【爬虫学习2】Requests cookies爬取知乎个人timeline
上次用Requests爬取了静态网页-正则表达式加Requests爬取猫眼电影排行
这次想尝试使用requests.Session进行cookie登录爬取网页内容
-全部代码见于我的Git
- 准备素材
- 新建工程及文件
- 获取cookies和headers
- 一个注意
- 编写爬虫
- 载入并格式化cookis
- 载入并格式化headers
- 获取网页并保存
- 保存网页的目的
- 一个注意
- 正则表达式匹配
- 小技巧
- 获取结果
- 一个问题
- 参考资料
准备素材
准备cookies内容和headers内容
新建工程及文件
获取cookies和headers
1.进入知乎并登录
2.F12 打开开发工具->选择“网络”选项卡 (这里使用的是win10自带的Microsoft Edge)
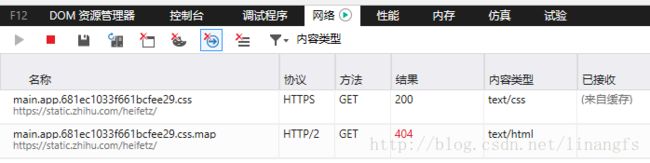
3.刷新页面并选中列表中第一项
右侧可看到如图cookies和headers等相关信息
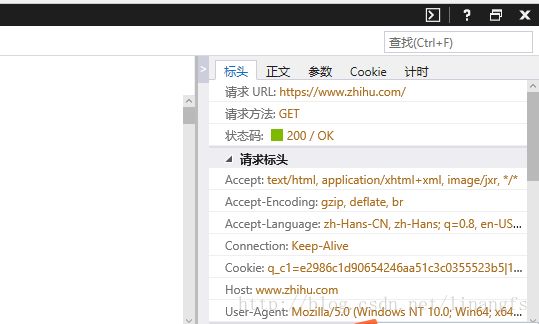
4.右键cookie条目->复制值
打开之前新建的cookie文件 直接粘贴进去

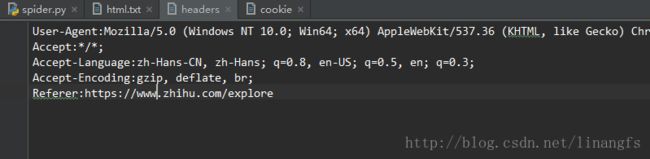
5.按照4的步骤分别复制
User-Agent
Accept
Accept-Language
Accept-Encoding
Referer条目至headers文件并按照如图修改和格式化
一个注意
在爬取时如果不加入headers可能会被服务器返回500错误码
加上headers旨在骗过服务器
编写爬虫
载入并格式化cookis
def get_cookie():
'''从文件中获得cookies'''
with open('cookie', 'r') as f:
acookie = {}
for line in f.read().split(";"):
name, value = line.strip().split('=', 1)
acookie[name] = value
return acookie载入并格式化headers
def get_headers():
'''获得标准头文件'''
with open('headers', 'r') as f:
headers = {}
for line in f.read().split(';\n'):
name, value = line.split(':', 1)
headers[name] = value
return headers获取网页并保存
import requests
def save_html(html):
'''保存网页'''
with open('html.txt', 'w', encoding='utf-8') as f:
f.write(html)
f.close()
def main():
url = 'https://www.zhihu.com'
headers = get_headers()
cookies = get_cookie()
s = requests.Session()
req2 = s.get(url, headers=headers, cookies=cookies)
html = req2.content.decode('utf-8')
save_html(html)
if __name__ == '__main__':
main()
保存网页的目的
1.若是动态网页,使用浏览器的审查元素功能获得的代码和爬虫获得的代码会有差异,而正则表达式是对爬取的代码进行匹配,故要以获取的页面代码作为参考。
2.方便将代码块复制出来对每个匹配项进行单独的测试正则表达式在线测试
一个注意
这里通过content获得页面必须使用.decode格式化成utf-8格式
html = req2.content.decode('utf-8')保存时write方法中也必须加入encoding=’utf-8’参数
open('html.txt', 'w', encoding='utf-8')否则中文是乱码
正则表达式匹配
通过审查元素和保存下来的网页配合分析
可构造如下正则表达式
import re
def parse_one_page(html):
'''进行正则匹配'''
pattern = re.compile('(.*?)' #用户姓名
+'.*?(.*?)' #用户操作
+'.*?(.*?) #推荐内容
+'.*?', re.S) #作者
items = re.findall(pattern, html)
for item in items:
yield {
'ActiveUser': item[0],
'Active': item[1],
'Title': item[2],
'Author': item[3]
}
小技巧
这里拿不准可以从html.txt相关代码块拿出来单独测试每一个匹配项
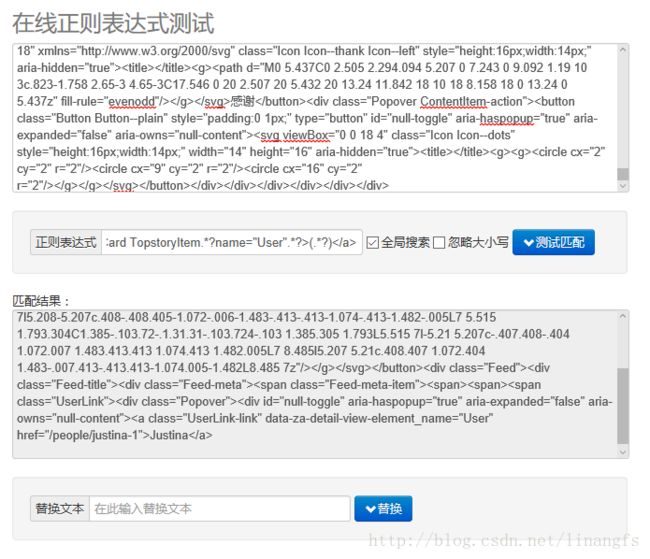
获取结果
def main():
url = 'https://www.zhihu.com'
headers = get_headers()
cookies = get_cookie()
s = requests.Session()
req2 = s.get(url, headers=headers, cookies=cookies)
html = req2.content.decode('utf-8')
save_html(html)
##n = 0
for item in parse_one_page(html):
print(item)
结果如图

一个问题
这里我们打开保存下来的html文件会发现
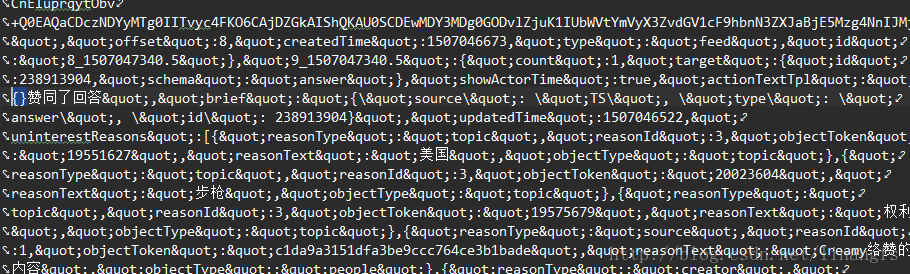
即爬虫没有获取到选中处的内容
并且
查看爬取结果会发现原页面的条数远远大于结果显示的9条
原因和解决方法未知
期待在接下来学习中解决这个问题
参考资料
http://www.jianshu.com/p/c94de9f1ef7c
http://blog.csdn.net/majianfei1023/article/details/49927969
http://docs.python-requests.org/zh_CN/latest/user/advanced.html#advanced