爬取国内高匿代理,并验证每个代理是否可用
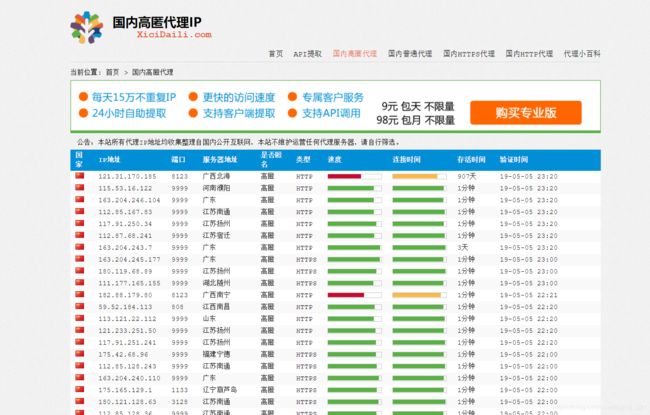
目标网站https://www.xicidaili.com
 |
|
一、建立项目
scrapy startproject proxy_example
cd
scrapy genspider XiciSpider www.xicidaili.com
二、修改setting
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
三、信息提取
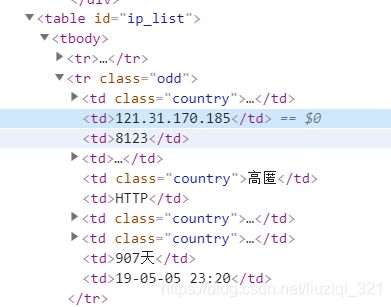
这里我们提取ip,代理类型(http or https),端口号
 |
|
四、编写spider
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
import json
class XiciSpider(scrapy.Spider):
name = 'Xici_proxy'
allowed_domains = ['www.xicidaili.com']
#start_urls = ['http://www.xicidaili.com/']
#只爬取前3页
def start_requests(self):
for i in range(1,4):
yield Request('https://www.xicidaili.com/nn/%s'%i)
def parse(self, response):
for sel in response.xpath('//table[@id="ip_list"]/tr[position()>1]'):
ip = sel.css('td:nth-child(2)::text').extract_first()
port = sel.css('td:nth-child(3)::text').extract_first()
scheme = sel.css('td:nth-child(6)::text').extract_first()
#使用爬取到的代理再次发送请求到http(s)://httpbin.org/ip,验证代理是否可用
url = '%s://httpbin.org/ip'%scheme
proxy = '%s://%s:%s'%(scheme,ip,port)
meta = {
'proxy':proxy,
'dont_retry':True,
'download_timeout':10,
#一下两个字段是传递给check_available方法的信息,方便检测
'_proxy_scheme':scheme,
'_proxy_ip':ip,
}
yield Request(url, callback=self.check_available,meta=meta,dont_filter=True)
def check_available(self,response):
proxy_ip = response.meta['_proxy_ip']
#判断代理是否具有隐藏ip功能,httpbin.org/ip返回两个访问ip,用split拆分
if proxy_ip == json.loads(response.text)['origin'].split(',')[0]:
yield{
'proxy_scheme':response.meta['_proxy_scheme'],
'proxy':response.meta['proxy'],
}
五、运行查看结果
scrapy crawl Xici_proxy -o proxy_list.json --nolog
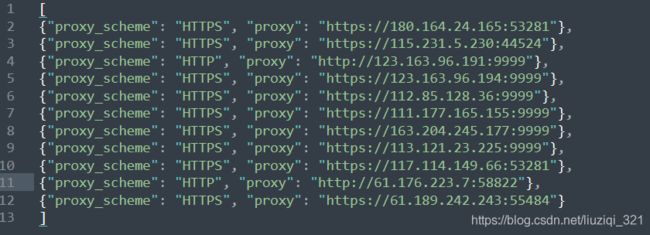
爬取了前三页的页面我们得到了11个代理IP
六、实现随机代理
middlewares.py中输入以下代码
from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware
from scrapy.exceptions import NotConfigured
from collections import defaultdict
import json
import random
import re
class RandomHttpProxyMiddleware(HttpProxyMiddleware):
@classmethod
def from_crawler(cls, crawler):
# 从配置文件中读取用户验证信息的编码
auth_coding = crawler.settings.get('HTTPPROXY_AUTH_ENCODING', 'latin-1')
# 从配置文件中读取代理服务器列表文件(json)的路径
proxy_file_file = crawler.settings.get("HTTPPROXY_PROXY_LIST_FILE")
return cls(auth_coding, proxy_file_file)
def __init__(self, auth_encoding='latin-1', proxy_list_file=None):
if not proxy_list_file:
raise NotConfigured
self.auth_encoding = auth_encoding
self.proxies = defaultdict(list)
# 从json文件中读取代理服务器信息,填入self.proxies
with open(proxy_list_file) as f:
proxy_list = json.loads(f.read())
for proxy in proxy_list:
scheme = proxy['proxy_scheme']
url = proxy['proxy']
self.proxies[scheme].append(self._get_proxy(url, scheme))
def process_request(self, request, spider):
# 随机选择一个代理
scheme = re.findall("(.*?):", request.url)[0].upper()
creds, proxy = random.choice(self.proxies[scheme])
request.meta['proxy'] = proxy
if creds:
request.headers['Proxy-Authorization'] = b'Basic' + creds
setting
DOWNLOADER_MIDDLEWARES = {
'proxy_example.middlewares.RandomHttpProxyMiddleware':745,
}
HTTPPROXY_PROXY_LIST_FILE='proxy_list.json'
新建一个爬虫test_random_proxy
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
import json
class RandomProxySpider(scrapy.Spider):
name = "test_random_proxy"
def start_requests(self):
for _ in range(20):
yield Request("http://httpbin.org/ip",dont_filter=True)
yield Request("https://httpbin.org/ip",dont_filter=True)
def parse(self,response):
print(json.loads(response.text))
运行查看效果
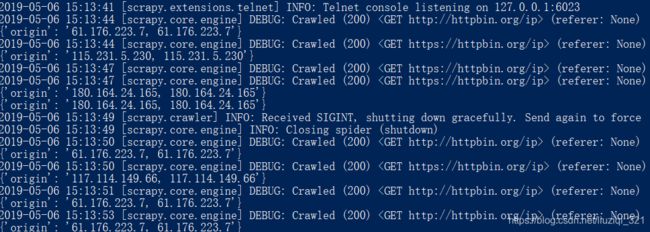
实现了随机代理功能