第三次博客作业
JML语言的理论基础、应用工具链情况
JML(Java Modeling Language)—— java建模语言,是一种行为接口规范语言( behavioral interface specification language, BISL)。同时,JML也是一种进行详细设计的符号语言,它鼓励你用一种全新的方式来看待Java的类和方法,既规定了方法或抽象数据类型的接口,也规定了它们的行为。
| 注释结构 |
|---|
| //@ annotation 行注释 |
| //@ annotation/ 块注释 |
| 原子表达式 | |
|---|---|
| \result | 表示返回值 |
| \old(x) | 表示x在该方法运行前的取值 |
| \not_assigned(x,y,...) | 表示括号内对象不被赋值 |
| \not_modified(x,y,...) | 表示括号内对象不被修改 |
| nonnullelements(container) | 表示container的存储对象没有null |
| type(x) | 表示x的类型 |
| typeof(x) | 表示x的准确类型 |
| 量化表达式 | |
|---|---|
| \forall | 全称量词 |
| \exists | 存在量词 |
| \sum | 一组对象的和 |
| 操作符 | |
|---|---|
| expr1<==>expr2 | 等价关系操作符 |
| expr1==>expr2 | 推理操作符 |
| \nothing | 空操作符 |
| \everything | 全部对象操作符 |
| 方法规格 | |
|---|---|
| requires X | pre-condition |
| ensures X | post-condition |
| assignable | 赋值 |
| pure | 关键字 |
| singals | 子句 |
openJML,情况如下:
SMT Solver验证
First 简单的试探
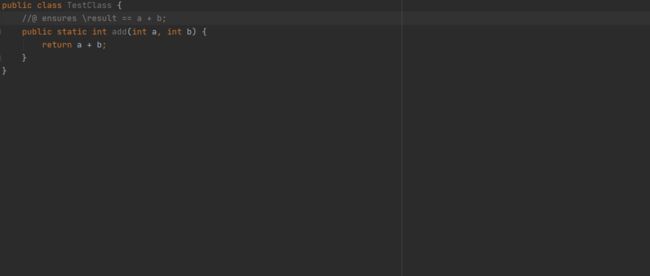

显然是这样。
整个 Group
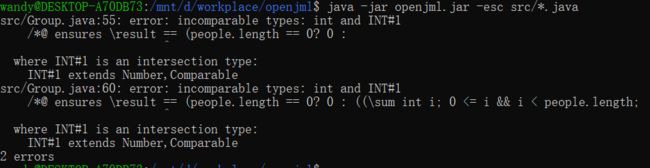
JMLUnitNG/JMLUnit

因此原因暂时无法分析,Group.java,但是可以分析简单程序,生成了测试文件。
阅读代码,大概知道所用均为极端数据与正常数据排列组合的策略。
架构设计
完全按照JML的要求进行编写,要说架构设计那也是助教们的设计。
我仅谈谈实现方法:
First:

一开始确认了使用 HashMap 来用 id 取人的方案,和并查集来使得 isCircle 复杂度 O(1),其余应该没什么
Second:
多了Group,为了减小复杂度,仅在 Group.add 里面进行操作,可能就是所谓的缓存法,将新加入人的所有关系和value遍历。
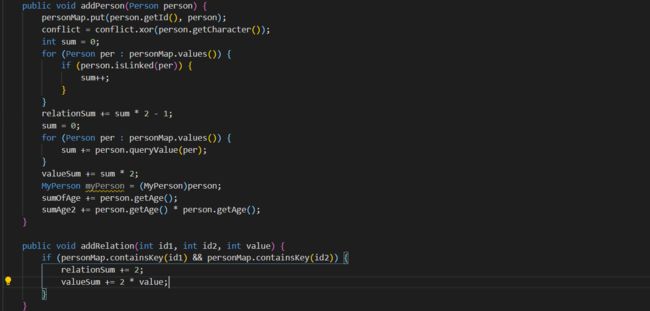
Third:
最短路径,中规中距的堆优化邻接表dijsktra(现成的PriorityQueue做堆优化,现成的Person的acquaintance作为邻接表),很容易取到有关系的人,但为了取得value更快更方便,还是用了邻接矩阵来存value,接下来只要不把初始值定为2000等这么小的数导致无法得出超过2000的最短路径导致错了三个强测点这种离谱的bug的话,就大功告成了。

