- HW1
- 思路
- 程序结构
- UML类图分析
- 复杂度分析
- 代码规模分析
- HW2
- 思路
- 程序结构
- UML类图分析
- 复杂度分析
- 代码规模分析
- HW3
- 思路
- 程序结构
- UML类图分析
- 复杂度分析
- 代码规模分析
- 总结
- Test n Bugs
- 测试方法
- 测试情况
- 应用对象创建模式
- 心得体会
- Test n Bugs
HW1
思路
本次作业,需要完成的任务为幂函数多项式求导。任务总体划分为三部分:IO处理,求导计算,性能优化。
在第一部分—IO处理中,本次作业保证输入数据全部为合法的表达式,不需要进行格式检查。
首先预处理读入字符串,删除空白字符,保证字符串以符号开头、结尾,方便进行以
Term项为单位的正则匹配。然后循环扫描输入字符串匹配
Term项:以多项式的运算符为分界线,每次匹配到 分界线 -Term- 分界线 后,从字符串中取出 分界线 -Term这一group,获得Term项进行后续处理,并在取出此group后的子字符串中继续匹配,直到子字符串仅为末尾运算符。"(?" + "[+-]" +"(" + regterm + ")" + ")" + "[+-]" 在输出中只需遍历存储结果的HashMap,结合优化操作输出。
在第二部分—求导计算中,由于本次作业处理幂函数多项式简单,可以用 coef * x ** power 统一表示。
因此设计
Term类存储幂函数的coefficient和power;针对幂函数多项式,又设计
Poly类,包含以power为key,coef为value的HashMap,利用其特性自动进行同类项合并。Poly类与Term类存在一定程度上的重复,但保留Term类以保留可扩展性,当函数种类增加时合并同类项的处理变得复杂,此种操作需要修改。
在第三部分-性能优化中,有以下种类的优化操作:
省略空白字符
省略
coef 1、-1省略
power 1、-1、0省略
0项合并同类项
如果存在正数项,前导正数项输出
在优化时同时要考虑特殊情况,避免因优化造成的错误,如输出仅为
1、0等。
程序结构
分析工具:UML,MetricsReloaded,Statistic,DesigniteJava
UML类图分析
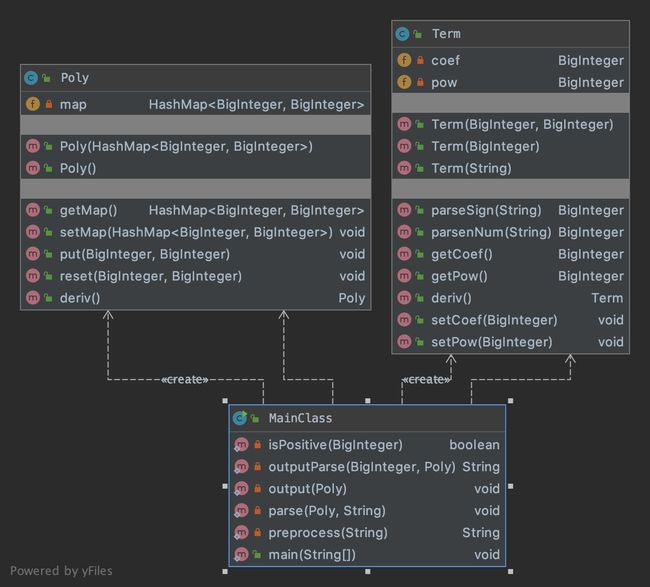
本次作业设计的主要问题是没有建立处理IO的class,在MainClass中直接通过几个函数进行了IO处理,未封装对字符串的IO操作,这里还缺乏面向对象的意识。
复杂度分析
Total LOC analyzed: 215// Number of classes: 3// Number of methods: 23
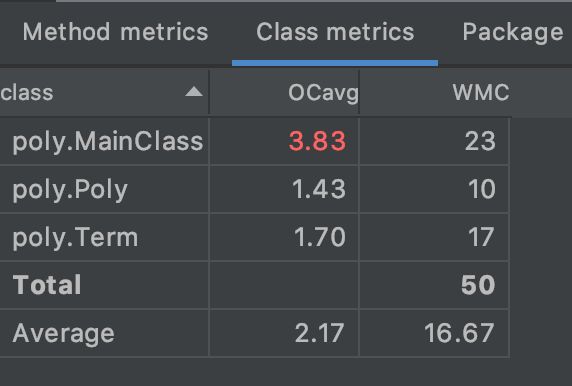
其中OCavg代表类的方法的平均循环复杂度,WMC代表类的方法的总循环复杂度。
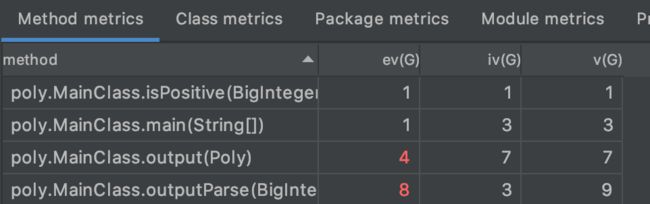
其中Essential Complexity (ev(G)、Module Design Complexity (iv(G))、Cyclomatic Complexity (v(G)。
