本单元要求是根据JML规格完善代码,初看是一个简单的代码照搬实现的东西,但最后才发现由于CPU时间的限制,还考察了大量优化策略及数据结构中关于图的知识,是一次非常注重细节构思的一单元,我借此机会学习并巩固了好几个图的算法,并了解了java各类容器的查插删改的效率。
一、JML理论基础
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言,它相当于一种接口,正确的JML可以给实现人员清楚的代码要求,并且针对已有代码书写JML也可以提高代码的可维护性、可读性。经我使用看来,它有如下几种关键要素组成:
-
位于类一开始的
//@annotation的属性定义,它规定了类必含的属性(当然也可以由其它形式所展现),在之后的方法规格中会用到这些定义 -
变式
invariant,要求在所有可见状态(凡是会修改成员变量(包括静态成员变量和非静态成员变量)的方法执行期间,对象的状态都不是可见状态)下都必须满足的特性 -
状态变化约束
constraint,对前序可见状态和当前可见状态的关系进行约束 -
pure关键词,表示某些纯粹访问性的方法,即不会对对象的状态进行任何改变,也不需要提供输入参数,这样的方法无需描述前置条件,也不会有任何副作用,且执行一定会正常结束 -
前置条件(pre-condition),用
requires关键词表示,定义调用者调用方法前必须满足的语句 -
后置条件(post-condition),用
ensures关键词来表示,定义调用者调用方法后必须满足的语句 -
副作用约束子句,使用关键词
assignable或者modifiable,表示调用方法后可以改变的变量 -
异常处理行为
exceptional_behavior,用signals (Exception e) expr表示满足expr条件即抛出Exception异常,用signals only Exception表示满足前置条件即抛出Exception异常
其中,在规格表示时,大多数语句含义与代码类似,只需注意一下几个关键词的意含义:
-
\nothing,指空集;everything,指全集,通常用在assinable语句 -
\result,表方法示返回结果 -
\old(expr)表达式,表示一个表达式expr在相应方法执行前的取值 -
推理操作符:
expr1==>expr2,即离散中的→ -
\forall表达式:全称量词修饰的表达式 -
\exists表达式:存在量词修饰的表达式 -
\sum表达式:返回给定范围内的表达式的和
二、JML应用工具链
-
OpenJML:类似于对代码的检查,可以对规格进行语法的检查
-
JMLUnitNG/JMLUnit: 针对类自动生成测试样例并进行测试
-
JMLdoc : 类似 Javadoc,可以快速生成 JML 文档的相关文件
三、SMT Solver
下载了openjml,想要运行结果出现了一堆警告和error,类似于下面这种问题,\result都会被报错,但自己写的Demo里只有很简单的一个add方法,完全摸不着头脑,而且openjml也不能检测forall、exsit等语句,只能放弃
public class Demo {
//@ ensures \result = a + b
int add(int a, int b) {
return a + b;
}
}

四、JMLUnitNG
经过一些奇奇怪怪的操作,我终于配置成功了jmluintng
我先对Person.java进行了测试,主要是先补齐new一个新对象时<>里的变量类型,并加上包名,其它内容并没有改动,可以看出它产生的测试用例都是比较边缘的情况,如0、null、MAX_VALUE等,最后只贴出来出现fail的部分,集中在isLinked函数,原因是输入为null的情况,这应该是不会在使用中出现的一种情况
之后我又进一步对Group.java进行了测试,结果如下

