纽约出租车案例分析
#过程设计 1)提出问题;2)理解数据;3)数据清理;4)数据分析;5)得出结论
#提出如下问题:1)何时为打车需求高发期?2)居民夜生活情况(根据打车情况推断);3)城市一天当中什么时候最拥堵;
‘’’
表单变量说明:
id - 每次行程的唯一ID
vendor_id - 行程提供者的ID
pickup_datetime - 上车的日期和时间
dropoff_datetime - 停表的日期和时间
passenger_count - 车辆中的乘客数量(驾驶员输入值)
pickup_longitude - 上车的经度
pickup_latitude - 上车的纬度
dropoff_longitude - 下车经度
dropoff_latitude - 下车的纬度
store_and_fwd_flag - 行程记录是否为存储转发(或是直接发送)-- Y =存储和转发 N =没有存储
trip_duration - 行程持续时间(秒)
‘’’
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
from datetime import datetime
#读取数据,并显示部分数据
train=pd.read_csv(r"C:\Users\32715\Desktop\change\New York City Taxi Trip Duration\train.csv")
print(train.shape)
#print(train.head())
train.info()
print(train.describe())
#处理一下异常值,此处乘车时间max值是3.52e+6,近1000小时了,打车这么久不大可能。
#而min值1秒,需要清理一下。按照统计的方法,2个标准差的数据,可视为异常值。
m=np.mean(train['trip_duration'])
print(m)
s=np.std(train['trip_duration'])
print(s)
train=train[train['trip_duration']m-2*s]
train.describe()
vendor_id passenger_count pickup_longitude pickup_latitude \
count 1.458644e+06 1.458644e+06 1.458644e+06 1.458644e+06
mean 1.534950e+00 1.664530e+00 -7.397349e+01 4.075092e+01
std 4.987772e-01 1.314242e+00 7.090186e-02 3.288119e-02
min 1.000000e+00 0.000000e+00 -1.219333e+02 3.435970e+01
25% 1.000000e+00 1.000000e+00 -7.399187e+01 4.073735e+01
50% 2.000000e+00 1.000000e+00 -7.398174e+01 4.075410e+01
75% 2.000000e+00 2.000000e+00 -7.396733e+01 4.076836e+01
max 2.000000e+00 9.000000e+00 -6.133553e+01 5.188108e+01
dropoff_longitude dropoff_latitude trip_duration
count 1.458644e+06 1.458644e+06 1.458644e+06
mean -7.397342e+01 4.075180e+01 9.594923e+02
std 7.064327e-02 3.589056e-02 5.237432e+03
min -1.219333e+02 3.218114e+01 1.000000e+00
25% -7.399133e+01 4.073588e+01 3.970000e+02
50% -7.397975e+01 4.075452e+01 6.620000e+02
75% -7.396301e+01 4.076981e+01 1.075000e+03
max -6.133553e+01 4.392103e+01 3.526282e+06
959.4922729603659
5237.429929188969
train.columns
#将载客时间字段更改为时间格式
datestrs=train['pickup_datetime']
strTime=[datetime.strptime(x, '%Y-%m-%d %H:%M:%S') for x in datestrs]
#print(strTime)
In [4]:
dates = pd.DatetimeIndex(strTime)
train['pickup_YM']=dates.month+100*dates.year
train['pickup_M']=dates.month
train['pickup_weekday']=dates.weekday
train['pickup_date']=dates.day
train['pickup_hour']=dates.hour
train['pickup_daily']=train.pickup_datetime.values.astype("datetime64[D]")
print(train.head(2))
train.head(2)
In [5]:
#对整体数据进行分析,绘制一个坐车持续时间的直方图,感知一下数据。
plt.hist(train['trip_duration'].values,bins=100)