| Type Name | Method Name | Implementation Smell | Cause of the Smell |
|---|---|---|---|
| MainClass | outputParse | Complex Method | Cyclomatic complexity of the method is 9 |
| MainClass | preprocess | Complex Conditional | The conditional expression !(((str.charAt(0) == '+') || (str.charAt(0) == '-')) && ((str.charAt(1) == '+') || (str.charAt(1) == '-'))) is complex. |
由此可见MainClass中的IO处理methods导致了复杂度增加。并且outputParse这一method中的判断复杂,独立路径的条数多,所以圈复杂度高。而preprocess这一method中判断字符串是否需要增加前导符号的判断条件复杂。
代码规模分析

可见未建立IO类造成的MainClass规模过大问题。Term类由于存在部分输入字符串处理,代码规模也偏大。
HW2
思路
本次作业在hw1的基础上增加了正余弦函数。任务总体划分为三部分:IO处理,求导计算,性能优化。
在第一部分—IO处理中,需要进行格式检查。这部分与第一次作业基本相同。
封装为
Input类处理输入。由于需要进行格式检查,在循环匹配Term项时,增加分支判断:若匹配不到则输出
WRONG FORMAT!
在第二部分—求导计算中,本次作业增加了正余弦函数,可以继续沿用 coef * x ** power 统一表示,此时的coef为正余弦多项式。
为了沿用HashMap特性自动合并同类项,本次作业设计继续采用HashMap存储多项式。
在第一次作业的基础上进行扩展操作。扩展
Term类的coefficient从BigInteger类型到自定义的SinCosPoly类型,即正余弦多项式;同样地,扩展Poly类的HashMap的value为SinCosPoly类型。设计
SinCosPoly类包含以powers为key,coef为value的HashMap,利用其特性自动进行同类项合并。其中powers为自定义的DeltaTerm类型,包含正弦函数指数与余弦函数指数。
在第三部分-性能优化中,除第一次作业中针对幂函数的优化操作外,还有如下优化操作:
x**2以x*x形式输出三角函数多项式递归化简
受到了群里分享的往届性能优化策略和讨论区的启发,采用此方法。
扫描多项式,提出一个
sin(x)**2的因子拆分为1-cos(x)**2后得到新的多项式,若新的多项式长度缩短,则返回新的多项式对该函数的递归调用。可使用
cos(x)**2 = 1-sin(x)**2的拆分规则重复上述操作,并且整体重复运行几次。为避免爆栈,对递归深度设置了阈值。
程序结构
UML类图分析
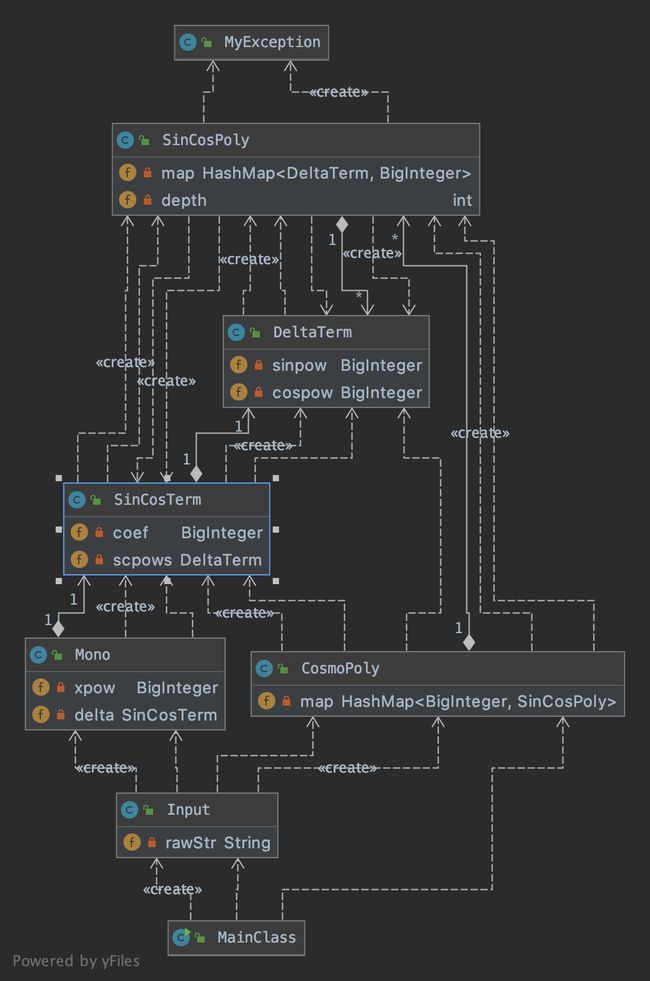