最后失败的仍是null的情况。。。
我感觉到,这其实是一种很好地检验方法正确性工具,尤其体现在它对边缘情况进行测试的方面,但可能不是很适合比较复杂的情况(如我们的图算法)
五、架构设计
先放UML图
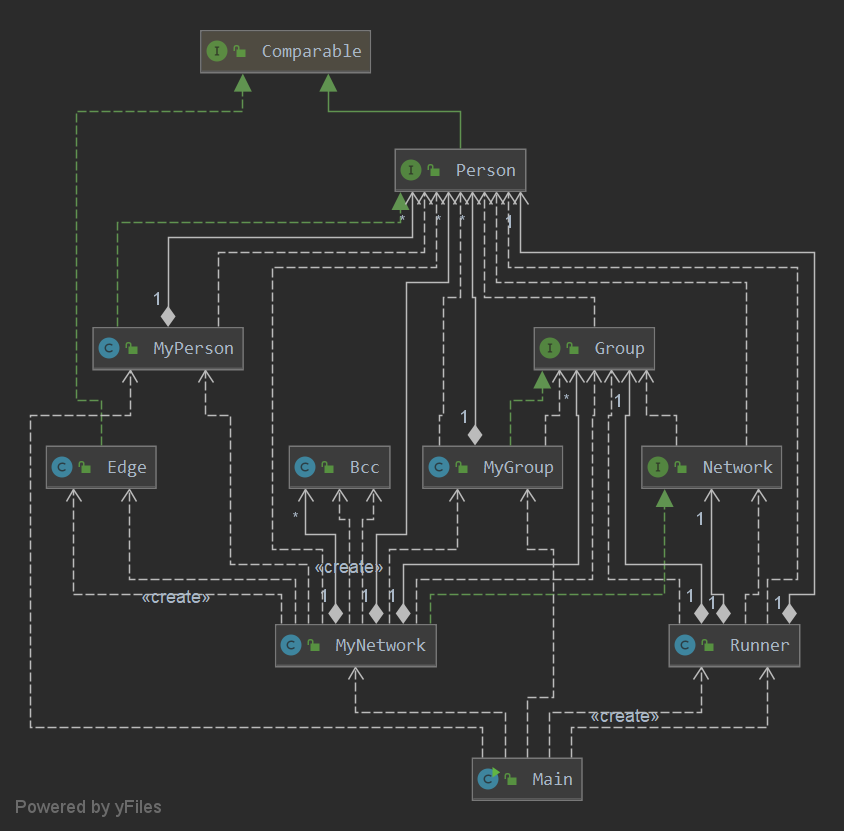
看起来有点点复杂,但我在原有架构的基础上,其实只增加了两个类Edge和Bcc,一个代表图中的边,一个代表一个双连通块,通过增加这两个类,可以进行更好的双连通分量与最短路径的查询。至于优化的问题,由于都是在TLE之后才意识到需要进行优化,所以放在下部分讲
六、bug及其修复
这次作业的bug主要出现在算法的问题上,由于一开始都是机械地按照规格重现代码,所以导致很多点TLE了,最后bug修复完的算法如下:
-
采用hashmap进行存储查找,arraylist太慢,并对hashmap进行适当的初始化容量操作(最后的TLE就死在这上面)
-
对getValueSum和getRelationSum使用缓存机制,提前设置变量,在addRelation和addToGroup时进行即使修改
-
对blockSum进行缓存,并对每个person进行block的标号,在addPerson时使blockSum++,在addRelation时合并block,并改变blockSum(这里在优化过程中出现了一个bug,是因为没有区分好block的标号及blockSum,使得后加进来的人也会被打上之前block的标号)
-
通过每个id的block号,可直接判断isCircle
-
对queryMinPath方法使用堆优化的Dijikstra,对于堆优化,采用了java有序队列PriorityQueue来存储,使Edge实现了Comparable的接口,并且每次添加的时候不用进行是否已经访问过的查询操作,因为他永远都是poll出最小值。这里也出过一个小bug,是由于我将每个id初始的路径值设为了1001(value[0,1000]),但忽视了value是一个累加的过程。。最后改为Integer.MAX_VALUE,也是由于自己测试不充分的缘故,这其实只需要将每条边的value值设大一点就可以了
-
由于会有大量连续测最短路径的操作,我每查询一次就将查询结果以
-
queryStrongLinked的Tarjan算法,这个就不多说了,因为大家应该都用了
最后MyNetWork的各个方法复杂度分析如下
| MyNetwork.addGroup(Group) | 2.0 | 1.0 | 2.0 |
|---|---|---|---|
| MyNetwork.addPerson(Person) | 2.0 | 1.0 | 2.0 |
| MyNetwork.addRelation(int,int,int) | 4.0 | 6.0 | 9.0 |
| MyNetwork.addtoGroup(int,int) | 4.0 | 2.0 | 5.0 |
| MyNetwork.borrowFrom(int,int,int) | 3.0 | 2.0 | 4.0 |
| MyNetwork.compareAge(int,int) | 2.0 | 2.0 | 3.0 |
| MyNetwork.compareName(int,int) | 2.0 | 2.0 | 3.0 |
| MyNetwork.contains(int) | 1.0 | 1.0 | 1.0 |
| MyNetwork.delFromGroup(int,int) | 4.0 | 1.0 | 4.0 |
| MyNetwork.getGroup(int) | 1.0 | 1.0 | 1.0 |
| MyNetwork.getPerson(int) | 2.0 | 1.0 | 2.0 |
| MyNetwork.isCircle(int,int) | 2.0 | 2.0 | 3.0 |
