ICCV2017_S3FD:Single Shot Scale-invariant Face Detector
论文想解决的问题:人脸目标太小的话,anchor-based detector性能急剧下降;
四个spotlight:
1 类似SSD,多个feature map预测不同尺度的人脸,但没有像FPN一样,上下层feature map连接;提出了有效感受野(effective receptive field)、equal proportion interval principle概念;
2 通过anchor尺度补偿匹配策略(small faces by a scale compensation anchor matching strategy)提升了对小区域人脸的召回率;作者认为anchor的scale是离散的,通过该尺度补偿匹配策略,可以提升对小人脸、处于离散的anchor scale中间尺度人脸的召回率;
3 使用max-out background label降低了小人脸的false positive rate;
该模块仅限于lowest detection layer,也即con3_3;
4 AFW, PASCAL face, FDDB、WIDER FACE四个数据集都干到了第一,36FPS/titan x,实时;
作者认为的最重要的一个spotlight:
Proposing a scale-equitable face detection framework with a wide range of anchor-associated layers and a series of reasonable anchor scales so as to handle different scales of faces well.
中文就是:类似SSD,在若干feature map上使用尺度分布均匀的anchor,同时设计合理的anchor scale,确保能处理不能尺度的人脸;
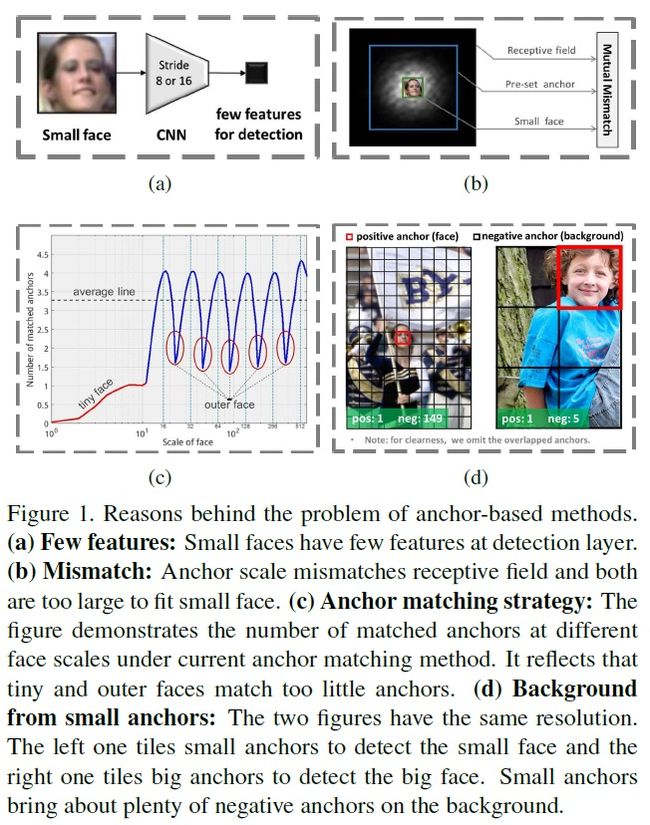
四个问题:
1 人脸太小,在高层feature map的特征就太少;
2 真实人脸区域、感受野、anchor大小不匹配;
3 离散的默认anchor尺度,对真实人脸的匹配度不够,造成了小人脸和非尺度范围内的人脸匹配度不高;
4 小anchor会在背景上引来过多的非人脸干扰;
介绍了下基于anchor的检测器:
Anchor-based object detection methods detect objects by classifying and regressing a series of pre-set anchors, which are generated by regularly tiling a collection of boxes with different scales and aspect ratios on the image. The anchor-associated layers are convolved to classify and align the corresponding anchors. 弊端:特征越小,检测性能越差.