这里设计的类有些复杂:一方面是因为想利用HashMap简化合并同类项的操作,此次作业的优化存在提出幂函数因子对正余弦多项式进行化简这一步,于是设计直接扩展coefficient因子;另一方面想保留可扩展性,如SinCosTerm类为正余弦函数因子对象。后续发现其实即复杂了本次作业,又没建立起可扩展性。主要的原因是没有考虑清楚后续可扩展性的需要,因子的种类可以增加,也可以进行嵌套,这时未对嵌套进行思考,思考后也许会设计不需重构的方法,或者只针对此次作业,设计有所简化。
复杂度分析
Total LOC analyzed: 637// Number of classes: 8// Number of methods: 65

在MainClass类中对输入的字符串事先进行了是否无读入、是否为空、trim后是否为空、是否存在 \f\r等判断,因此MainClass类复杂度上升,其实这些判断存在重复,有更好的方法处理,比如可以和后续合并,通过复杂度分析可以发现类似的问题,可以帮助优化。

| Type Name | Method Name | Implementation Smell | Cause of the Smell |
|---|---|---|---|
| Mono | Mono | Complex Conditional | The conditional expression !((xpowCnt.compareTo(ZERO) == 0) && (sinpowCnt.compareTo(ZERO) == 0) && (cospowCnt.compareTo(ZERO) == 0)) is complex. |
CosmoPoly类复杂度高,是因为其中unfoldPoly和printOut方法处理输出,涉及多条判断语句,并且printOut方法中嵌套了多种功能的操作,比如前导正项输出的操作,增加了复杂度,可以提出此操作作为一个method调用。
SinCosPoly类中递归优化方法复杂度高,因为此方法包含了两种拆分的优化,并且在拆分项后clone map、查找同类项、合并同类项等操作增加了复杂度。
SinCosTerm类中的toString方法和SinCosPloy类中的isZero方法涉及多个判断语句,圈复杂度高。
Mono类的构造方法对输入预处理后的Term项判断类别并获得相应的指数和系数值,存在多个判断分支,复杂度高。
代码规模分析

可见由于设计复杂整体代码量高,其中SinCosPoly类注释多是因为此类中写了多种类型及层次性的优化,最后只采用了递归优化,其余优化注释掉了。
HW3
思路
本次作业在第二次作业的基础上增加了组合嵌套。由于嵌套的树结构,无法沿用HashMap,需要重构。作业的设计根据指导书的启发,关键思想是化整为零。
- 对于函数和组合规则(常数、幂函数、三角函数、乘法、加减法)建立类
- 对于上述的类均实现一个接口,包含求导方法
getDeriv和化简方法simplify。- 把整个表达式构建为树结构,进行链式求导并优化。
在IO处理部分,Parser类利用递归下降法处理输入字符串,每个类重写toString方法实现输出。
对于输入的字符串,首先进行预处理:通过正则匹配判断是否存在空白字符非法的所有情况,如果通过判断则删除空白字符。
Parser类中的insym方法读入字符,进行词法分析,并且对于形式化表述的每个非终结符构造方法。
