Selenium:requests+Selenum爬取京东所有图书类的数据
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息

得到的url:https://search.jd.com/Search?keyword=%E4%B9%A6&enc=utf-8&pvid=1daad564d3544d62995e3417d3711464
开始分析网页
- 博主是通过所有的品牌获取得到所有的书本信息

- 首先就要通过上面的连接进行将所有的品牌获取出来
- 分析:按F12

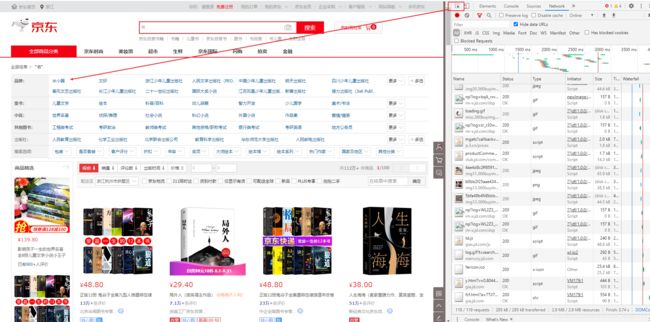
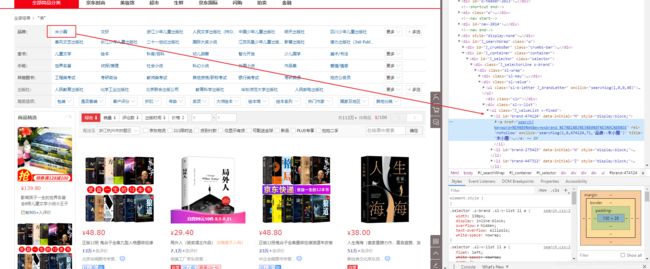
由此可见: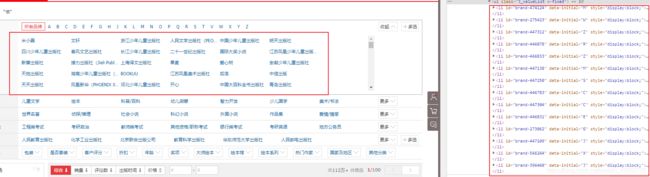
都是一一对应的
每一个分类就一个li标签
有很多个li标签

li标签下面有想要的结果那就需要通过代码获取出来
- 代码
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
import time as ti
def getHTML(URL):
# 加入请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.44'
}
respon = requests.get(URL, headers=headers)
return respon.text
def JXHTML(HTML):
home_Html = BeautifulSoup(HTML, 'html.parser')
li_all=home_Html.find('ul',attrs={'class':'J_valueList v-fixed'}).findAll('li')
for li in li_all:
#每一个品牌的链接
book_ca_url=f"https://search.jd.com/{li.find('a')['href']}"
#品牌名称
book_ca_name=f"{li.find('a')['title']}"
print(book_ca_url,book_ca_name)
if __name__ == '__main__':
url='https://search.jd.com/Search?keyword=%E4%B9%A6&enc=utf-8&pvid=a6b3631d73ee4a3bb23c9703d98f209d'
html=getHTML(url)
结果:
2. 然后开始对一个分类进行解析
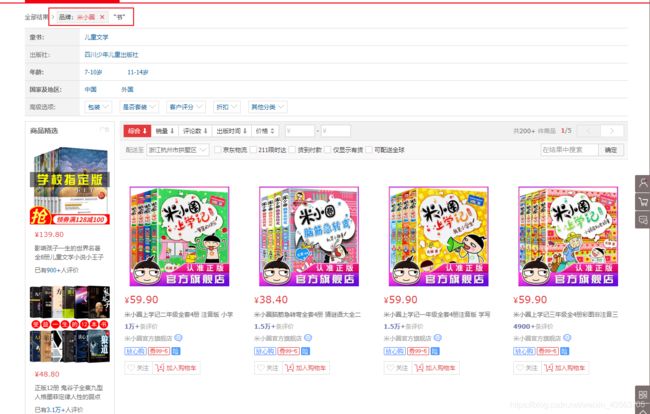
进来之后需要下拉加载所有的商品