设计合适的anchor stride和size:
stride
:We tile anchors on a wide range of layers whose
stride size vary from 4 to 128 pixels
, which guarantees that various scales of faces have enough features for detection.
size
:we design anchors with
scales from 16 to 512 pixels over different layers
according to the effective receptive field and a new equal-proportion interval principle, which ensures that anchors at different layers match their corresponding effective receptive field and different scales of anchors evenly distribute on the image.
anchor匹配策略:
propose a scale compensation anchor matching strategy with two stages. The first stage follows current anchor matching method but adjusts a more reasonable threshold. The second stage ensures that every scale of faces match enough anchors through scale compensation
受到FRCNN和SSD的启发:
In this paper, inspired by the
RPN in Faster RCNN
and the
multi-scale mechanism in SSD
, we develop a state-of the-art face detector with real-time speed.
流程图:
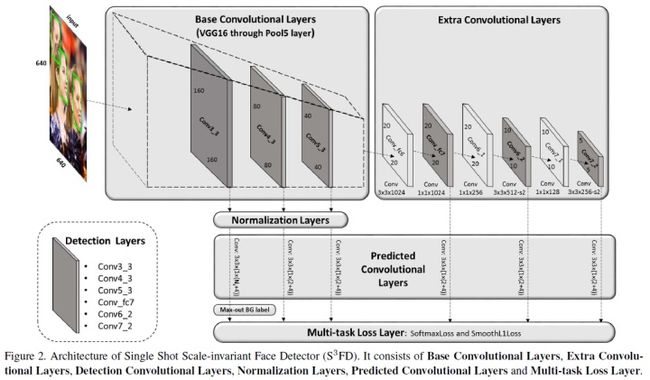
几点可以注意:
1 检测在多层进行,类似SSD;
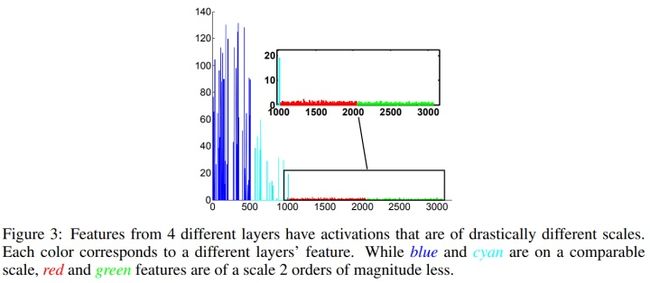
2 有一个Normalization layer,作用:参照ICLR2016的parsenet,作者认为conv3-3、conv4-3、conv5-3的feature map激活层尺度不同,做个each channel feature map的element-wise L2正则化,有利于更好的训练和收敛,注:之后还有个re-scale的操作,类似BN的alpha、gamma参数;
3 predicted conv-layer输出是1*(2+4),分别表示为:4是对应于anchor的坐标偏移;2对应分类,face/non-face;
4 conv3_3输出为1*(Ns + 4):4同样对应于anchor的坐标偏移,Ns=Nm+1,1对应face,Nm对应于conv3-3的maxout bg label,主要用于conv3-3上去除小目标的误检;
5 fc6、fc7在原始vgg16中是全连接层,在此被调整为conv layer,在conv6-2、conv7-2实现stride-2的降采样;
第三节介绍四个方面:
3.1 Scale equitable framework
还是提到了这点:develop a network architecture with a wide range of anchor-associated layers, whose stride size
gradually double
from 4 to 128 pixels,stride size逐倍增长;ensures that different scales of faces have adequate features for detection at corresponding anchor associated layers.可以确保不用尺度的人脸在对应的feature map上有足够的特征用于检测;
After determining the location of anchors,we design the scales of anchors from 16 to 512 pixels based on the effective receptive field and our equal proportion interval principle. 基于有效感受野和均匀分布插值策略设计anchor的尺度;
The former(有效感受野) guarantees that each scale of anchors matches the corresponding effective receptive field well, and the latter(均匀分布插值策略) makes different scales of anchors have the same density on the image.