| MyNetwork.MyNetwork() | 1.0 | 1.0 | 1.0 |
| MyNetwork.queryAcquaintanceSum(int) | 2.0 | 1.0 | 2.0 |
| MyNetwork.queryAgeSum(int,int) | 1.0 | 3.0 | 4.0 |
| MyNetwork.queryBlockSum() | 1.0 | 1.0 | 1.0 |
| MyNetwork.queryConflict(int,int) | 2.0 | 2.0 | 3.0 |
| MyNetwork.queryGroupAgeMean(int) | 2.0 | 1.0 | 2.0 |
| MyNetwork.queryGroupAgeVar(int) | 2.0 | 1.0 | 2.0 |
| MyNetwork.queryGroupConflictSum(int) | 2.0 | 1.0 | 2.0 |
| MyNetwork.queryGroupPeopleSum(int) | 2.0 | 1.0 | 2.0 |
| MyNetwork.queryGroupRelationSum(int) | 2.0 | 1.0 | 2.0 |
| MyNetwork.queryGroupSum() | 1.0 | 1.0 | 1.0 |
| MyNetwork.queryGroupValueSum(int) | 2.0 | 1.0 | 2.0 |
| MyNetwork.queryMinPath(int,int) | 10.0 | 9.0 | 14.0 |
| MyNetwork.queryMoney(int) | 2.0 | 1.0 | 2.0 |
| MyNetwork.queryNameRank(int) | 2.0 | 2.0 | 4.0 |
| MyNetwork.queryPeopleSum() | 1.0 | 1.0 | 1.0 |
| MyNetwork.queryStrongLinked(int,int) | 5.0 | 7.0 | 10.0 |
| MyNetwork.queryValue(int,int) | 3.0 | 2.0 | 4.0 |
| MyNetwork.renew(int,int) | 2.0 | 7.0 | 7.0 |
| MyNetwork.tarjan(int,int) | 6.0 | 7.0 | 8.0 |
也可以看出来是qmp和qsl方法复杂度比较高,也是只有这两个方法含有图的反复查询操作
七、心得体会
坦白地讲,在做第一次作业时,我用了oo有史以来的最短时间,而且个人感觉没什么需要测试的地方,不由感叹oo作业变简单了,在进行互测时,也是第一次认真看完了所有人的代码,并找出了他们的漏洞,感觉第一次作业还是比较注重规格的。
第二次作业,虽然形式与第一次相同,但突然讲究的多了起来,也开始对时间和算法有要求了,但由于当周的os作业太难搞,我还是放松了对oo的优化及测试,导致我出了一个很大的bug没有进互测!!!真的没有想到中测突然变得如此简单。。我是大大的失策了,再加上双重循环的遍历,挂掉了所有强测。
第三次作业,我吸收了前两次的教训,自己对算法和测试都比较认真地规划了,而且我也能感受到第三次作业十分看重算法,难度甚至大过了数据结构,这次的结果还算比较正常,也由于优化程度不够导致TLE了一些点,而且互测的大佬们也查出了我没注意的很小的点,经过最艰难的一次bug修复,我终于完成了这一单元的代码部分。
真的感触颇多,从这一次作业,我充分认识到了JML规格的实现不是纯”实现”的问题,要进行自己的优化, 使程序效率达到最好,想想这其实是合理的,规格的书写者只负责想好方法的效果,保证规格正确性即可,不可能连我们怎么实现都考虑到了。最后,再赞一句助教这次强测的点简直太妙了,就卡那一点点时间,我是挣扎着才由2.0XX秒到了1.9X秒,真是一次颇为“愉悦”的经历。。