一、程序分析
1、第一次作业
设计思路:第一次作业相对来说还是比较简单,涉及到的因子只有幂函数和常数,所以我采用了很自然的思路,即设计一个Poly类,其中包括一个HashSet和一个HashMap,前者用来存多项式的各个幂,后者用来存相应的幂对应的系数,再分别写一个相加的方法和求导的方法即可,而且利用HashSet的特点,在相加时即可完成合并同类项的工作。至于输入的处理我放在了主类中,主要是靠正则表达式来筛选出各个项。
UML类图
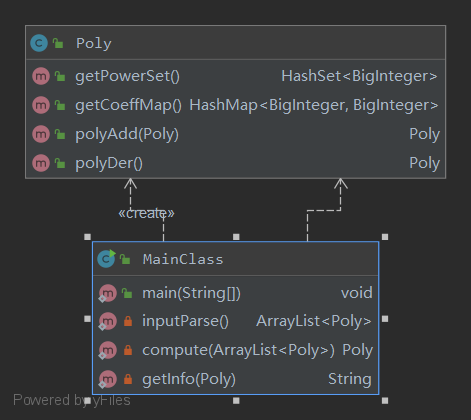
类和方法的规模

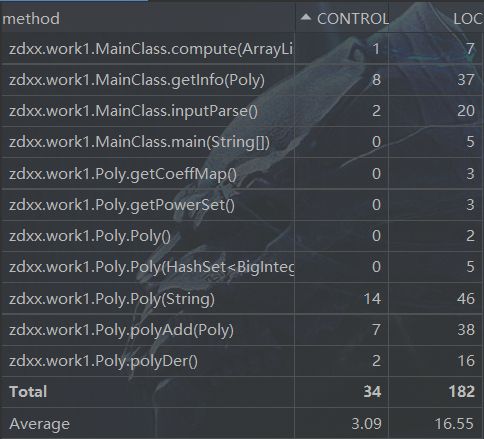
方法复杂度
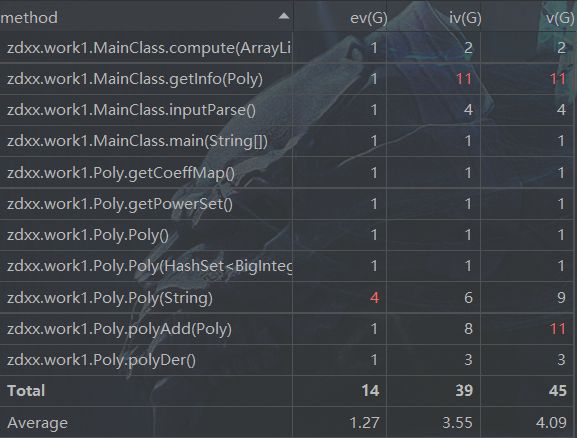
反思:但是虽然需求看起来简单,我还是出现了一个在提交前没有查出的bug,那就是在用迭代器遍历HashSet时,调用了HashSet自身的remove()方法,导致出现了ConcurrentModificationException,虽然这样的失误导致强测有几个点没有通过,但是这也提醒了我要关注一些现有轮子的源代码,增强理解。同时也能看到有两个方法圈复杂度较高,这使得测试难度加大,以后还是要多多注意。
2、第二次作业
设计思路:通过分析指导书可以发现项的一般形式是a·xb·sinc(x)·cosd(x),所以我设计了一个BaseTerm类,用来封装(b,c,d)的三元对,在Term类中实例化一个BaseTerm对象和一个BigInteger,分别表示项的幂和系数,并且为其写了求导方法和toString()方法,最后设计了一个Poly类,包含一个HashMap
UML类图

类和方法规模
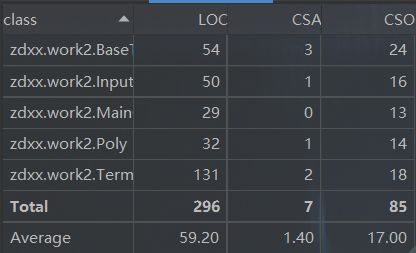
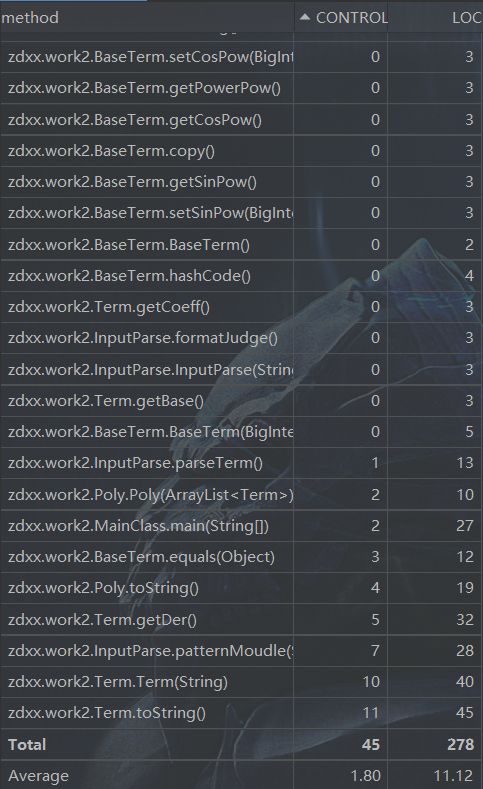
方法复杂度

反思:虽然这次作业没有出现什么bug,但是基本上是对第一次作业进行了重构,没有体现作业的迭代思想,而且可以看到代码的耦合度较高,部分方法严重非结构化,增大了测试和维护的难度。同时,在性能的优化的方面也只是做到了最简单的合并同类项,没有通过三角函数的优美性质进一步的优化,仍有较大的改进空间。