正则化层:参照ICLR2016 parsenet----一个用于语义分割的网络
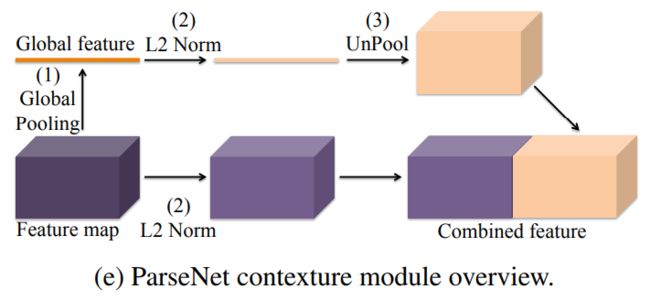
两个创新点:
1 global pooling就是global avarege pooling;unpool将1*1*C的feature恢复至W*H*C的feature map;恢复方式挺简单,就是1*1的特征重复复制W*H份;
2 L2正则化,动机很简单,fig3中说了,不同层级的feature map(如conv3-3、conv4-3、conv5-3)激活值的尺度不一样,可能有若干个数量级的差异,如果如fig e一样简单的concate,那么低激活值的feature map在concated向量中话语权太弱了,所以先要做个L2正则化了再说;
正则化方式比较简单,W*H*C中的每一个channel,W*H内所有元素,平方和开根号得到Lsum,然后每个元素除以Lsum即可;如下图公式:

后续还有个操作类似BN,为了避免过于正则化,每个channel再学习一个lamda参数,因此一共要学习C个参数;和BN的alpha、gamma参数类似,可以在训练中学习;
pred conv layer:在detection layer后接p×3×3×q conv即可;p对应input channel,q的值为(2 + 4) or (Ns + 4),4对应于anchor的坐标偏移,2对应face/non-face、Ns对应于conv3-3的maxout bg label;
为anchor设置合适的尺寸
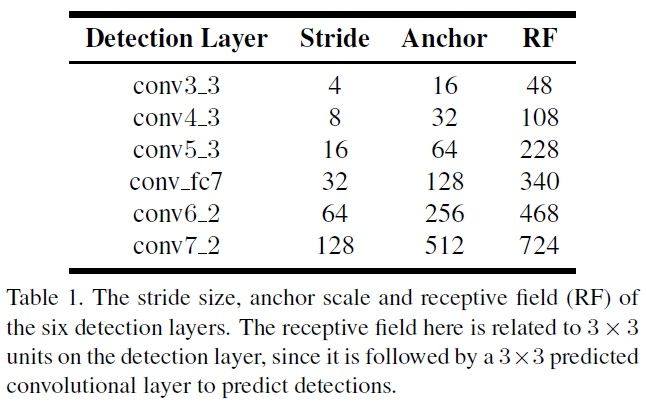
以上表格三个特点:
1 anchor的长宽比1:1,因为人脸一般都是接近正方形;
2 each layer stride 和 RF固定,anchor size是RF的1/4;
3
SSD的each layer feature map上设置的anchor scale只有唯一一个尺度
!!!
