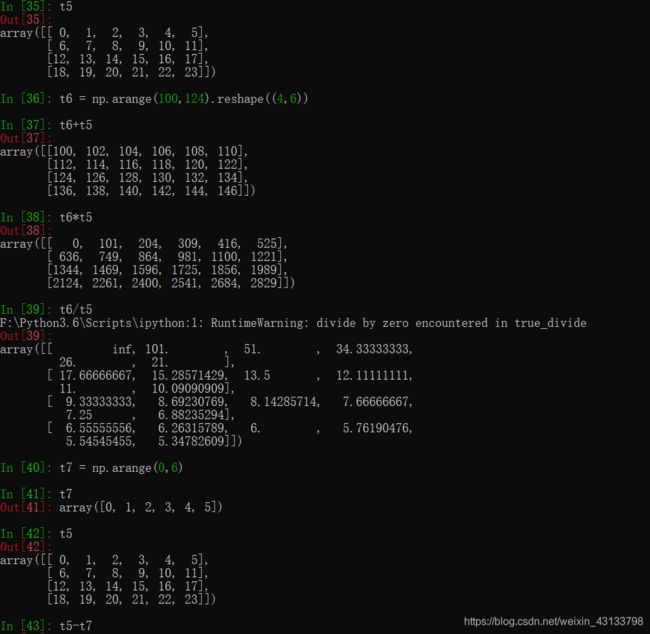
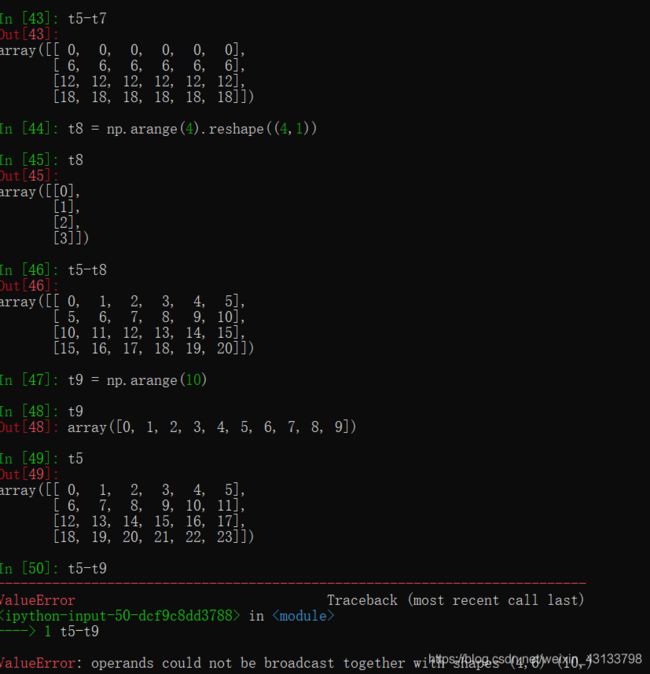
import numpy as np
def fill_ndarray(t1):
for i in range(t1.shape[1]): #遍历每一列
temp_col = t1[:,i] #当前的一列
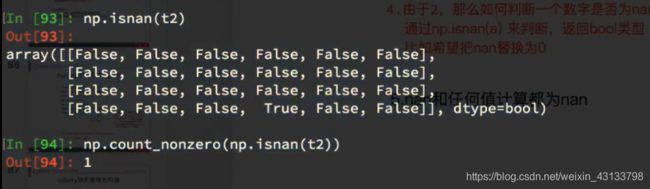
nan_num = np.count_nonzero(temp_col!=temp_col)
if nan_num != 0: #不为0,说明当前这一列中有nan
temp_not_nan_col = temp_col[temp_col==temp_col] #当前一列不为nan的array
#选中当前为nan的位置,把值赋值为不为nan的均值
temp_col[np.isnan(temp_col)] = temp_not_nan_col.mean()
return t1
if __name__ == '__main__':
t1 = np.arange(12).reshape((3, 4)).astype("float")
t1[1, 2:] = np.nan
print(t1)
t1 = fill_ndarray(t1)
print(t1)
题目一:
import numpy as np
from matplotlib import pyplot as plt
us_file_path = "./youtube_video_data/US_video_data_numbers.csv"
uk_file_path = "./youtube_video_data/GB_video_data_numbers.csv"
#t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
t_us = np.loadtxt(us_file_path,delimiter=",",dtype="int")
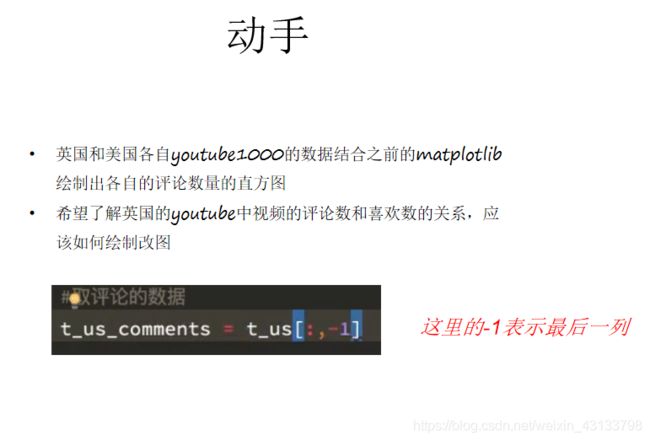
#取评论的数据
t_us_comments = t_us[:,-1]
#选择比5000小的数据
t_us_comments = t_us_comments[t_us_comments<=5000]
print(t_us_comments.max(),t_us_comments.min())
d = 250
bin_nums = (t_us_comments.max()-t_us_comments.min())//d
#绘图
plt.figure(figsize=(20,8),dpi=80)
plt.hist(t_us_comments,bin_nums)
plt.show()
题目二:
import numpy as np
from matplotlib import pyplot as plt
us_file_path = "./youtube_video_data/US_video_data_numbers.csv"
uk_file_path = "./youtube_video_data/GB_video_data_numbers.csv"
#t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
t_uk = np.loadtxt(uk_file_path,delimiter=",",dtype="int")
#选择喜欢书比50万小的数据
t_uk = t_uk[t_uk[:,1]<=500000]
t_uk_comment = t_uk[:,-1]
t_uk_like = t_uk[:,1]
#绘图
plt.figure(figsize=(20,8),dpi=80)
plt.scatter(t_uk_like,t_uk_comment)
plt.show()



import numpy as np
us_data = "./youtube_video_data/US_video_data_numbers.csv"
uk_data = "./youtube_video_data/GB_video_data_numbers.csv"
#加载国家数据
us_data = np.loadtxt(us_data,delimiter=",",dtype=int)
uk_data = np.loadtxt(uk_data,delimiter=",",dtype=int)
#添加国家信息
#构造全为零的数据
zeros_data = np.zeros((us_data.shape[0],1)).astype(int)
ones_data = np.ones((uk_data.shape[0],1)).astype(int)
#分别添加一列全为0,1的数组
us_data = np.hstack((us_data,zeros_data))
uk_data = np.hstack((uk_data,ones_data))
#拼接两组数据
final_data= np.vstack((us_data,uk_data))
print(final_data)