plt.xlabel('trip_duration')
plt.ylabel('number of train records')
plt.show()
#绘制数据线条图,查看是否有相关趋势
plt.plot(train.groupby(‘pickup_daily’).count()[[‘id’]],‘o-’,label=‘train’)
plt.title(‘Trips over time’)
plt.ylabel(‘Trips’)
plt.show()
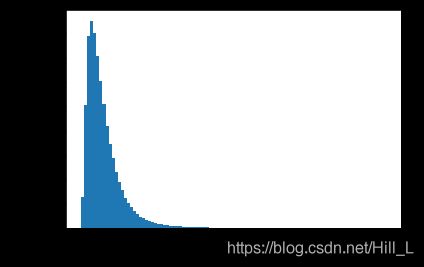

#1月底和5月底数据有异常,可以查看相关新闻是否有什么异常事件发生。
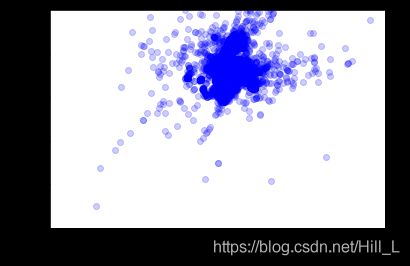
#分析一下上下车的地点,可以查看其总体的乘车地理位置分布图,对于司机与乘客都有意义,取决于分析目的,如乘客的打车便捷度/司机接乘客的概率。
city_long_border=(-75,-73)
city_lat_border=(40,41)
plt.figure()
plt.plot(221)
plt.scatter(train['pickup_longitude'].values,train['pickup_latitude'].values,color='b',label='train',alpha=0.2) #用散点图显示分布是不错的选择。
plt.xlabel('longtitude')
plt.ylabel('latitude')
plt.xlim(city_long_border)
plt.ylim(city_lat_border)
plt.show()
#此处配合GIS处理一下,可视化效果会更好。目的在于学习数据分析,为了节约时间,以后再做。
#这样得出了数据的大体感知。
In [7]:
#print('count by year_month')
#month_trip=month_trip.reset_index()
#train['pickup_M'].value_counts()
In [8]:
print('count by weekday')
train['pickup_weekday'].value_counts()
count by weekday
Name: pickup_weekday, dtype: int64
print('count by date')
train['pickup_date'].value_counts()
count by date
Out[10]:
pickup_M month_sum month_mean month_count
0 1 181332554 790.536858 229379
1 2 187943977 789.740304 237982
2 3 209123747 817.509155 255806
3 4 213019585 847.721054 251285
4 5 219178728 883.332842 248127
5 6 208318003 890.396275 233961
In [11]:
date_trip=train.groupby(['pickup_date'])['trip_duration'].agg(['sum','mean','count'])
date_trip=date_trip.reset_index()
date_trip.rename(columns={'sum':'date_sum','mean':'date_mean','count':'date_count'},inplace=True)
date_trip.pickup_date
date_trip
weekday_trip=train.groupby(['pickup_weekday'])['trip_duration'].agg(['sum','mean','count'])
weekday_trip=weekday_trip.reset_index()
weekday_trip.rename(columns={'sum':'weekday_sum','mean':'weekday_mean','count':'weekday_count'},inplace=True)
print(weekday_trip)
#day_trip.pickup_weekday
#day_trip.weekday_sum
pickup_weekday weekday_sum weekday_mean weekday_count
0 0 151634299 809.977667 187208
1 1 173134321 855.102538 202472
2 2 184575543 879.408550 209886
3 3 195761107 896.851266 218276
4 4 193467954 866.822978 223192
5 5 171610193 778.369300 220474
6 6 148733177 762.609095 195032
In [15]:
hour_trip=train.groupby(['pickup_hour'])['trip_duration'].agg(['sum','mean','count'])
hour_trip=hour_trip.reset_index()
hour_trip.rename(columns={'sum':'hour_sum','mean':'hour_mean','count':'hour_count'},inplace=True)
hour_trip.pickup_hour
hour_trip
plt.figure(figsize=(20,20))