3、第三次作业
设计思路:这次作业相比前两次难度有了较大的提升,主要是引入了表达式因子和嵌套关系,虽然内部关系很难理清,但是依据面向对象的思想,我首先设计了四个基本因子类:常数类(Constant)、三角函数类(Sin,Cos)、幂函数类(Power),它们都实现了求导接口,重写了toString()方法用于计算和输出,而且考虑到嵌套关系,除常数类外他们都包含一个Derivative(Derivative即为我设计的求导接口)的属性来表示其嵌套的内容;再从运算关系方面考虑,我又设计了加法类(Add)、减法类(Subtract)、乘法类(Multiply),它们都相应实现了求导接口并重写了toString()方法,当然最后要设计一个变量类(Var),不然依据我的思路就递归不下去了。
这些解决之后就要来考虑一下对输入的解析,在判断格式和解析输入方面,我都采取了统一的策略,即设计一个ArrayList储存括号的位置,再从内到外解析括号。判断格式时,只需要每次分析括号里面的是不是表达式或因子(后者是对于三角函数来说的),是则将其中的内容换为无关符号(这里我采用的是等长度的"@"串),然后继续下去直至结束,否则直接判断格式错误。解析输入的话,我设计了一个Factory类,其中的getPloy()方法可以根据传入的字符串返回一个Add类的对象(因为输入的最顶层运算一定是加法),它也就是传入字符串对应的表达式,同时我们还需要一个ArrayList来储存括号内部的表达式,这样在getPoly()接收的字符串中含有"@"串时,即可从中调出对应的表达式生成更外层的表达式。
完成这些之后,我们会得到一个Add类的对象,只需调用其tostring()方法即可完成输出。
UML类图
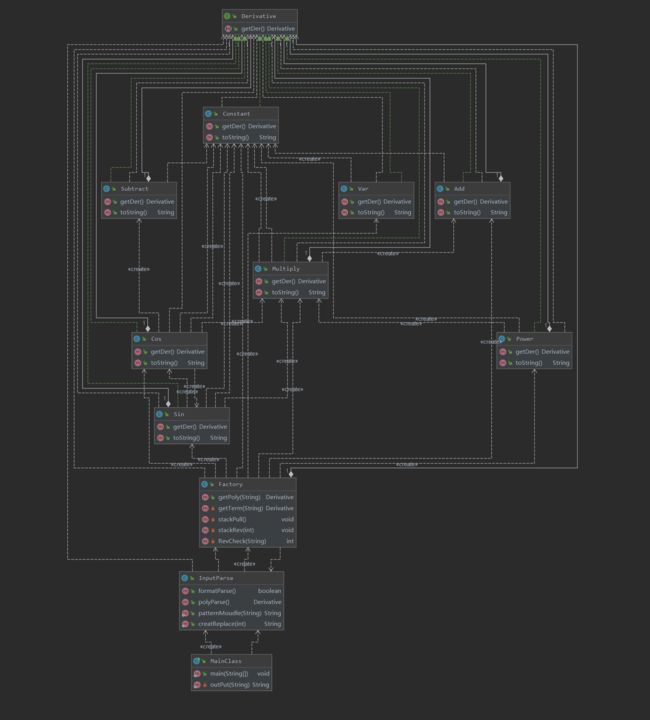
类和方法规模
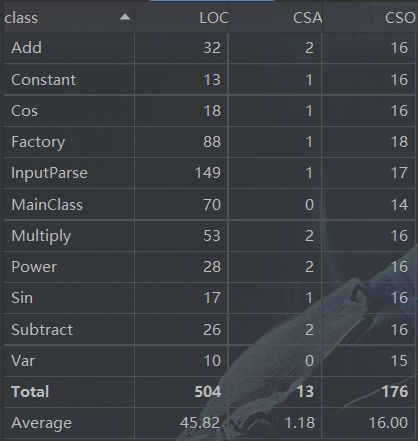
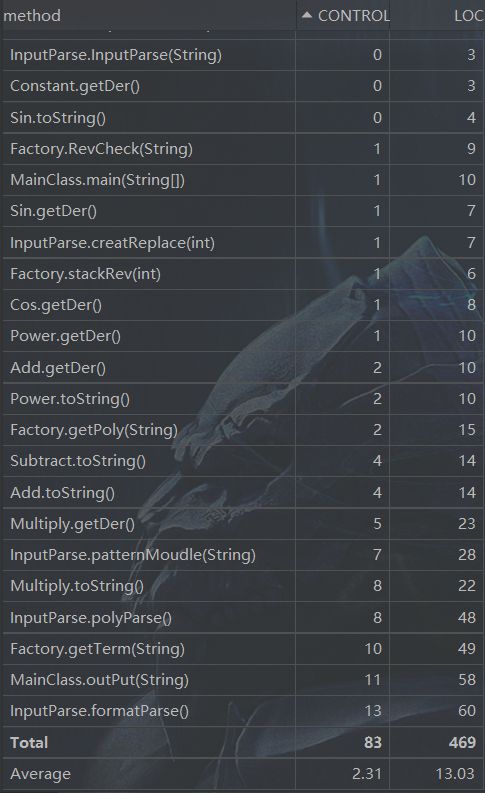
方法复杂度