tarjan,第一次接触,代码太长就不放图了,放代码。java也有现成的stack,总之tarjan就是一个dfs加上根据访问时序进行压栈出栈的过程,代码看似很长但比较容易理解,第一次按照最正宗的tarjan写完后,发现总是强连接成功,后来发现是因为我们这个无向图,a能访问b,则必然又能从b访问回去,为了杜绝这种现象,我用了一个 int tool,来保存上一次访问到的点,然后下一次只有当 tool 不等于当前点时,才能继续 dfs,这就避免了相邻两点永远强链接的局面发生,成功搞定。
@Override
public boolean queryStrongLinked(int id1, int id2) throws PersonIdNotFoundException {
if (!contains(id1) || !contains(id2)) {
throw new PersonIdNotFoundException();
}
if (id1 == id2) {
return true;
}
if (!isCircle(id1, id2)) {
return false;
}
int from = idMap.get(id1);
int to = idMap.get(id2);
time = 0;
tool = -1;
Stack stack = new Stack();
int[] dfn = new int[index];
int[] low = new int[index];
isFinished = false;
ansStrong = false;
for (int i = 0; i < index; i++) {
if (dfn[i] == 0) {
dfs(from, to, i, dfn, low, stack);
}
}
return ansStrong;
}
private void dfs(int from, int to, int x, int[] dfn, int[] low,
Stack stack) {
if (isFinished) {
return;
}
stack.push(x);
dfn[x] = low[x] = ++time;
for (int y = 0; y < index; y++) {
if (y != tool && dsts[x][y] != 2000000) {
if (dfn[y] == 0) {
tool = x;
dfs(from, to, y, dfn, low, stack);
if (isFinished) {
return;
}
low[x] = Math.min(low[x], low[y]);
} else if (stack.contains(y)) {
low[x] = Math.min(low[x], low[y]);
}
}
}
if (dfn[x] == low[x]) {
int count = 0;
int a;
while ((a = stack.pop()) != x) {
if (a == from || a == to) {
count++;
}
}
if (x == from || x == to) {
count++;
}
if (count == 2) {
isFinished = true;
ansStrong = true;
} else if (count == 1) {
isFinished = true;
ansStrong = false;
}
}
}
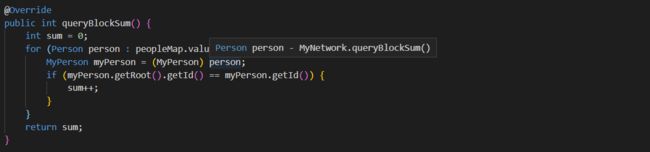
BlockSum:
由于使用了并查集,直接搜索根节点的数量就行了。
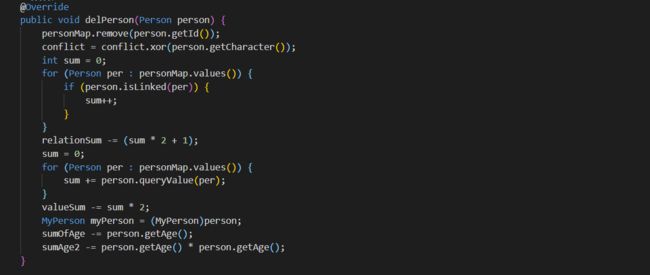
delFromGroup:
由于使用了缓存法,需要进行与 add 相反的操作。
其余好像没什么东西,以上。
Bug及修复
BUG: 三次作业中共有一处bug,第三次作业:dijsktra求最短路径,初始值本应该为较大整数,但一时脑抽 初始化为2000,导致无法出现长于2000的路径,错了三个点。
修复:2000->2000000,replaceAll。
心得体会
JML使得每个方法仅关注自己的事情,且由明确的表述使得验证起来更为容易,不容易出现差错,极大提高了编写代码的速度,而且调理清晰出错率低,但是感觉不够简明,光是写JML规格都是一项大工程了,可能这也是其无法流行起来的原因吧。但是确实好处很大,在团队合作中,这种规格,在提升团队协作效率和正确性可以产生巨大的优势