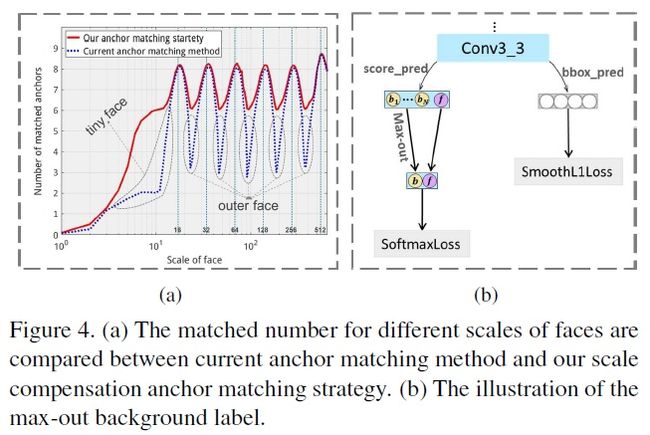
theoretical receptive field(TRF):理论感受野,对于feature map上某个点,根据conv的winsize和stride计算出来,一般比较大,但最终只有以TRF中心的高斯区域内输入点有效,且贡献值按二维高斯分布降低;下图a黑色矩形框;
effective receptive field(ERF):只有一部分(如高斯分布区域)对feature map上某个点的值有贡献;下图a白色圆形区域;
基于以上,作为提出了一个观点:the anchor should be significantly smaller than theoretical receptive field in order to match the effective receptive field。也即,anchor的size应该匹配ERF,而非TRF;
Equal-proportion interval principle: The stride size of a detection layer determines the interval of its anchor on the input image. feature map上的stride size决定了feature map上的anchor采样的间隔;、通过在feature map上将stride设置为对应anchor size的1/4,which guarantees that different scales of anchor have the same density on the image, so that various scales face can approximately match the same number of anchors.达到的好处就是:在不同feature map上,不同scale的anchor有同样的采样密度,不同尺度的人脸可以近似匹配相同数量的anchors.

3.2. Scale compensation anchor matching strategy基于尺度补偿的anchor匹配策略
当前的anchor匹配策略,跟fast rcnn类似,firstly matches each face to the anchors with the best jaccard overlap and then matches anchors to any face with jaccard overlap higher than a threshold(比如0.5)
以上存在一个问题:anchor scales are discrete while face scales are continuous,anchor尺度离散,但人脸尺度连续;导致的问题就是:
1) the average number of matched anchors is about 3 which is not enough to recall faces with high scores; 每个gt face bbox只匹配3个anchor,太少了;
2) the number of matched anchors is highly related to the anchor scales. The faces away from anchor scales tend to be ignored, leading to their low recall rate. 匹配的anchor需要高度适配gt face bbox的大小,否则离散的anchor很容易漏检部分不在anchor size区域范围内的人脸;
提出的基于尺度补偿的anchor匹配策略:
step1:使用常规的fast rcnn的anchor与gt box的jaccard overlap匹配策略,但降低thres至0.35,这样可以提升每个gt bbox匹配的anchor数目N;
step2:将anchor与gt bbox的jaccard overlap阈值降低至0.1,降序选取top N matched anchor作为与该gt bbox match的anchor;N为step1中的N;注:0.35~0.1 thres的降序排序;
3.3 Maxout background label
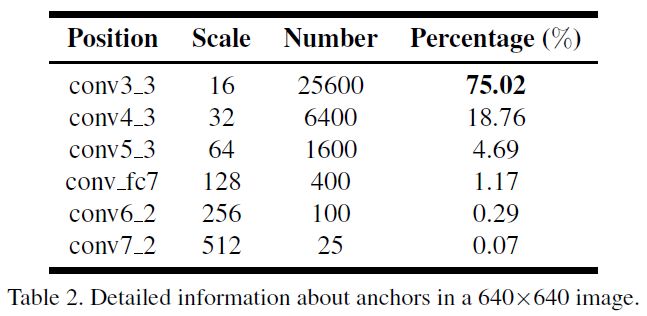
当前人脸检测存在一个矛盾:conv3-3可以检测小目标,但为检测出海量的小目标,必须保证anchor的尺度足够小(we have to densely tile plenty of small anchors on the image to detect small faces,tile这个单词用的很形象,就像瓦屋房顶,密密麻麻地密集选取大量的小size anchor)。但矛盾之处在于:These smallest anchors contribute most to the false positive faces. 也即小anchor容易带来大量的fp;也即如下,conv3-3上的anchor数目占比最大,但也带来了很多fp faces;
We apply the
max-out background label for the conv3-3 detection layer
. For each of the smallest anchors, we predict
Nm scores for background label and then choose the highest as its final score. 对于bg label,选择最大的一个输出作为bg output score,所以Ns + 1中,Ns指的是bg non-face的label,1指的是face的label;
3.4 training
