【个人项目】基于scrapy-redis的股票分布式爬虫实现及其股票预测算法研究
前言
都说做计算机的,项目实践是最能带给人成长的。之前学习了很多的大数据和AI的知识,但是从来没有自己做过一个既包含大数据又包含AI的项目。后来就决定做了个大数据+AI的分布式爬虫系统。下面笔者会讲述整个项目的架构,以及所用到技术点的些许介绍。
项目介绍
这个项目是笔者的个人项目,是基于scrapy-redis框架的股票分布式爬虫框架实现。scrapy是个爬虫框架,但只允许单机的,scrapy-redis是它的补充,能支持分布式的爬虫爬取。完成爬虫框架后,我想玩点AI的东西,就设计了两个算法,预测股票每日的开盘价是多少。
项目包含两个部分:
1. 基于大数据知识的分布式爬虫系统
2.基于人工智能的预测系统(为什么是预测呢?因为我爬取的数据是股票数据)项目的难度适中,有一定的算法实现(基于数据自己设计的),但总体要求不高。项目主要的特点是,用到的技术点很多,就是那种“这个用到那个用到,但就是不需要精通”,比如用到了Redis,Hadoop,Zookeeper,Hive等等,所以很适合大数据或AI专业的学生练手,因为可以学到很多模块。但对于有经验的读者来说,有兴趣的话可以研究下预测股票的算法,或者接着往下做。我实现了两种算法,但完成度都不高。
项目用到技术
技术点比较多,包含了大数据的部分框架和部分AI知识。
爬虫:Python,Scrapy
大数据:Zookeeper,Hadoop,Hive,Redis
AI: 反向传播神经网络,HTM神经网络,Kmeans算法,部分数学。
项目github链接
https://github.com/Jiede1/spider-based-on-scrapy_redis-for-share-and-share-prediction-algorithm-search
项目架构
下面是项目的框架图,包含3个部分。

分布式爬虫框架部分:
由三台主机组成,这三台主机组成一个Hadoop集群,并且集群的每一台都安装了scrapy,scrapy-redis组件,这些都是爬虫的必要组件(除此之外,Master需要安装Redis,所有的Slave都会访问这台Redis)。scrapy负责整个爬虫的框架,Redis负责存储爬虫产生的数据,scrapy-redis的存在使得三台机器可以基于Redis实现数据交互,也即爬虫分布式的体现。
在集群的Master上,放置了第一部分的爬虫代码,负责基于scrapy的框架,由输入的一个初始URL开始,通过爬虫规则,得到爬虫的目标URL,这里称之为download_url,并将之存到Redis。
在Slave1和Slave2上面,放置了爬虫的第二部分代码,负责从Redis中取得download_url,然后下载数据并储存到HDFS
这里要介绍下scrapy框架。scrapy是个出名的python爬虫框架,其实现的爬虫代码由几部分组成:爬虫初始URL start_urls,爬虫处理逻辑parse函数,爬虫处理数据逻辑pipelines函数,以及爬虫的各种各样中间件,和扩展组成。后两者的存在都是赋予爬虫更多的功能,更高的稳定性。
笔者的start_urls是http://quote.eastmoney.com/stocklist.html#sh,东方财富网的页面。
存储部分:
数据的存储笔者选择HDFS,主要原因有二:
1. HDFS是分布式的。
2. 基于HDFS存储,在后续的机器学习算法开发,或许会有更多的API支持,比如Spark支持读取HDFS为RDD。
但实际上,在我完成代码并测试的时候。发现利用HDFS作为储存引擎并不好,因为数据存储的功能是实现在爬虫框架里的,也就是说爬虫代码在运行的时候,会多次且频繁对HDFS进行读写。这设计到大量的内存交互和消耗,HDFS对频繁的读写是非常不友好的,会严重拖低爬虫速度。有多慢呢?就我的数据量来说,如果是保存到本地,也就几分钟跑完了,但如果是储存到HDFS里,要跑好几个小时。那酸爽!
所以,如果有读者以后也要实现分布式爬虫的框架,不要利用HDFS作为储存引擎,而是使用一些分布式数据库,比如Sequoiadb(国产数据库,性能比mongodb好),monagodb(比前者出名,更多api支持)。
算法预测部分
笔者爬取的数据是东方财富网的股票数据(并且是上海股票和深圳股票),数据大概长这样

