最简单的python 人脸检测
本篇文章是最基本的人脸检测,没有复杂的算法,只是简单的运用了这三个库opencv,numpy,pillow。
一.开发环境搭建
我们使用Python自带的IDLE进行编程,我使用的电脑是Windows系统,代码在win7 64位,win10 64位这两种电脑上验证过。Python版本为3.xx,需要使用的库有opencv,numpy,pillow。这三个库分别使用pip按照即可,指令分别为;
1)opencv;pip install opencv-python
2)numpy;pip install numpy
3)pillow;pip install pillow
所有的文件夹
face_pic 存档获取的照片
转为灰度图片
本文的路径采用自动获取绝对路径
在Python的安装目录,按照这个路径依次打开文件夹Lib→site-packages→cv2→data,复制文件“haarcascade_frontalface_default.xml”,“haarcascade_frontalcatface.xml”到face_identity文件夹,这两个是分类器,用于进行人脸检测。
然后放到我们准备新建的文件夹中,这里我已经整好了,
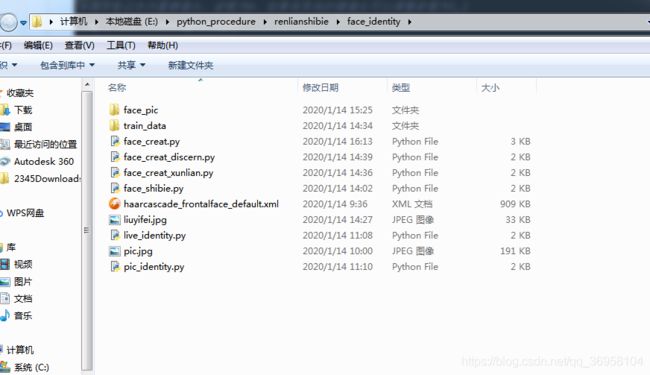
注意
如果提示“module' object has no attribute 'face'”
解决方法:可以输入 pip install opencv-contrib-python解决,如果提示需要commission,可以在后面加上 --user,即 pip install opencv-contrib-python --user
废话不多说,上代码
'''
本程序用于产生800张灰度图片素材用于后续训练人脸识别系统
'''
#-----获取人脸样本-----
import cv2
import os
#调用笔记本内置摄像头,参数为0,如果有其他的摄像头可以调整参数为1,2
cap = cv2.VideoCapture(0)
#调用人脸分类器,获取绝对路径
face_xml_location=os.path.join('.','haarcascade_frontalface_default.xml')
face_detector = cv2.CascadeClassifier(face_xml_location)
#为即将录入的脸标记一个id
face_id = input('\n User data input,Look at the camera and wait ...')
#sampleNum用来计数样本数目
count = 0
while True:
#从摄像头读取图片
success,img = cap.read()
#转为灰度图片,减少程序符合,提高识别度
if success is True:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
else:
break
#检测人脸,将每一帧摄像头记录的数据带入OpenCv中,让Classifier判断人脸
#其中gray为要检测的灰度图像,1.3为每次图像尺寸减小的比例,5为minNeighbors
faces = face_detector.detectMultiScale(gray, 1.3, 5)
#框选人脸,for循环保证一个能检测的实时动态视频流
for (x, y, w, h) in faces:
#xy为左上角的坐标,w为宽,h为高,用rectangle为人脸标记画框
cv2.rectangle(img, (x, y), (x+w, y+w), (255, 0, 0))
#成功框选则样本数增加
count += 1
#保存图像,把灰度图片看成二维数组来检测人脸区域