反思:这次作业出现了两个bug,(可能加之代码有些冗余)导致在互测中被疯狂hack,其一是对于两个表达式相减或是乘以-1的情况,在相应的toString()方法返回的字符串中没有加上括号,二是由于设计的疏忽,导致在取出ArrayList中存放的表达式时其顺序出现错误。
由于第二次作业的可扩展性太差,所以这次又是重构,但是从这次重构中能够感到自己的设计思路又有了一定的面向对象的改善,至少在构思之初首先想到的是对象的设计而不是过程的分析,但是很明显,代码的耦合程度和一些方法的非结构化仍然较高,圈复杂度也是稳步提升,这仍是以后要坚决改善的地方,同时在优化方面也做的不足,只是去除了部分冗余的括号、0、1,在同类因子合并,提取公因式,展开合并等方面还可以继续改进。
二、测试策略
笔者无论是对自己代码进行测试时还是在互测时,都采取的相同的策略。
第一次作业中,是手动构造测试集,但感觉覆盖面不够,主要从以下几个方面:较为复杂的多项式,出现两个加减号相连的情况,系数或指数缺省的情况,各个合法的位置出现空白符的请况;
第二次作业中,由于听取了讨论课中同学分享的经验,我尝试搭建了一个自动测试平台,但是由于一些技术上的原因,只能实现半自动,主要用于根据正则表达式随机生成测试数据,但由于随机性较高,出现的大多是一般化的表达式,所以我还对一些特殊的缺省情况进行了手动构造,对于格式错误的数据,则主要从非法字符,指数限制,加减号的连续出现等方面考虑。
第三次作业中,又回归手动构造,主要针对嵌套过多,缺省情况,括号冗余,三角函数的括号中为常数等情况进行了测试,而对于格式错误的测试的考虑除了第二次作业中的几种,还增加了括号不完全匹配,三角函数中出现非因子的情况。
三、运用对象创建模式重构
这三次作业中,笔者只在最后一次作业的重构中采用了工厂模式,通过传入的字符串生产表达式,但是用的也比较牵强,主要是工厂模式的一大特点就是降低耦合度,但是由于我的设计思路的原因,导致Factory类不完全复制了输入解析类中一个方法的局部变量,使其高度耦合,没有达到应有的效果。
四、心得与体会
通过三次迭代式的作业,能感到自身的面向对象的思维正在逐步建立,通过阅读讨论区的评论,也学会了一些自己没有想到或是找到的方法,但在今后的训练中仍需注意以下几个方面:
1、代码更结构化,尽量降低耦合度
2、通过一些更好的方法来减少冗余的代码
3、注重代码的可扩展性,不要每次都重构
4、完善自动测评