一、JML理论基础
JML是一种规格化的语言,通过逻辑性极强的表述方式和一套公认的标准化语法,可以很大程度上消除自然语言表述时带来的二义性,方便多人开发。根据近三次作业中出现的规格,主要的一些比较特殊的语法总结如下:
normal_behavior : 正常情况
exceptional_behavior : 抛出异常的情况
requires : 前置条件
assignable : 副作用
ensures : 后置条件
signals : 用以定义抛出异常的类型和条件
\forall : 表示满足后面所给条件的所有元素
\exists : 表示存在满足后面所给条件的元素
\old : 表示属性未被方法修改前的状态
\sum : 表示所有满足条件的表达式求和
\result : 表示该方法的返回值
<==> : 表示前后等价
==> : 表示前可推出后
此外,JML还支持在规格中直接使用以/*@pure@*/标记的纯方法。
二、JML相关工具链
主要的工具包括OpenJml、JMLUnit、JUnit4等,其中Openjml主要用于做JML语法检查和规格的静态检查,课程组建议部署SMT Solver,个人感觉两者功能差不多,而且OpenJml也自带z3,具体是个什么关系本人也不是很清楚,希望能有个完整的教程,JMLUnit可以根据规格自动生成测试用例,JUnit4则是用以进行单元测试。
OpenJml
java -jar D:\IDEA\openjml\openjml.jar -check .\Person.java
本人采用如上命令对第九次作业中的官方包里的Person.java文件进行了JML语法检查,最后没有任何输出,表示没有语法错误,然而开始检查NetWork.java时就出现了以下问题:
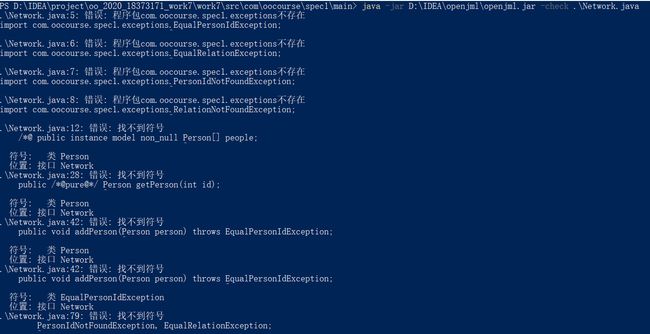
应该是检查的过程中与其他类产生了关联,但是目前也没有找到什么方法可以在命令中加上其他类(其实最后参考J哥的方法,发现只要把这些java文件放在一个包里就行了,但感觉还是有些麻烦,希望有高人指点一下怎么直接在命令里把依赖包加进去,要是可以的话),所以本人自己写了一个test.java来进行检查,结果如下:

令人欣喜的是,它似乎找到了我故意写的将\result赋值的错误和ensuers后没有加分号的错误,至于其他报错,本人怀疑是它一并将实现代码作为JML检查了,毕竟我将实现代码删去后,这些报错就消失了。
然后本人利用OPenJml内置的z3对上述三个类进行了静态检查,结果和之前的检查基本一致。
java -jar D:\IDEA\openjml\openjml.jar -prover z3 -exec D:\IDEA\openjml\Solvers-windows\z3-4.7.1.exe -esc .\xxx.java
JMLUnit
本人按照讨论区里的方法进行了尝试,即将Group.java和Person.java放到test包下,然后执行如下指令:
java -jar D:\IDEA\openjml\jmlunitng.jar test\Group.java javac -cp D:\IDEA\openjml\jmlunitng.jar test\*.java java -jar D:\IDEA\openjml\openjml.jar -rac test\Group.java test\Person.java java -cp D:\IDEA\openjml\jmlunitng.jar test.Group_JML_Test
但是执行到第三条时,出现了如下报错:
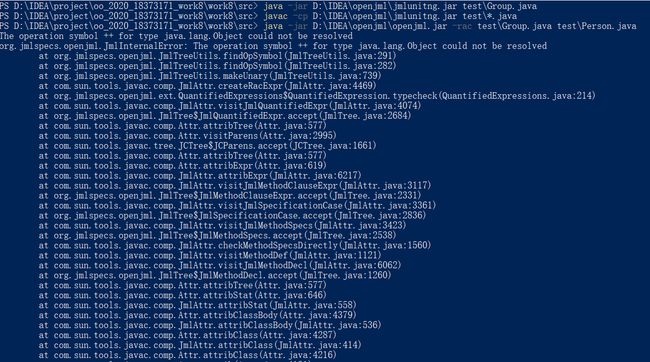
通过这个反馈,本人感觉不是我的Group.java和Person.java含有“++”,用grep搜了一下也没有结果,几次尝试后无果,就在此夭折了。
JUnit4
虽然课程组一直推荐单元测试,但是本人在第十次作业中尝试了一下后,感觉用处不是很大,一是操作较为繁锁,那些断言还是要自己去根据JML选择构造,二是就算发现了错误,也难以精确定位,实验课上通过单元测试找到了一些错误,但是去方法中寻找时,还是要借助一些其他的手段,再就是就算JMLUnit构造数据成功了,通过其他同学的博客也发现测试数据覆盖面很窄。
