【python实现网络爬虫(10)】Selenium框架以任意关键词爬取淘宝商品数据
以任意关键词爬取商品数据
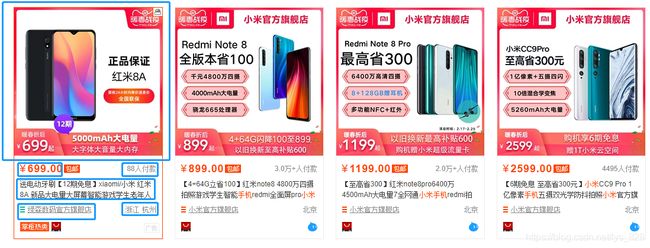
比如这里以输入中文为例:小米手机(需要扫码登录)

爬虫逻辑:【登陆】-【访问页面 + 采集商品信息 - 翻页】
1)函数式编程
函数1:get_to_page(keyword) → 【登陆】
keyword:关键字
函数2:get_data(page_num) → 【访问页面 + 采集数据信息 - 翻页】
page_num:翻页次数
2)采集字段
商品照片、价格、付款情况、标题、店家名称、店铺地等字段
前期准备和封装第一个函数
import time
import pandas as pd
from selenium import webdriver
def get_to_page(keyword):
browser = webdriver.Chrome()
browser.get('https://s.taobao.com/search?q={}'.format(keyword))
time.sleep(15)
#用于扫码,可以把时间设置的长一些,毕竟是人工操作
#尝试过密码输入,无法通过滑块验证
print("程序已经成功进入目标页面")
return browser
该部分代码实现的就是:导入相关的库,然后调用selenium框架进行登录后,跳转到指定关键词的搜索页面
封装第二个函数
该部分就是商品信息的获取以及错误异常处理和可视化输出的问题
步骤一、获取商品对应的标签,这里使用xpath路径(最为简洁,直接复制粘贴就可以了)
比如获取标题的信息,首先进入到检查界面,找到标题对应的位置,然后右键copy,然后在选择copy XPath,将复制的内容粘贴到下面的.browser.find_element_by_xpath的括号里面即可
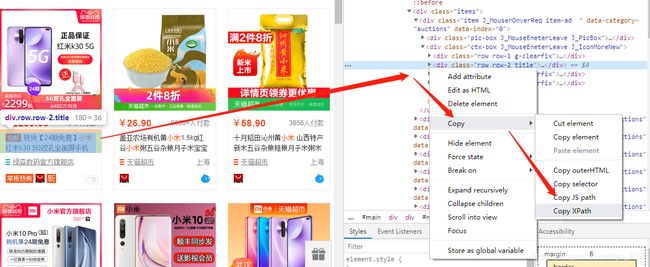
步骤二、创建个字典用以保存数据
dic = {}
dic['标题'] = browser.find_element_by_xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[1]/div[2]/div[2]').text
print(dic)
输出的结果为:
![]()
可以正常输出后,就可以把获取的其他字存放到字典里面了,其他字段的xpath路径也是直接复制粘贴的
dic = {}
dic['img'] = browser.find_element_by_xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[1]/div[1]/div/div[1]/a/img').get_attribute('src')
dic['标题'] = browser.find_element_by_xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[1]/div[2]/div[2]').text
dic['店铺'] = browser.find_element_by_xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[1]/div[2]/div[3]/div[1]/a/span[2]').text
dic['店家地址'] = browser.find_element_by_xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[1]/div[2]/div[3]/div[2]').text
dic['产品售价'] = browser.find_element_by_xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[1]/div[2]/div[1]/div[1]/strong').text
dic['付款情况'] = browser.find_element_by_xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[1]/div[2]/div[1]/div[2]').text
print(dic)
输出的结果为:

检查核对,这是以“小米手机”为关键次搜索的第一个商品,在网页的信息如下,可以看出完全匹配
步骤三、xpath路径解析,使用xpath路径的好处在于每个商品的标签都是按照顺序摆放的,比如这里的商品信息,都是分散在第四个【div】标签下面,解析如下:
//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[1]/div[2]/div[2] #第一个商品标题的路径
//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[2]/div[2]/div[2] #第二个商品标题的路径
//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[3]/div[2]/div[2] #第三个商品标题的路径
......
分析可以得出,只要是修改第四个div[]里面的内容就可以实现对应商品数据的获取,而一页的商品是48个,直接for i in range(1,49),就可以实现第一页的商品信息的获取了,为了防止爬取过程中出错,加上异常错误判断的处理(比如有的商品上面就没有地址,为了保证程序正常运行下去,加上try-except进行处理)
for i in range(1,49):
try:
dic = {}
dic['img'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[1]/div/div[1]/a/img').get_attribute('src')
dic['标题'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[2]').text
dic['店铺'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[3]/div[1]/a/span[2]').text
dic['店家地址'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[3]/div[2]').text
dic['产品售价'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[1]/div[1]/strong').text
dic['付款情况'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[1]/div[2]').text
print(dic)
except:
print("数据采集失败")
运行的结果如下
步骤四、翻页处理,就是get_datas函数里面传参的page_num,进行遍历即可,这里面要完成翻页的功能,采用的是点击下面的数字框,然后输入要爬取的数字,接着点击“确定”按钮即可

for j in range(1,page_num+1):
try:
num = browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/input')
num.clear()
num.send_keys(j+1)
browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/span[3]').click()
time.sleep(5)
print("已爬取{}页,程序休息.....{}s".format(j,5))
except:
continue
至此该过程的所有的步骤都已经操作完成,封装第二个函数,为了将爬取的数据之中存放在电脑上,需要将所有的字典都存放在列表里,最后整个函数返回的是一个存放数据的列表。如下(两个try-except一个是应对页面的数据爬取的问题,还有一个应对的是翻页的问题,最后为了保证数据爬取到位,在每次翻页之后要让浏览器休息一下,设置一个暂停时间,一般5s足够)
def get_datas(page_num):
data_lst = []
for j in range(1,page_num+1):
try:
for i in range(1,49):
try:
dic = {}
dic['img'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[1]/div/div[1]/a/img').get_attribute('src')
dic['标题'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[2]').text
dic['店铺'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[3]/div[1]/a/span[2]').text
dic['店家地址'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[3]/div[2]').text
dic['产品售价'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[1]/div[1]/strong').text
dic['付款情况'] = browser.find_element_by_xpath(f'//*[@id="mainsrp-itemlist"]/div/div/div[1]/div[{i}]/div[2]/div[1]/div[2]').text
print(dic)
data_lst.append(dic)
except:
print("数据采集失败")
num = browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/input')
num.clear()
num.send_keys(j+1)
browser.find_element_by_xpath('//*[@id="mainsrp-pager"]/div/div/div/div[2]/span[3]').click()
time.sleep(5)
print("已爬取{}页,程序休息.....{}s".format(j,5))
except:
continue
print("一共获取{}条数据".format(len(data_lst)))
return(data_lst)
最后执行代码
通过分块执行,上边是导入的库和封装的函数,下面直接就是调用函数和保存数据的过程即可
if __name__ == '__main__':
browser = get_to_page('小米')
data_lst = get_datas(3)
#前两行是直接完成爬取淘宝中3页以小米手机为关键词搜索得到的商品信息数据
data = pd.DataFrame(get_datas(3))
data.to_excel('数据.xlsx',index=False)
#后两行是把获得的数据直接存放在本地
输出的结果