获取所有的页码进行翻页

通过selenium 中的模拟点击的方法进行翻页
通过刚刚获取的地址,进行获取一个分类所对应的商品

直接上代码:
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
import time as ti
'''
通过requests获取源网页
'''
def getHTML(URL):
# 加入请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 Edg/84.0.522.44'
}
respon = requests.get(URL, headers=headers)
return respon.text
def JXHTML(HTML):
home_Html = BeautifulSoup(HTML, 'html.parser')
#找到分类的标签,获取所有的分类 因为有多个,使用findAll()
li_all=home_Html.find('ul',attrs={'class':'J_valueList v-fixed'}).findAll('li')
for li in li_all:
#每个分类的地址
book_ca_url=f"https://search.jd.com/{li.find('a')['href']}"
#每个分类的名称
book_ca_name=f"{li.find('a')['title']}"
#模拟打开浏览器
browser =webdriver.Chrome()
print(book_ca_name)
#将分类的地址传给浏览器
browser.get(book_ca_url)
#进行模拟的下拉加载网页
js = "window.scrollTo(0,document.body.scrollHeight)"
#执行
browser.execute_script(js)
ti.sleep(10)
#得到网页的源
ca_source_html=browser.page_source
#对当前分类的第一页商品源进行解析
ca_Html = BeautifulSoup(ca_source_html, 'html.parser')
#获取最大的页码
b_title=ca_Html.find('span',attrs={'class':'p-skip'}).find('b')
b_fy_Number=int(b_title.text)-1
print("-------第一页---------")
# getSource(ca_Html)
getSource(ca_Html)
#对所有的页码进行遍历
for fy in range(b_fy_Number):
print(f"----------第{fy+2}页----------")
#进行点击下一页
browser.find_element_by_class_name('pn-next').click()
ti.sleep(5)
#到了下一页进行下拉加载
js = "window.scrollTo(0,document.body.scrollHeight)"
browser.execute_script(js)
ti.sleep(10)
#获取到当前页的地址
url=browser.current_url
print(url)
ti.sleep(3)
#获取当前页的源
html_fy=browser.page_source
#进行解析
fy_httml = BeautifulSoup(html_fy, 'html.parser')
getSource(fy_httml)
if fy+1==b_fy_Number:
browser.close()
#对每一个商品开始解析了
def getSource(html):
#找到当前页所有商品所对应的地址链接
li_book_All = html.find('ul', attrs={'class': 'gl-warp clearfix'}).findAll('li')
for li_book in li_book_All:
ca_book_url = f"https:{li_book.find('div', attrs={'class': 'p-img'}).find('a')['href']}"
print(ca_book_url)
book_chrome = webdriver.Chrome()
ti.sleep(4)
book_chrome.get(ca_book_url)
ti.sleep(4)
js = "window.scrollTo(0,document.body.scrollHeight)"
book_chrome.execute_script(js)
ti.sleep(5)
# book_chrome.find_element_by_xpath('//li[@clstag="shangpin|keycount|product|pcanshutab"]').click()
book_this_html = book_chrome.page_source
book_this = BeautifulSoup(book_this_html, 'html.parser')
image = book_this.find('img', attrs={'id': 'spec-img'})['src']
imageUrl = f"https:{image}"
# 打折后
strong_price = book_this.find('strong', attrs={'id': 'jd-price'})
strong_priceTxt = ''
if strong_price == None:
strong_priceTxt = strong_price = 'NULL'
else:
strong_priceTxt = strong_price.text
author_name=book_this.find('div',attrs={'class':'p-author'})
author_nameTxt=''
if author_name==None:
author_name='NULL'
else:
author_nameTxt=author_name.find('a').text
# 折扣
strong_discount = book_this.find('span', attrs={'class': 'p-discount'})
strong_discountTxt = ''
if strong_discount == None:
strong_discountTxt = strong_price = 'NULL'
else:
strong_discountTxt = strong_discount.text
# 打折前
maprice = book_this.find('del', attrs={'id': 'page_maprice'})
mapriceTxt = ""
if maprice == None:
mapriceTxt = maprice = 'NULL'
else:
mapriceTxt = maprice.text
book_this.find('td', attrs={'class': ''})
print(author_nameTxt,strong_priceTxt, strong_discountTxt, mapriceTxt, imageUrl)
sql=f"INSERT INTO TABLE `JD_BOOK` VALUES (NULL,'{author_nameTxt}','{strong_priceTxt}','{strong_discountTxt}','{mapriceTxt}',"
ul_li_All = book_this.find('ul', attrs={'id': 'parameter2'})
if ul_li_All ==None:
pass
else:
ul_li_All = ul_li_All.findAll('li')
for li in ul_li_All:
if str(li.text).__contains__("出版时间"):
# print(li['title'])
sql+=f"{li['title']},"
elif str(li.text).__contains__("出版社"):
# print(li['title'])
sql+=f"{li['title']},"
elif str(li.text).__contains__("包装"):
# print(li['title'])
sql+=f"{li['title']},"
elif str(li.text).__contains__("用纸"):
# print(li['title'])
sql+=f"{li['title']},"
elif str(li.text).__contains__("ISBN"):
# print(li['title'])
sql+=f"'{li['title']}','{li['title']}{str(imageUrl)[-4:]}',"
# download(imageUrl,li['title'])
elif str(li.text).__contains__("丛书名"):
# print(li['title'])
sql+=f"{li['title']},"
elif str(li.text).__contains__("套装数量"):
# print(li['title'])
sql+=f"{li['title']},"
elif str(li.text).__contains__("开本"):
# print(li['title'])
sql+=f"{li['title']},"
elif str(li.text).__contains__("正文语种"):
# print(li['title'])
sql+=f"{li['title']});"
# with open('E:\\数据\\京东\\sql\\JB_BOOK.txt','a',encoding='utf-8') as w:
# w.write(sql+'\r')
print(sql)
book_chrome.close()
def download(image_Path,image_Name):
#要将图片存放在哪里
mkdir_Path='E:\\数据\\京东\\img'
r = requests.get(image_Path)
with open(mkdir_Path+'\\'+image_Name+'.jpg', 'wb') as f:
f.write(r.content)
# print('下载成功:' + mkdir_Path + '\\' + image_Name + '.jpg' )
if __name__ == '__main__':
url='https://search.jd.com/Search?keyword=%E4%B9%A6&enc=utf-8&pvid=a6b3631d73ee4a3bb23c9703d98f209d'
html=getHTML(url)
JXHTML(html)