三、架构设计与bug分析
第九次作业
这次作业还是相对简单,只要读懂JML就没有太大的问题,而且在性能上也很宽松,重点方法应该就只有isCircle,本人没想太多,直接用DFS实现,幸运的是本次作业没有被找出bug。
第十次作业
这次作业的话,难点在于Group里新加的getRelationSum和getValueSum两个方法,最开始设计时采用的是O(n^2)的每次都遍历查询的方法,但是果然CTLE了,在修复的时候就对这relationSum和valueSum进行了缓存,每次往组里加人或添加关系时就进行更新。除此之外,互测时在isCircle上也被卡了CTLE,最后决定在每次调用isCircle后,都将访问过的连通图保存下来,下次调用时,若节点都在保存的连通图内,则可以直接返回true。
第十一次作业
这次作业的难点放到了对图的操作上面,主要就是三个拦路虎:最短路径(queryMinPath)、点双连通(queryStrongLinked)和连通块数(queryBlockSum)。最短路径采用了堆优化的迪杰斯特拉算法,但是因为缓存时的大意,导致没有存完就返回了,使得后续调用该方法时,两个连通的点也被我判断为了不连通(因为有一个点就属于没存完的那部分),我也因此在强测中WA掉了三个点,当然最后我修改了缓存的代码,bug也被轻松修复;判断点双连通时,我就采用了tarjin算法,但是不幸的时,由于思考的不周全,我采用了简单的染色方案,但是这样如果遇到”8“字形的图结构,就会将他们都划归到一个点双连通分量中,而这显然是不对的,我也因此在互测时被人hack,最后我决定在每次出现dfn = low的情况时就直接退栈,看看退出的节点中是否包含要查询的两个节点,而如果没有找到且当前节点还有没有访问的邻边时,就将这个节点重新入栈,这样就成功解决了”8“字形图的问题;至于连通块数的话,我简单地采用DFS实现,遍历的总次数就是连通块的个数。UML图如下:

小结
回过头来看,本单元的作业主要需注意一下几个方面:
1、整体架构:听过了老师的讲解,我就属于那种把所有方法实现在一个类中的人,没有进行层次化设计,现在想来,对于那些考察图的方法,完全可以另外设计一个类来单独处理,每加一个人或一个关系就通过类之间的通信,为这个类保存的图增加一个节点或一条边,这样将功能分隔开,就能使得MyNetWork类不那么臃肿。
2、算法复杂度的考量:这三次作业因为CTLE失的分并不少,在实现方法的时候,就应该尽量选择能想到的最优的方法,而不是为了图简单去强测那里碰运气,其实在第十一次作业最开始的时候我就是这么想的,而后还是不放心,去了解了一下堆优化的迪杰斯特拉和tarjin算法,现在想来,要是不这样估计就不仅仅是三个WA这么简单了。
3、容器的选择:这点上我还是比较明智,没有生硬地按照JML使用静态数组和ArrayList,而是更多的采用了HashSet和HashMap,同时也尝试使用了PriorityQueue和Stack,性能上确实提高了不少,但是通过讨论课上同学的分享了解了底层实现后,我发觉还是有些要注意的地方,比如HashMap中entrySet,keySet和value的选取。
4、缓存的设计:这几次作业中最大的问题出在了缓存上,就现在看来我的缓存方式也有些勉强,最后才发现用上并查集的话,就可以去掉很多冗余的缓存,而且可以减少对DFS的依赖,可惜自己实现时没有想到。
四、寻找他人bug的策略
这三次互测中主要采用两种方式找他人bug:
1、手动构造特殊数据,比如对某一高复杂度的方法反复调用等,来卡CTLE;
2、自动随机生成测试样例,将跑过的结果和自己程序结果比对。
可笑的是,第十一次作业中原以为终于找到了一个bug,到头来原来是自己程序错了。
五、心得体会
这单元总的来说还是收获颇丰的,一是系统地了解了JML和其相关的一整套工具链,就算再怎么不会用,了解新知识还是很好的;二是学会了几个新算法,比如堆优化的迪杰斯特拉、tarjin和并查集;三就是对数据结构和图论的知识进行了复习和巩固。但是不足也是显而易见的,最核心的就是在整体的架构上没有实现很好的层次化,导致了代码的臃肿,在今后的练习中要更加注意。