【sharding-sphere】 - 01 SQL路由

●【Nacos源码分析】- 02 获取配置流程
●【Nacos源码分析】- 01 ConfigService创建流程
●【Java并发编程】- 03 MESI、内存屏障
●【Spring源码】- 11 Spring AOP之编程式事务
●【编程开发】- 01 日志框架
概述
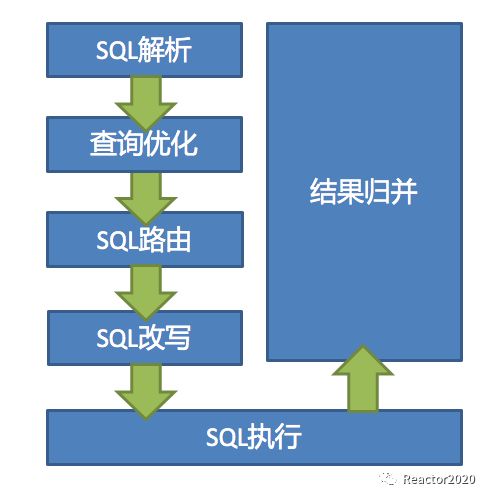
SQL路由是Sharding-jdbc数据分片核心流程中非常重要的一个流程(见下图),通过SQL路由决定了SQL具体会在哪些库上触发,以及具体对应的物理表是哪些等等,这节就来分析下SQL路由的流程。
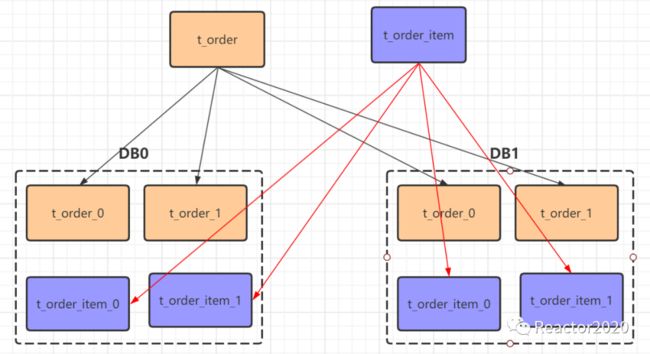
如下图,先对表t_order和表t_order_item进行分库分表,它们分片规则都一致:根据user_id % 2 逻辑进行分库,并根据order_id % 2 逻辑进行分表。
对应编程方式实现如下:
package binding;
/**
* @author zhang_zhang
* @Copyright © 2020 tiger Inc. All rights reserved.
* @create 2020-06-07 21:30
*/
@Slf4j
public class BindingTableTest {
//数据源
private Map dataSourceMap = new HashMap<>();
//分片规则
private ShardingRule shardingRule;
//数据库类型
private MySQLDatabaseType databaseType = new MySQLDatabaseType();
/**
* 创建数据源
* @return
*/
private void dataSourceMap(){
// 配置第一个数据源
HikariDataSource dataSource1 = new HikariDataSource();
dataSource1.setJdbcUrl("jdbc:mysql://localhost:3306/ds0?serverTimezone=UTC");
dataSource1.setUsername("root");
dataSource1.setPassword("123456");
dataSourceMap.put("ds0", dataSource1);
// 配置第二个数据源
HikariDataSource dataSource2 = new HikariDataSource();
dataSource2.setJdbcUrl("jdbc:mysql://localhost:3306/ds1?serverTimezone=UTC");
dataSource2.setUsername("root");
dataSource2.setPassword("123456");
dataSourceMap.put("ds1", dataSource2);
}
private void shardingRule(){
//1.创建ShardingRuleConfiguration
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderRule());
shardingRuleConfig.getTableRuleConfigs().add(orderItemRule());
List dbs = Arrays.asList("ds0", "ds1");
this.shardingRule = new ShardingRule(shardingRuleConfig, dbs);
/* List tableRules = (List) this.shardingRule.getTableRules();
BindingTableRule bindingTableRule1 = new BindingTableRule(Arrays.asList(tableRules.get(0)));
BindingTableRule bindingTableRule2 = new BindingTableRule(Arrays.asList(tableRules.get(1)));
this.shardingRule.getBindingTableRules().add(bindingTableRule1);
this.shardingRule.getBindingTableRules().add(bindingTableRule2);*/
}
private TableRuleConfiguration orderRule(){
// 配置Order表规则
TableRuleConfiguration orderTableRuleConfig =
new TableRuleConfiguration("t_order","ds${0..1}.t_order_${0..1}");
// 配置分库 + 分表策略
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_id", new MyPreciseShardingAlgorithm()));
orderTableRuleConfig.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("order_id", new MyPreciseShardingAlgorithm()));
return orderTableRuleConfig;
}
private TableRuleConfiguration orderItemRule(){
// 配置Order表规则