plt.subplot(321)
ax1=plt.plot(weekday_trip.pickup_weekday,weekday_trip.weekday_count,color='g',marker='*')
plt.title("weekday Trip counts")
plt.ylabel('# of trip times', fontsize=12)
plt.xlabel('Pickup_weekday', fontsize=12)
plt.subplot(322)
ax2=plt.plot(month_trip.pickup_M,month_trip.month_count,marker='*')
plt.title("Monthly Trip counts")
plt.ylabel('# of trip times', fontsize=12)
plt.xlabel('Pickup_M', fontsize=12)
plt.subplot(323)
ax3=plt.plot(month_trip.pickup_M,month_trip.month_mean,color='r',marker='*')
plt.title('pick_Month_mean')
plt.ylabel("# of trip month_mean")
plt.xlabel('Pickup_Month')
plt.subplot(324)
ax4=plt.plot(date_trip.pickup_date,date_trip.date_sum,marker='*')
plt.title("date Trip counts")
plt.ylabel('# of trip times', fontsize=12)
plt.xlabel('Pickup_date', fontsize=12)
plt.show()

#周三周四打车次数最多;
#1-3月,打车人数呈增长状态,到3月到顶峰,之后回落。
#平均打车时长1-6月呈增长趋势。
#整体打车时间稳定在4.5,月中有一次峰顶值,下旬有一次峰谷值。
In [45]:
#重新构建一个用于分析的表格数据
trip2=train.groupby(['pickup_M','pickup_weekday','pickup_hour'])['trip_duration'].agg(['count','mean'])
trip2=trip2.reset_index()
#trip2['avg_passenger_count']=train.groupby('passenger_count').mean()
trip2.head(31)
#看下数据是否靠谱
#1月1日星期四,分组还算合理,注意一下这里的多重分组。
trip2=train.groupby(['pickup_M','pickup_weekday','pickup_hour'])['passenger_count'].agg(['count','mean'])
trip2=trip2.reset_index()
trip2['avg_passenger_count']=trip2['mean']
trip2.head(31)
plt.figure(num=2,figsize=(12,10))
sns.boxplot(x='pickup_weekday',y='mean',hue='pickup_M',data=trip2)
plt.show()
plt.figure(num=2,figsize=(12,10))
sns.boxplot(x='pickup_weekday',y='count',hue='pickup_M',data=trip2)
plt.show()
#做一下分析
#1)

In [69]:
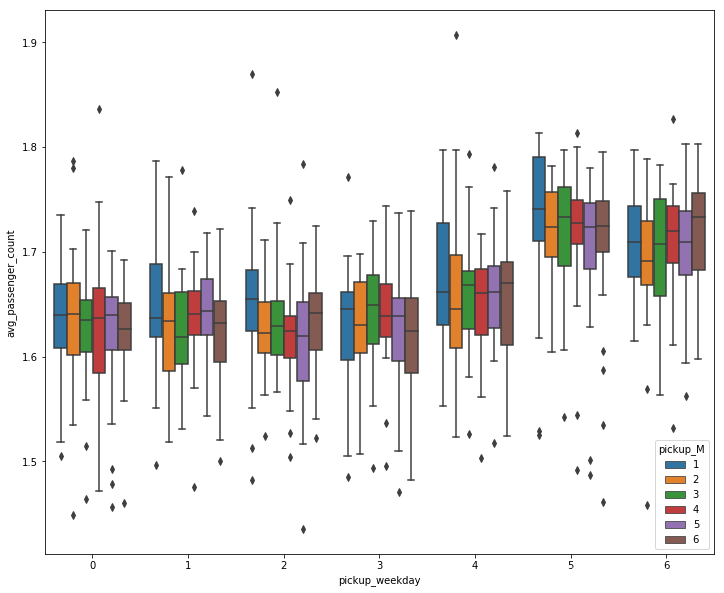
plt.figure(num=2,figsize=(12,10))
sns.boxplot(x='pickup_weekday',y='avg_passenger_count',hue='pickup_M',data=trip2)
plt.show()
#由图可知,周五,周六多人结伴出行的情况多很多
In [81]:
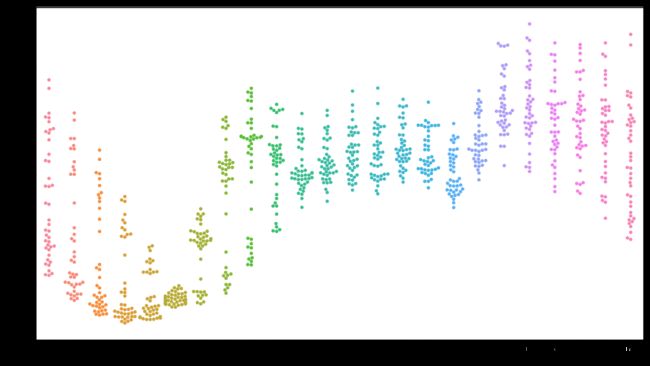
plt.figure(figsize=(16,9))
sns.swarmplot(x='pickup_hour',y='count',data=trip2)
plt.show()
#1-5点乘客汽车量下降,6点开始回升。司机开始出车。
#9-16点相对平衡,此刻为乘客上班时间。
#18点数量增加,下班了。16点的数量是相对较差的,可能是司机在交班之类,无心载客。
plt.figure(figsize=(16,9))
sns.stripplot(x='pickup_hour',y='mean',data=trip2)
plt.show()
#早上单独出行的概率较高。即5-8点。

就先到这里了。
格式有点乱,对这个博客的使用方法也不是太熟悉,现在重点放在学习数据分析的技能提升上。
Python在面对大量数据处理时,有着excel不能企及的优势。
不过可读性可能没有传统的编码那么,因为要放在很多函数的记忆上。
后面随着学习的深入,如果有时间会对内容做进一步的优化,加工,一步步来。
最近看到一句话,挺有启发:学习的要义在于重复(原话不是这样,不过要表达的是这个意思)
勤加练习,希望对python的pandas和matplotlib都很熟练一些。
做数据分析,技能假以时日,都会学会的吧,重点在于关注数据背后的现实逻辑,即在商业里面商业逻辑和业务逻辑。这样才能基于数据的呈现,对现实决策起到更好的一个助攻。