在优化部分,有每个类自己的simplify方法,但是本次作业只实现了简单常数和幂函数的合并同类项,在优化部分还有空间。
在递归下降分析的过程中,合并常数项与幂函数项,并且当项和因子类只含有一个元素时,返回此因子,降低嵌套复杂度。
重写了每个类的
equals方法和compareTo方法为了在AddSub和Mult类中实现合并同类项的优化,但是提交的版本只应用了基础性的合并同类项。
程序结构
UML类图分析
Total LOC analyzed: 787// Number of classes: 10// Number of methods: 74
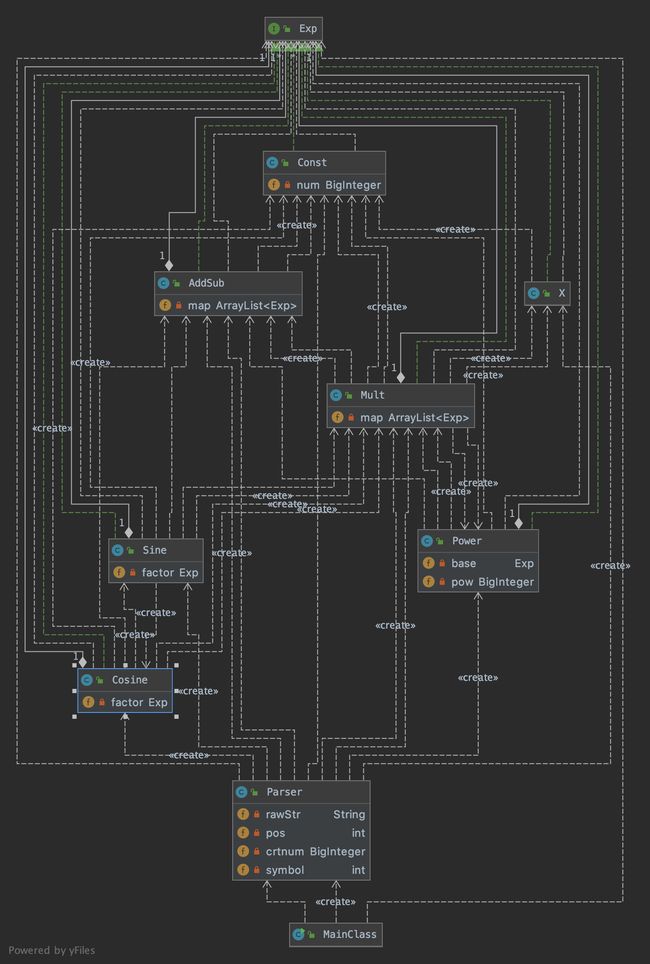
- 基础函数类有
Const、Sine、Cosine、X - 复杂函数类有
Power - 组合规则类有
AddSub、Mult
复杂度分析
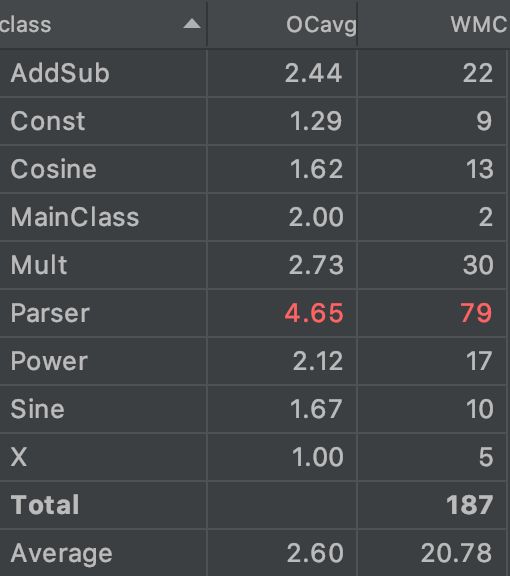
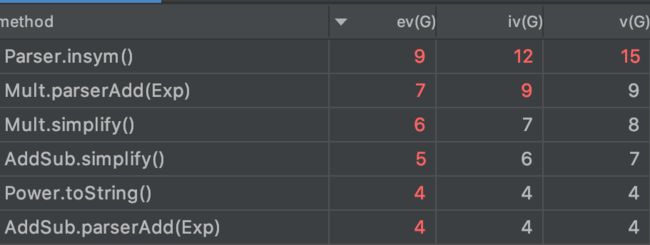

| Type Name | Method Name | Implementation Smell | Cause of the Smell |
|---|---|---|---|
| Parser | isdelta | Complex Conditional | The conditional expression (pos >= rawStr.length() - 2) || (!((rawStr.charAt(pos + 1) == regex.charAt(1)) && (rawStr.charAt(pos + 2) == regex.charAt(2)))) is complex. |
| Parser | isdelta | Long Statement | The length of the statement "if ((pos >= rawStr.length() - 2) || (!((rawStr.charAt(pos + 1) == regex.charAt(1)) && (rawStr.charAt(pos + 2) == regex.charAt(2))))) {" is 134. |
| Parser | insym | Magic Number | The method contains a magic number: 7 |
| Parser | insym | Magic Number | The method contains a magic number: 4 |
| Parser | insym | Magic Number | The method contains a magic number: 8 |
| Parser | insym | Magic Number | The method contains a magic number: 5 |
| Parser | insym | Magic Number | The method contains a magic number: 6 |