TableRuleConfiguration orderTableRuleConfig =
new TableRuleConfiguration("t_order_item","ds${0..1}.t_order_item_${0..1}");
// 配置分库 + 分表策略
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("user_id", new MyPreciseShardingAlgorithm()));
orderTableRuleConfig.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("order_id", new MyPreciseShardingAlgorithm()));
return orderTableRuleConfig;
}
@Before
public void init(){
this.dataSourceMap();
this.shardingRule();
}
}
现在我们要执行表t_order和表t_order_item关联查询(如下),现在我们就来分析下SQL路由是如何处理这条查询SQL得到。
String sql = "SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE (o.order_id = 10 and o.user_id=20) or o.order_id = 11";
核心入口
SQL路由入口是ShardingRouteDecorator#decorate这个方法:
public RouteContext decorate(final RouteContext routeContext, final ShardingSphereMetaData metaData, final ShardingRule shardingRule, final ConfigurationProperties properties) {
//SQLStatementContext主要包含SQLStatement,而SQLStatement是对SQL解析后内容的封装
SQLStatementContext sqlStatementContext = routeContext.getSqlStatementContext();
//sql中?对应的实参列表
List大致说明:
SQLStatement是对SQL解析的封装(见下图):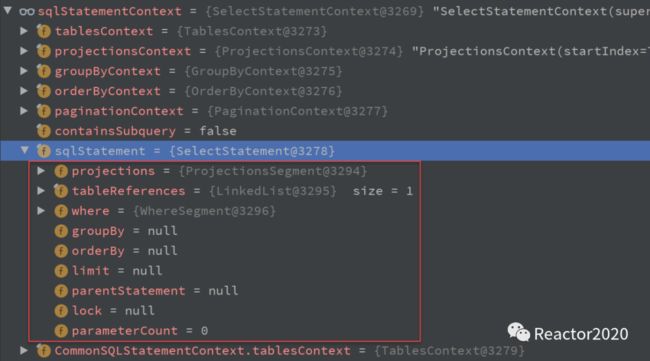
projections:列部分信息tableReferences:关联表信息where:where子句解析信息groupBy:group by子句解析信息orderBy:order by子句解析信息limit:limit子句解析信息ShardingConditions就是从SQL的where子句中提取中分片列的过滤信息,后续就是根据这个信息进行SQL路由,解析出的ShardingConditions如下图所示:注意:
ShardingConditions涉及到的解析where子句中限制列都只会处理分片列(库分片列或表分片列),因为主要解析出这些列用于后续的SQL路由,其它列对它来说没有意义会被忽略。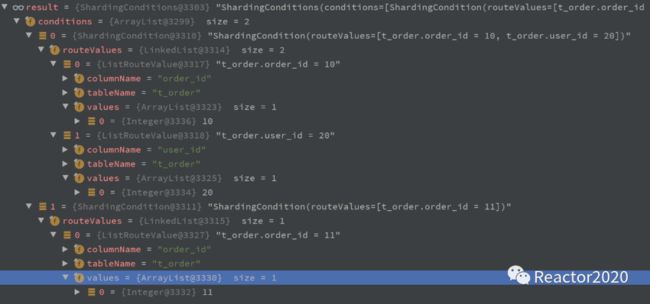
首先,这里会被解析出两个
ShardingCondition,上面分析过,比较好理解;每个
ShardingCondition里面会包含一组RouteValue,每个RouteValue包含那个表哪个列以及限制值三部分,直白说就是where子句中每个关于分片列的限制都会被解析成一个RouteValue对象,比如o.order_id = 10 and o.user_id=20,因为order_id和user_id都是分片列,这里会解析出两个RouteValueShardingConditions提取完成,这时SQL路由真正的主角ShardingRouteEngine登场,从名称就可以看出,它是SQL路由引擎,由它来处理SQL路由。ShardingRouteEngine不是单例模式,而是每个SQL都会对应一个实例。
路由引擎
下面我们就进入到ShardingRouteEngine#route,看看SQL路由引擎处理流程。这里进入的是ShardingComplexRoutingEngine#route方法,这个方法完成对整个SQL路由解析:
/**
* 1、用于对真个SQL语句进行SQL路由,每个SQL语句对应一个ShardingComplexRoutingEngine实例,它内部又会按照逻辑表进行拆分,
* 2、一个SQL语句可能对应多个逻辑表,比如管理查询join,每个逻辑表又会对应一个ShardingStandardRoutingEngine对象用于对逻辑表进行SQL路由,
* 3、每个逻辑表SQL路由结果是RouteResult,如果存在多张逻辑表,则使用ShardingCartesianRoutingEngine路由引擎进行笛卡尔积操作
* 4、经过上述流程就完成对整个SQL语句SQL路由处理
*
* @param shardingRule sharding rule
* @return
*/
@Override
public RouteResult route(final ShardingRule shardingRule) {
/**
* 每个逻辑表的SQL路由信息都会封装成一个RouteResult,RouteResult封装了SQL路由信息:originalDataNodes和routeUnits
*/
Collection result = new ArrayList<>(logicTables.size());