数据在HDFS存储也是长这样,弄清楚了数据的结构,接下来的就是设计相应的算法来预测了。笔者预测的是“开盘价”这一字段。
笔者设计了两个算法:
1. BP神经网络+MSD相似度
2. HTM算法+kmeans+MSD相似度
首先笔者先说明,这两个算法的效果都略显尴尬,但算法2确实还算不错,但我只是随便选了一两条股票来预测然后plot出来看效果,没有更多的实验跟进;算法1简直就是灾难,命中率几乎为0,但算法1我当时主要是想瞎搞一下,读者看看笔者的思路就可,或许对你们有其他的启发呢,也说不定。
首先介绍下MSD相似度:
传统的相似度计算,比如余弦,曼哈顿等等,对于股票数据来说,不是特别适用。判定两只股票是否类似,不止要看他们数值向量之间的差距,还需要看他们“形态”之间的差距。所以笔者查看了一些论文,然后发现了MSD相似度—-这种相似度既考虑了两个序列的数值上的差异,也考虑了他们之间的“形态”上的差距。比如,从视觉上看,是否两个序列的走势是一样的。
MSD的计算方式:

其中, Li,Lj L i , L j 是两条序列,长度都为n。
其实上面的公式等同于:
![]()
DEuclid D E u c l i d 是欧式距离,ASD是 Li,Lj L i , L j 各维差值之和的绝对值,SAD是 Li,Lj L i , L j 之间的曼哈顿距离。
MSD>=0,可大于1。越靠近0,两条序列越相似。
有关MSD相似度,具体可以看链接:
https://wenku.baidu.com/view/58dfefbc2b160b4e777fcf77.html
还要介绍下HTM算法
HTM算法也是一种神经网络算法,但并没有BP神经网络或深度学习这样出名。它的作用主要是用于时间序列的预测,以及异常检测,并且表现良好。它最大的特色是:能够记忆曾见过的模式,可以一边学习,一边预测,并且能够自动纠错,预测错了能继续学习,改正错误。
HTM算法有个别名,叫Nupic算法。其实Nupic是个HTM算法的大集成,目前开源在Github上。
下面是Nupic的结构:
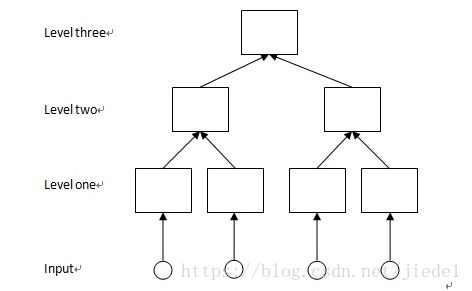
Input的每个神经元对应着一个数值,整个Input就是一个向量。

这一张图是Nupic的单层结构,每一层的结构都如此。具体原理我就不介绍了,有兴趣的读者可以去看我的另外一篇博客,里面讲述了Nupic算法的原理。
好了,接下来会讲述每一部分的技术要点。
项目分块讲解
分布式爬虫框架
对于爬虫系统,最开始的工作就是设计爬取系统,爬取系统包括了爬虫spider,中间件,还有字段处理的部分。每一部分都需要单独处理。

上图是分布式爬虫系统的框架图,主要包含三个方面的工作:爬虫,中间件的编写,字段处理。
爬虫
爬虫的工作包含设计爬取策略,这需要根据自己所要爬的数据来决定,比如,笔者爬取的是股票数据,那就应该根据股票网站的规则来爬取。下图是笔者的爬虫逻辑