training dataset:wider face的12880张训练图像集,颜色扭曲,水平翻转+random crop
random crop:因为wider face人脸比较小,所以选用了一个zoom操作;对于一张图,crop出5张图:1张原始scale图,剩下4张按照图像短边scale ratio属于[0.3, 1.0],crop出4个patch;
loss function:损失函数的定义完全与fast rcnn一致:

OHEM:anchor匹配之后,训练时发现大部门未被匹配的anchor都是负样本,这样会导致正负样本不均衡;所以使用ohem方法,将损失值降序排序,确保正负样本比例1:3;使用ohem之后,设置bg label中的Nm = 3, loss function中的lamda为4;
实验:
RPN-face:和frcnn一致,但anchor长宽比设置为1:1,conv5上尺度设置多一点:16, 32, 64,128, 256, 512;这样相当于一共有1*6个anchor,与frcnn的3*3共9个anchor略微不同;RPN-face has the same choice of anchors as ours but only tiles on the last convolutional layer of VGG16。弊端:Not only its stride size (16 pixels) is too large for small faces, but also different scales of anchors have the same receptive field.----因为frcnn仅仅在一层feature map上做预测,所以设置了多个scale的anchor;
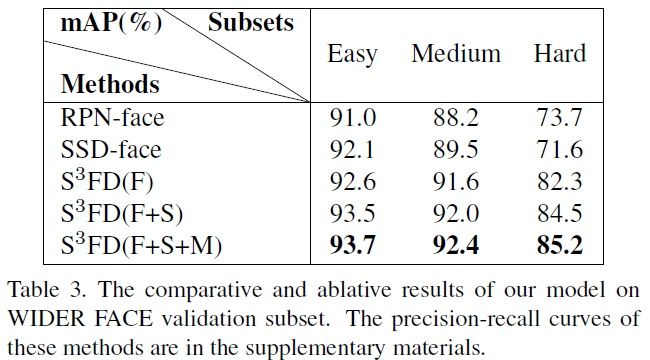
消融实验:
F:scale-equitable framework
S:scale compensation anchor matching strategy
M:max-out background label
总结:
Max-out background label is
promising
:It deals with the massive small negative anchors (i.e., background) from the conv3-3 detection layer which is designed to detect small faces.从table 3中也可以得知,图越难,map越高,说明Maxout bg label对比较困难的图,检测效果很好;
实验:
AFW dataset
. It contains 205 images with 473 labeled faces.
PASCAL face dataset
. It has 1, 335 labeled faces in 851 images with large face appearance and pose variations.It is collected from PASCAL person layout test subset.
FDDB dataset
. It contains 5, 171 faces in 2, 845 images.
1) FDDB adopts the bounding ellipse while our S3FD outputs rectangle bounding box. train an elliptical regressor to transform our predicted bounding boxes to bounding ellipses.
2) FDDB has lots of unlabelled faces, which results in many false positive faces with high scores.
WIDER FACE dataset
. It has 32, 203 images and labels 393, 703 faces with a high degree of variability in scale, pose and occlusion.
The images and annotations of training and validation set are available online, while the annotations of testing set are not released and the results are sent to the database server for receiving the precision-recall curves.
inference time:
提速方案:we first filter out most boxes by a confidence threshold of 0.05 and keep the top
400 boxes before applying NMS, then we perform NMS with jaccard overlap of 0.3 and keep the top 200 boxes. 80%的耗时在vgg16主干网,如果使用更轻量级的网络backbone,可能提速更明显。

总结:为了解决人脸目标过小时,检测性能急剧下降的问题。三个亮点:
1 scale-equitable framework
2 scale compensation anchor matching strategy
3 max-out background label
代码也有:
sfzhang15/SFD
demo可以跑,训练给出了方案,需要修改部分代码;
论文参考
1 ICCV2017_S3FD:Single Shot Scale-invariant Face Detector