Collection bindingTableNames = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
for (String each : logicTables) {
Optional tableRule = shardingRule.findTableRule(each);
if (tableRule.isPresent()) {
if (!bindingTableNames.contains(each)) {
/**
* 每张逻辑表生成一个RouteResult
* RouteResult中包含RouteUnit类型集合,每个RouteUnit实际上代码一张具体的物理表,比如ds0.t_order0等
* 对每张逻辑表生成一个ShardingStandardRoutingEngine实例,然后调用route()方法进行该逻辑表SQL路由
*/
result.add(new ShardingStandardRoutingEngine(tableRule.get().getLogicTable(), sqlStatementContext, shardingConditions, properties).route(shardingRule));
}
shardingRule.findBindingTableRule(each).ifPresent(bindingTableRule -> bindingTableNames.addAll(
bindingTableRule.getTableRules().stream().map(TableRule::getLogicTable).collect(Collectors.toList())));
}
}
if (result.isEmpty()) {
throw new ShardingSphereException("Cannot find table rule and default data source with logic tables: '%s'", logicTables);
}
if (1 == result.size()) {//如果size=1,则表示没有没有多表关联查询
return result.iterator().next();
}
/**
* 这里表示存在多表关联查询,即对多个逻辑表的SQL路由进行笛卡尔积
*/
return new ShardingCartesianRoutingEngine(result).route(shardingRule);
}
大致流程:
一条
SQL可能存在多个逻辑表,比如上面关联查询join就涉及两张逻辑表:t_order和t_order_item;这个方法就对
SQL路由解析拆分成对SQL中每个逻辑表进行路由解析,每张逻辑表SQL路由解析结果封装成RouteResult;当对所有逻辑表进行
SQL路由解析完成后,然后就进行判断,如果只有一张表,很简单直接返回这张表SQL路由解析结果RouteResult即可,如果是多张表就使用笛卡尔积:new ShardingCartesianRoutingEngine(result).route(shardingRule)处理;注意:这里的笛卡尔积只会发生在同库下,不会出现跨库操作,Sharding-jdbc是不支持跨库操作的,在业务开发中千万注意跨库,不然会出现问题。
单表路由
上面我们分析了SQL路由会被拆分成对多张逻辑表进行SQL路由,然后使用笛卡尔积方式,下面我们继续跟踪下代码看下如何对单张逻辑表进行SQL路由。
对逻辑表SQL路由会创建ShardingStandardRoutingEngine实例,然后调用route()方法:
/**
* 用于对具体某张逻辑表进行SQL路由
* @param shardingRule sharding rule
* @return
*/
@Override
public RouteResult route(final ShardingRule shardingRule) {
//不支持多表INSERT、UPDATE、DELETE操作
if (isDMLForModify(sqlStatementContext) && 1 != ((TableAvailable) sqlStatementContext).getAllTables().size()) {
throw new ShardingSphereException("Cannot support Multiple-Table for '%s'.", sqlStatementContext.getSqlStatement());
}
/**
* getDataNodes()进行分库分表,返回的是DataNode集合,每个DataNode包含数据库名称和表名称,代码的就是数据库中具体的一张物理表
* generateRouteResult()将分库分表返回的DataNode集合包装成RouteResult
*/
return generateRouteResult(getDataNodes(shardingRule, shardingRule.getTableRule(logicTableName)));
}
这个方法最关键的是getDataNodes(shardingRule, shardingRule.getTableRule(logicTableName)),generateRouteResult()方法只是用来完成对SQL路由后的结果进行封装。
那下面我们就来看下getDataNodes()方法:
private Collection getDataNodes(final ShardingRule shardingRule, final TableRule tableRule) {
//hint方式分片