#(这里是建立了data的文件夹,当然也可以设置为其他路径或者调用数据库)
cv2.imwrite("face_pic/User."+str(face_id)+'.'+str(count)+'.jpg',gray[y:y+h,x:x+w])
#显示图片
cv2.imshow('image',img)
#保持画面的连续。waitkey方法可以绑定按键保证画面的收放,通过q键退出摄像
k = cv2.waitKey(1)
if k == '27':
break
#或者得到800个样本后退出摄像,这里可以根据实际情况修改数据量,实际测试后800张的效果是比较理想的
elif count >= 50:
break
#关闭摄像头,释放资源
cap.realease()
cv2.destroyAllWindows()
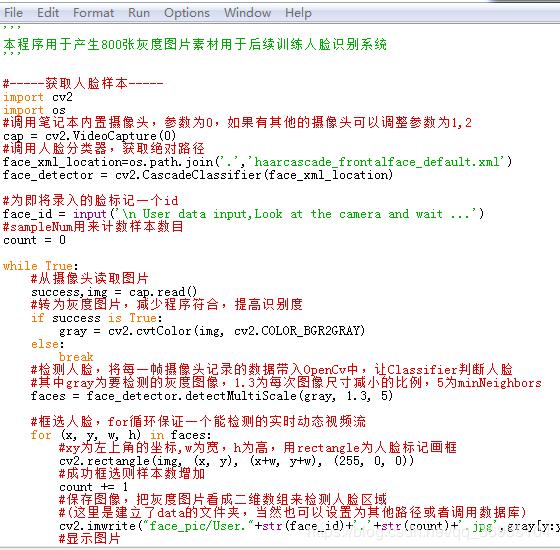
ID用来标示不同人的模型照片
为了方便也可以修改不同的文件夹
经过我的思考决定还是放上照片吧
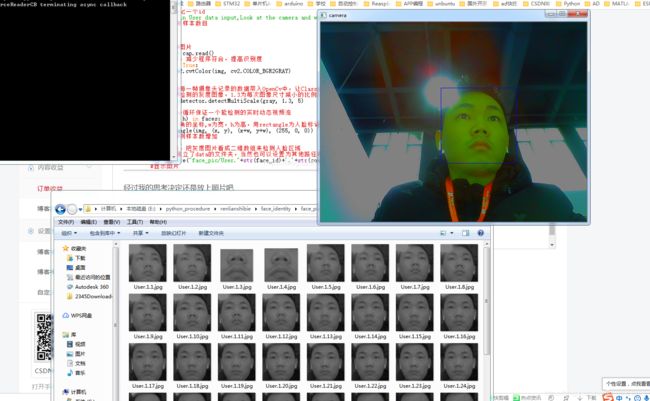
接下来最重要的一步来了
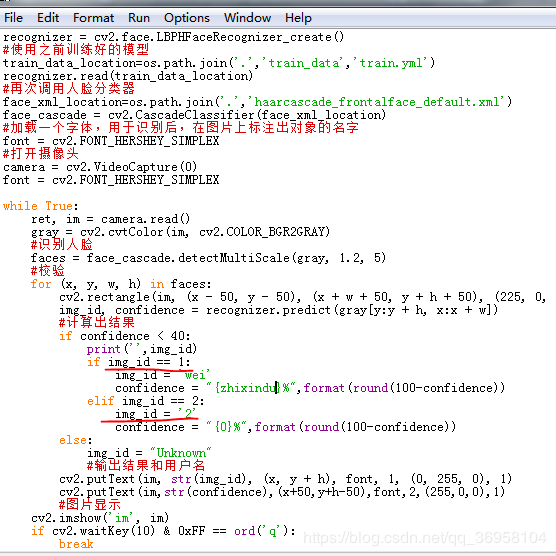
开始模型的分析建立
import cv2
import os
import numpy as np
from PIL import Image
#导入pillow库,用于处理图像
#设置之前收集好的数据文件路径
#获取分类器的路径
face_xml_location=os.path.join('.','haarcascade_frontalface_default.xml')
print('',face_xml_location)
#调用熟悉的人脸分类器
detector = cv2.CascadeClassifier(face_xml_location)
#初始化识别的方法
recognizer = cv2.face.LBPHFaceRecognizer_create()
#创建一个函数,用于从数据集文件夹中获取训练图片,并获取id
#注意图片的命名格式为User.id.sampleNum
def get_images_and_labels(path):
image_paths = [os.path.join(path, f) for f in os.listdir(path)]
#新建连个list用于存放
face_samples = []
ids = []
#遍历图片路径,导入图片和id添加到list中
for image_path in image_paths:
#通过图片路径将其转换为灰度图片
image = Image.open(image_path).convert('L')
#将图片转化为数组
image_np = np.array(image, 'uint8')
if os.path.split(image_path)[-1].split(".")[-1] != 'jpg':
continue
#为了获取id,将图片和路径分裂并获取
image_id = int(os.path.split(image_path)[-1].split(".")[1])
faces = detector.detectMultiScale(image_np)
#将获取的图片和id添加到list中
for (x, y, w, h) in faces:
face_samples.append(image_np[y:y + h, x:x + w])
ids.append(image_id)
print('',image_id)
return face_samples, ids
#调用函数并将数据喂给识别器训练
print('Training...')