爬虫开始时,首先往Master端的爬虫代码扔进start_url —-http://quote.eastmoney.com/stocklist.html,然后得到目标页总数以及所有的股票代码,然后基于爬虫逻辑,通过正则表达式组合成最终的download_url,存进Redis。
值得注意的是,在scrapy框架中,原本start_url是在代码中加入的,但利用了scrapy-redis后,start_url放在Redis中就行,scrapy框架会自动到Redis读取start_url
简单介绍下scrapy-redis
scrapy-redis是scrapy框架的一个改善。以前scrapy框架中,存放带爬取url的数据结构python自带的数据结构collection.deque,但这玩意做不到分布式读取,所以开发者就将之换成了从Redis读取,并且改写了scrapy框架中的Scheduler模块,使得框架真正能够实现分布式运作了。
具体知识可学习如下博客:
https://m.aliyun.com/jiaocheng/524664.html
https://segmentfault.com/a/1190000014333162?utm_source=channel-hottest
https://blog.csdn.net/hjhmpl123/article/details/53292602
笔者的爬虫逻辑可以基于Github上Master端代码和Slave端代码来看,爬虫逻辑放在这两个文件夹的Spider目录下。
关于去重
去重的任务是:对于需要进行储存到Redis的URL,进行去重检测,这样是为了提升效率。其实scrapy框架本身就会对URL进行去重检测,但笔者还是在代码里实现了一个去重逻辑,其实跟scrapy的去重原理一样。

关于异常处理和速度控制
笔者个人的异常处理非常简单粗暴。先贴出一段异常处理的代码。

笔者是在将近所有的处理逻辑的外面,就给它套一个try…except模块,有异常就报错,而不管异常是什么。
其实最好的异常处理是,在每个逻辑前面,都加一个异常处理模块,然后打印对应的错误信息(不过这种情况比较适合处理逻辑比较复杂的)。
速度控制的原理是,控制爬虫的速度,以免访问过快被网站ban了。

中间件
在这里要单独说说中间件的概念。中间件是scrapy框架里的一个概念,scrapy是可配置的,中间件就是配置的一部分。中间件的存在意义是,装饰爬虫的爬取逻辑,使爬虫更稳健。
常有的爬虫中间件有:
设置自动ip
设置user-agent,模仿不同的浏览器访问。
其实还有其他中间件,我用到的就是上面两个。至于更具体的介绍我就不说了,读者可以自行百度这些知识,爬虫中很常见的。
中间件的代码是在Master/Slave目录下的middlewares.py。
存储
存储利用HDFS实现。具体的不再描述。就是hdfs写入读入。
算法预测
预测的序列是股票的开盘价序列。在这一章节,有兴趣的读者,可以不用过多关心算法结果,而将注意力放在“算法为什么要这样构建”上。算法一共有两个。
1.BP神经网络+MSD
之所以选择BP神经网络,是为了和算法2的HTM网络比较。HTM是我最近发现的一种预测算法,适应性非常强。所以想对比测试下。
一般而言,神经网络的输入就是目标序列本身,通过“输入过去的序列,输出当前时刻序列值”这样的训练模式,构建好网络。但笔者在这里决定不这么干。
先说下我对股市的主观想法,我一直假设股市的各只股票之间互相的变动,是有关系的。比如A股票的变动,会导致B,C股票的变动,各只股票组成一个互相联系的网络,而这在一定程度上,是可以被量化的。
上面这一段话决定了我如何构建我的算法。我决定不将目标序列作为网络的输入,而使用跟目标序列有最高相似度的多条序列作为输入。比如我打算预测A股票,而又发现A股票跟 [B,C,D] 股的相似度很高,所以就用BCD股作为算法的输入,而输出用目标序列本身。
那问题来了,是怎么找到相似度最高的20条股票呢?BCD股是怎样组合成一个输入的呢?输出又是怎样的呢?
算法利用MSD相似度计算寻找相似股票。对于两只股票,如果长度一致,且每一刻的时间对应,那么,相似度就可求,也就可以找出20条相似度最高的股票。
算法本身选了20条相似股票,即对于目标序列,算法会寻找20条与之最为相似的股票作为相似股。之后算法这样构建输入输出:
输入:对于这20只股票,选择第t时刻的各个股票的对应数值,之后,这个数值除以与目标序列的MSD相似度数值,得到一个新的数值。最后,这20个新的数值组成一个长度为20的向量。
输出:选择第t+1时刻的目标股票的对应数值作为输出
比如,A股为与B,C股的MSD相似度分别为0.8,1.2,那么算法在第 t 时刻的输入为: [ValB(t)/0.8 [ V a l B ( t ) / 0.8 , ValC(t)/1.2] V a l C ( t ) / 1.2 ] ,而输出为 [ValA(t+1)] [ V a l A ( t + 1 ) ] 。
但有个难题,这个难题也是所有算法落地时要碰到的问题:股票的长度并不一致。时间也不完全对应。比如,有些股票诞生的早,有些股票已经退股。这就导致了在序列的时间连续性有问题。