if (isRoutingByHint(shardingRule, tableRule)) {
return routeByHint(shardingRule, tableRule);
}
//ShardingConditions方式分片
if (isRoutingByShardingConditions(shardingRule, tableRule)) {
return routeByShardingConditions(shardingRule, tableRule);
}
//复合方式
return routeByMixedConditions(shardingRule, tableRule);
}
这里会判断分片方式:Hint、Condition或混合方式,这里我们跟踪下更常规的Condition方式routeByShardingConditions():
private Collection routeByShardingConditions(final ShardingRule shardingRule, final TableRule tableRule) {
/**
* 1、如果ShardingCondition空,route0(shardingRule, tableRule, Collections.emptyList(), Collections.emptyList())则获取到的是该表配置的全库全表路由
* 2、ShardingCondition存在时,则根据ShardingCondition信息进行SQL路由
*/
return shardingConditions.getConditions().isEmpty()
? route0(shardingRule, tableRule, Collections.emptyList(), Collections.emptyList()) : routeByShardingConditionsWithCondition(shardingRule, tableRule);
}
这里有个判断,如果shardingConditions集合为空,则说明SQL中where子句中没有关于分片列信息,这里返回的是全库全表路由,在实际开发中一定要注意这点可能会优化你SQL。
继续跟踪:
/**
* routeByShardingConditionsWithCondition():处理一张逻辑表根据shardingConditions信息解析出需要路由到哪些节点上,即获取DataNode集合,
* DataNode对应的就是一张具体的物理表,封装了库名称dataSourceName和表名称tableName
*
* 一个ShardingCondition相当于where中的一个条件,多个ShardingCondition之间是or关系,一个逻辑表解析SQL路由又可以拆分成对 一个逻辑表+ShardingCondition 进行SQL路由解析,调用的是route0()方法
* 将查询语句所有的shardingCondition集合都解析完成,就是这个逻辑表全部的路由数据
*
* @param shardingRule
* @param tableRule
* @return
*/
private Collection routeByShardingConditionsWithCondition(final ShardingRule shardingRule, final TableRule tableRule) {
Collection result = new LinkedList<>();
for (ShardingCondition each : shardingConditions.getConditions()) {
/**
* route0()是对一个 一个逻辑表+shardingCondition进行分库分表路由解析,生成DataNode集合,每个DataNode对应一张具体物理表,比如:{"dataSourceName":"ds0", "tableName":"t_order0"}
* 将SQL解析出的所有shardingCondition遍历一遍,就是这张逻辑表对应的SQL路由信息
*
* getShardingValuesFromShardingConditions():一个ShardingCondition中可能包含多个RouteValue,比如有库分片的RouteValue,也有表分片的RouteValue,这个方法就是获取具体相关的RouteValue
* 比如下面,第一个就是获取库分片相关的RouteValue,第二个就是获取表分片相关的RouteValue,将这些RouteValue传递给具体的分片算法,获取到SQL路由信息
*
*/
Collection dataNodes = route0(shardingRule, tableRule,
getShardingValuesFromShardingConditions(shardingRule, shardingRule.getDatabaseShardingStrategy(tableRule).getShardingColumns(), each),
getShardingValuesFromShardingConditions(shardingRule, shardingRule.getTableShardingStrategy(tableRule).getShardingColumns(), each));
result.addAll(dataNodes);
originalDataNodes.add(dataNodes);
}
return result;
}
大致说明:
这个方法用于对单张逻辑表进行
SQL路由,这里又会按照ShardingCondition维度对SQL路由进行拆分:单张逻辑表+单个ShardingCondition进行SQL路由解析;前面分析过