tain_data_location=os.path.join('.','train_data','train.yml')
face_data_location=os.path.join('.','face_pic')
faces, Ids = get_images_and_labels(face_data_location)
#训练模型
recognizer.train(faces, np.array(Ids))
recognizer.save(tain_data_location)
根据分类器解析 获取的模型信息倍存放在
最后是我们的人脸检测代码
import cv2
import numpy as np
import os
#准备好识别方法
recognizer = cv2.face.LBPHFaceRecognizer_create()
#使用之前训练好的模型
train_data_location=os.path.join('.','train_data','train.yml')
recognizer.read(train_data_location)
#再次调用人脸分类器
face_xml_location=os.path.join('.','haarcascade_frontalface_default.xml')
face_cascade = cv2.CascadeClassifier(face_xml_location)
#加载一个字体,用于识别后,在图片上标注出对象的名字
font = cv2.FONT_HERSHEY_SIMPLEX
#打开摄像头
camera = cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
while True:
ret, im = camera.read()
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
#识别人脸
faces = face_cascade.detectMultiScale(gray, 1.2, 5)
#校验
for (x, y, w, h) in faces:
cv2.rectangle(im, (x - 50, y - 50), (x + w + 50, y + h + 50), (225, 0, 0), 2)
img_id, confidence = recognizer.predict(gray[y:y + h, x:x + w])
#计算出结果
if confidence < 40:
print('',img_id)
if img_id == 1:
img_id = 'wei'
confidence = "{0}%",format(round(100-confidence))
elif img_id == 2:
img_id = '2'
confidence = "{0}%",format(round(100-confidence))
else:
img_id = "Unknown"
#输出结果和用户名
cv2.putText(im, str(img_id), (x, y + h), font, 1, (0, 255, 0), 1)
cv2.putText(im,str(confidence),(x+50,y+h-50),font,2,(255,0,0),1)
#图片显示
cv2.imshow('im', im)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
#释放资源
camera.release()
cv2.destroyAllWindows()
confidence是置信度,就是预测这个头像为用户id的可信度为conf%
越小越精确
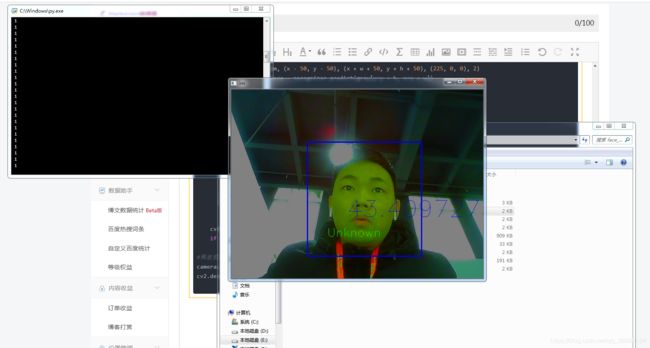
识别不到我们的训练模型太少了
加到300个照片 开始训练
牛逼
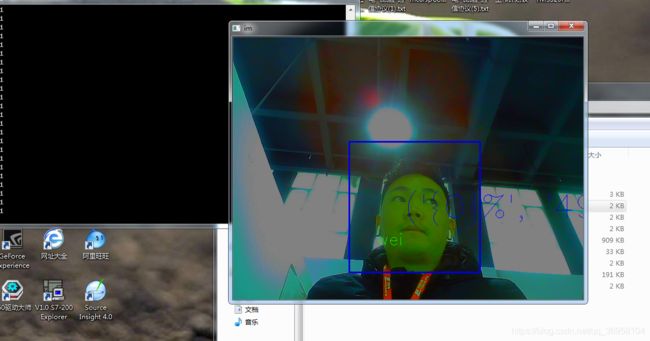
再来一次 800个模型 置信度<30

我曹 达不到30以下 对此我还拿了手机补光,可求刺眼
最后
import cv2
import numpy as np
import os
#准备好识别方法
recognizer = cv2.face.LBPHFaceRecognizer_create()
#使用之前训练好的模型
train_data_location=os.path.join('.','train_data','train.yml')
recognizer.read(train_data_location)
#再次调用人脸分类器
face_xml_location=os.path.join('.','haarcascade_frontalface_default.xml')
face_cascade = cv2.CascadeClassifier(face_xml_location)
#加载一个字体,用于识别后,在图片上标注出对象的名字
font = cv2.FONT_HERSHEY_SIMPLEX
#打开摄像头
camera = cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
while True:
ret, im = camera.read()
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
#识别人脸
faces = face_cascade.detectMultiScale(gray, 1.2, 5)
#校验
for (x, y, w, h) in faces:
cv2.rectangle(im, (x - 50, y - 50), (x + w + 50, y + h + 50), (225, 0, 0), 2)
img_id, confidence = recognizer.predict(gray[y:y + h, x:x + w])
#计算出结果
if confidence < 40:
print('',img_id)
if img_id == 1:
img_id = 'wei'
confidence = "{zhixindu}%",format(round(100-confidence))
elif img_id == 2:
img_id = '2'
confidence = "{0}%",format(round(100-confidence))
else:
img_id = "Unknown"
#输出结果和用户名
cv2.putText(im, str(img_id), (x, y + h), font, 1, (0, 255, 0), 1)
cv2.putText(im,str(confidence),(x+50,y+h-50),font,2,(255,0,0),1)
#图片显示
cv2.imshow('im', im)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
#释放资源
camera.release()
cv2.destroyAllWindows()