2.HTM算法+Kmeans+MSD
其实我将更多的精力放在了第2个算法,在写完第一个算法的时候,我就猜测效果不会好。第1个算法更多是一种对比的尝试吧。第2个算法才是我着重的,主要我是想学习下HTM算法。
这个算法也是用相似股票的概念,但这次,笔者利用Kmeans算法对所有的股票序列进行了聚类。并且将Kmeans算法中用余弦距离求相似度的部分换为了MSD相似度。当然,在聚类的同时,还是会有股票时间对应不上的问题,因此就需要对Kmeans算法进行一定的改动。
改动主要的思想如下:
由于在比较两条序列的时候,需要两个序列等长且时间对应,因此毫无疑问需要考虑数据填充,笔者在实现的时候,在对应好时间的基础上,确实是对序列短的进行了填充,以0填充。
在修改完这点之后,由于多条序列形成的DataFrame存在很多零值,所以在利用kmeans求取相似度的时候,也要有一定的技巧,在此笔者再次修改了kmeans算法,采用了求取局部相似度的方法,最终得出俩个序列的相似度。具体请参考代码,蛮易看懂的。
我原本的想法是,聚完类后(聚类数为3),然后将各个聚类分别扔给不同的HTM算法,进行预测(这里要说下HTM的输入输出是怎样的?HTM接受的是序列中单个数值的输入,输出就是它对序列的预测值)。
但理想是丰满的,现实是骨感的。在聚类的时候,我发现聚类效果不理想。聚类数为3,但最后只得到了两类。而且两类之间在数量上差别有点大。但即便这样,我还是各自利用htm算法分别做了训练。(其实勉强来说这样也可以,因为htm算法的预测能力非常强劲)

算法结果
首先是神经网络的结果

如上,命中率在50%左右,也即非常失败了,伤心。不过在写好算法的时候就没想着可以达成多高的命中率,而且算法没有任何调参,主要是项目时间不太够了,就算了。有兴趣者可以接着往下做。
然后是HTM的
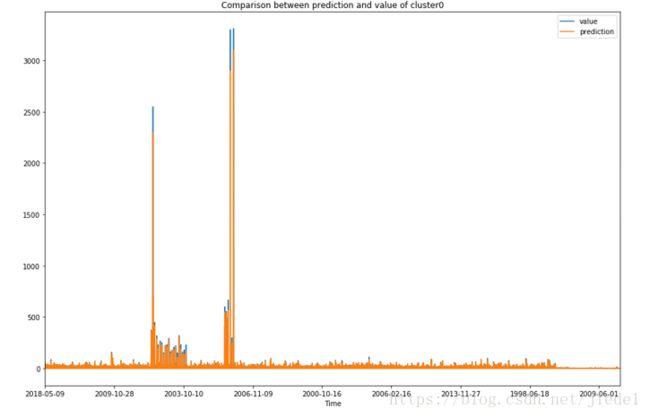
我将多条序列凑在一起,一并打印出来了,所以会看到x轴坐标怪怪的,图中有两条线,一个是原始值,一个是预测值。实际上,预测效果还是蛮好的。
总结
好了,叽叽喳喳说完了,可能有点粗糙。这项目大概耗了我一个多月,之后太忙了就不想更进了。先记录下来,有兴趣的人可以试试上手,毕竟分布式的爬虫还蛮好玩的,可以爬任何想爬的东西,而且在大数据里也算是比较经典的一个主题。
谢谢大家!