ShardingCondition,这是一个非常重要的概念:WHERE (o.order_id = 10 and o.user_id=20) or o.order_id = 11:前面分析过,这里会被解析成两个ShardingCondition,即:o.order_id = 10 and o.user_id=20和o.order_id = 11这两个;WHERE (o.order_id = 10 or o.order_id = 20) and o.user_id = 11:这个也会被解析成两个ShardingCondition,分别是o.order_id = 10 and o.user_id = 11和o.order_id = 20 and o.user_id= 11ShardingCondition内部是一组and条件,ShardingCondition间是or关系;理解了
ShardingCondition,就可以明白为啥可以根据ShardingCondition维度进行拆分,对单张逻辑表+单个ShardingCondition进行SQL路由解析,然后遍历所有的ShardingCondition,就可以对逻辑表完成全部路由解析。
下面继续跟踪下如何对单张逻辑表+单个ShardingCondition 进行SQL路由解析:
/**
* 分库分表
*
* routeDataSources()方法进行分库,返回分库列表
* routeTables()方法在分库的基础上进行分表,返回DataNode集合
* DataNode主要包含两个元素dataSourceName和tableName,每个DataNode代表具体数据库上的一张物理表
*
* route0():解析出一个ShardingCondition对应的DataNode集合,每个DataNode对应的是一张具体的物理表
* 1、先进行routeDataSources()方法进行分库,返回分库列表,比如返回:ds0、ds1
* 2、然后遍历每个分片库,调用routeTables()进行同库下表分片
* 3、最后返回DataNode集合,每个DataNode对应一张具体的物理表,比如:{"dataSourceName":"ds0", "tableName":"t_order0"}
*
* @param shardingRule
* @param tableRule
* @param databaseShardingValues
* @param tableShardingValues
* @return
*/
private Collection route0(final ShardingRule shardingRule, final TableRule tableRule, final List databaseShardingValues, final List tableShardingValues) {
//先使用库分片列相关的RouteValue进行库路由
Collection routedDataSources = routeDataSources(shardingRule, tableRule, databaseShardingValues);
Collection result = new LinkedList<>();
for (String each : routedDataSources) {//遍历库路由结果集
//然后对每个路由库,进行具体的表路由
result.addAll(routeTables(shardingRule, tableRule, each, tableShardingValues));
}
return result;
}
大致说明:
先会调用
routeDataSources()进行库上路由;然后在每个路由库上调用
routeTables()进行库下标路由;routeDataSources()和routeTables()路由逻辑都是借助于分片策略ShardingStrategy实现,ShardingStrategy又通过分片算法ShardingAlgorithm实现用户自定义的一些扩展,具体分片策略这里就不继续展开。
总结
自此,Sharding-jdbc中如何完成SQL路由的流程基本都分析完成,SQL路由流程是非常关键的一步,决定了一个SQL到底会在哪些库、哪些表上进行执行,只有理解了SQL路由,业务开发中进行数据库设计、SQL设计等才能很好的规避一些问题,以及SQL如何更加高效执行等。
上面从源码角度分析了SQL路由核心流程,下面通过一个案例总结下,如下图:
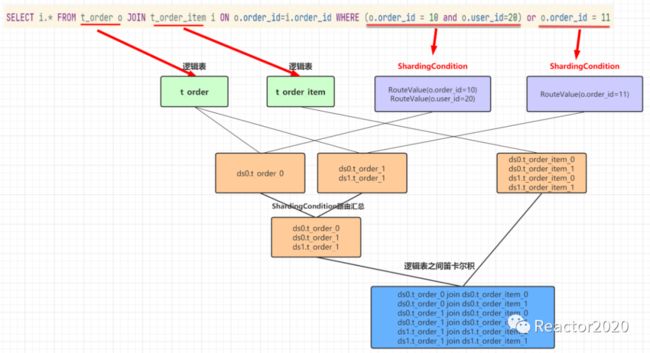
大致说明:
从
SQl的where子句中提取出所有的ShardingCondition,这里提取出两个如上图;对
SQL路由解析从逻辑表和ShardingCondition两个维度进行拆分;t_order和第一个ShardingCondition进行SQL路由解析结果是ds0_t_order_0;t_order和第二个ShardingCondition进行SQL路由解析结果是ds0_t_order_1和ds1_t_order_1;汇总逻辑表
t_order路由结果:ds0_t_order_0、ds0_t_order_1和ds1_t_order_1这三个;同理,接下里对逻辑表
t_order_item进行路由解析,注意:虽然有两个ShardingCondition,都是o.开头,即都是关于逻辑表t_order的,t_order_item则不存在ShardingCondition信息,所以这里解析出的路由结果是:全库全表;最后,对逻辑表
t_order和t_order_item进行笛卡尔积汇总,这里笛卡尔积不会出现跨库,这个千万注意,得出整条SQL最终的路由结果集。

长按二维码识别关注