基于Python的Scrapy静态网页爬取
基于Python的Scrapy静态网页爬取
- 1.创建工程
- 2.我们的第一个爬虫
- 3.如何运行我们的爬虫
- 4.幕后发生了什么
- 5.start_requests方法的捷径
- 6.提取数据
- 7.XPath简介
- 8.提取引用和作者
- 9.从我们的爬虫中提取数据
- 10.存储爬取的数据
假设你的电脑上已经安装了Scrapy。
这篇教程将会带你学习以下任务:
- 新建一个Scrapy工程
- 编写一个爬虫爬取一个网站并提取数据
- 使用命令行输出爬取的数据
- 将爬虫改成递归跟踪链接(recursively follow links)
- 使用爬虫参数
我们进入正题吧 ~
1.创建工程
在你开始爬取网页数据之前,你需要新建一个Scrapy工程。输入一个你希望存储你的代码的目录并运行。
这样会建立一个tutorial目录,包含以下内容:
tutorial/
scrapy.cfg #部署配置文件
tutorial/ #工程的Python模块,你将从这里导入你的代码
__init__.py
items.py #工程项目定义文件
pipelines.py #工程传输线文件
settings.py #工程设置文件
spiders/ #之后存放你的爬虫的目录
__init__.py
2.我们的第一个爬虫
爬虫(Spiders)是你定义的类,Scrapy使用爬虫从一个网站(或者一组网站)爬取数据。爬虫必须有scrapy.Spider子类,并且定义要制定的初始需求,另外还要能跟踪页面内的链接,解析下载的页面内容到提取的数据中。下面是我们的第一个爬虫的代码。使用你的Python可视开发环境(PyCharm、Spyder等等)把下面这段代码在前面建立的工程目录tutorial/spiders下保存为quotes_spider.py:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_request(self)
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/'
]
for url in urls:
yield scrapy.Request(url=url,callback=self.sparse)
def parse(self,response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html'%page
with open(filename,'wb') as f;
f.write(response.body)
self.log('save file %s' % filename)
你可以看到,我们的爬虫构造了一个子类scrapy.Spider,定义了一些归属关系和函数。
name:用于辨别这个爬虫。name在工程内必须是独一无二的,也就是说,你不能给不同的爬虫设置相同的name。
start_requesst():必须返回Requests的迭代值(你可以返回一个请求表或者编写一个生成器函数),爬虫将从Requests开始爬取数据。后续的请求将会从这些初始请求中产生。
parse:这是一个被调用的函数,用来处理为每一个请求下载的相应的响应。
parse函数通常解析响应,把爬取的数据当做字典来提取,并且找到新的可追踪的URL,还从这些URL中产生新的请求。
3.如何运行我们的爬虫
要让我们的爬虫工作起来,切换到工程的顶层目录并运行:scrapy crawl quotes
这个命令将会运行我们刚刚添加的名为quotes的爬虫,并会向域名quotes.toscrape.com发送一些请求。
你将得到类似于下面这样的输出:
... (omitted for brevity)
2016-12-16 21:24:05 [scrapy.core.engine] INFO: Spider opened
2016-12-16 21:24:05 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2016-12-16 21:24:05 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2016-12-16 21:24:05 [scrapy.core.engine] DEBUG: Crawled (404) (referer: None)
2016-12-16 21:24:05 [scrapy.core.engine] DEBUG: Crawled (200) 实际大概是这样,截图中爬取网页的操作细节可以实际去看:
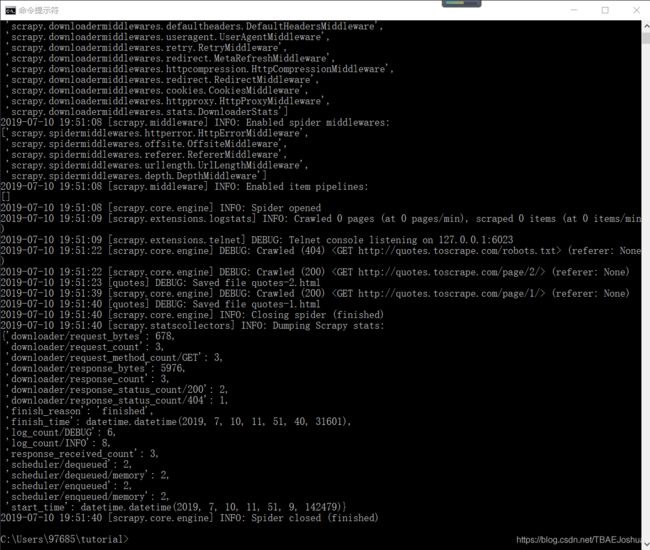
现在,你可以到tutorial顶层目录中查看。你会发现新增了两个文件:quotes-1.html 和 quotes-2.html

4.幕后发生了什么
Scrapy通过Spider爬虫的start_request方法安排scrapy.Request对象。一旦接收到其中一个的响应,Scrapy就把Response对象实例化,并且调用与请求有关的callback方法(本例子中就是parse方法)。5.start_requests方法的捷径
你可以不使用start_requests()函数从URL产生scrapy.Request对象,start_requests方法的捷径就是定义一个有一系列URL的start_urls的类。这个表将会被start_request()函数默认调用来产生你的爬虫的初始请求:import scrapy
class QuotesSpider(scrapy.Spider)
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/'
]
def parse(self,response)
page = response.url.split("/")[-2]
filename = 'quotes-%s.html'%page
with open(filename,'wb') as f:
f.write(response.body)
parse()函数将会被调用来处理那些URL的每一个请求,尽管我们并没有明确地告诉Scrapy这样去做。这是因为,parse()函数是Scrapy的默认回调函数。
6.提取数据
学习怎样提取数据的最好的方式就是使用Scrapy shell。运行下面的程序:scrapy shell 'http://quotes.toscrape.com/page/1'
NOTE:注意,在Windows上要是用双引号把URL地址括起来。
你将会看到类似下面的结果:

由于是境外网站,TCP传输被阻断,实际无法提取数据,大家想试验可以将URL改成国内网站,注意网站需要是静态技术搭建的。
使用shell,你可以尝试使用CSS(Selectors Level 4)选择对应的数据内容。

运行response.css(‘title’)的结果是一个列表样式的对象SlectorList,这个列表代表了一系列的Selector对象环绕着XML和HTML元素,允许你进行精细选择或者提取数据。
要想把上面的titile中的文本提取出来,你可以运行如下:

由于我们并未从境外网站提取到数据,所以输出out那里没有内容显示。
7.xPath简介
8.提取引用和作者
9.从我们的爬虫中提取数据
10.存储爬取的数据
未完待续,敬请期待 ^ _ ^