Parser类的insym方法根据读入的下一个字符分类判断类型,存在多个判断分支,所以复杂度高。
Parser类的exp方法和expMain方法其实存在重复代码,这里可以进行化简,方法中对于符号存在多次判断并且加入了优化部分,复杂度高。
AddSub和Mult类中的ParserAdd方法为处理输入时合并同类项,这里通过遍历查找进行合并同类项,复杂度高。而simplify方法判断分支多,对于HashMap的修改操作存在一些冗余,复杂度较高。
Parser类中symbol记录当前读入的token类型,这里可以通过枚举法消除Magic Number。
代码规模分析

Parser类、组合规则类AddSub和Mult承担了主要的代码量,主要集中在Parser类的结合优化的递归下降法,以及AddSub和Mult中的合并同类项等优化。
总结
Test n Bugs
测试方法
- 分类树
以设定的形式化表述出发,可能出现的情况表现为树形,简单构造各类情况的测试用例进行测试。
- 自动化测试
使用python package xeger、os、sympy进行随机测试用例生成、求导比较。
生成测试用例可根据正则表达式直接生成(hw1 n hw2)或分部生成(hw3),并控制各部生成概率;
poly += xg.xeger("[+-]") + gen_term() ... term += xg.xeger("\\*") + gen_factor() ...编译并结合重定向运行代码;
删除整数的前导0;
使用sympy.sympify与sympy.diff得到表达式、导数,根据判定模式进行表达式等价判定;
保存比较结果到文件。
测试情况
- 在第二次作业中,由于未能仔细阅读并理解任务书中关于空白字符的描述,错误地认为不会出现[ \t]以外的空白字符,未能检测非法空白字符的WRONG FORMAT情况。这里主要是阅读任务书出现理解问题后,应反复阅读仔细思考;也可积极和同学询问请教。
- 在第三次作业中,采用预先判断是否存在空白字符非法的所有情况之后删除空白字符的做法,但是忽略了一种特殊的非法情况。这里其实根据分类树的办法已经构造了此非法用例,但是在测试的过程中进行了自动化批量测试,没有逐一认真阅读输出结果文件(忽略了检查WF case有正常输出这一项)。对于非法情况也应考虑任务书中枚举情况之外的特殊情况。
- 互测中主要采用自动化全面/定点测试+分析错误的办法,在第一次作业中hack到符号处理的bug;在第二次作业中发现一些WF的bug,如输入空字符串,但没有hack到bug;在第三次作业中hack到符号处理的bug、对于三角函数求导不正确的bug、递归过深bug、括号处理不当bug。
应用对象创建模式
本单元的作业主要涉及了工厂模式。工厂模式用于封装和管理对象的创建,是一种创建型模式。
在第三次作业中我设计了接口,让不同的因子类实现此接口,这里可以增加一个工厂类,在处理输入字符串中识别因子类型后利用工厂进行对象的创建,这样将类的实例化工作交给实现类完成,扩展性好,并且可以降低对象之间的耦合度。
心得体会
在预习任务和第一单元的任务中我逐步了解并深化了面向对象的概念。遇到问题之后自己去积极解决的全部都很有趣。原来总结作业比Coding作业要花更多的时间^ ^终于要写完了可太开心了。