大数据学习——dataX源码重新打包+测试
dataX工具(可执行的资源包),源码的下载和部署请参考上一篇博文:https://blog.csdn.net/qq_15903671/article/details/88862619
dataX工具包从官网下载之后可以发现他加压后有将近1G的大小。显然我们不希望一个ETL工具太大。以下的博文我将从dataX源码中保留oraclereader插件和hdfswrtier插件,重新对dataX进行打包使用。主要包括:按需打包dataX插件,配置json控制文件,测试。
一、保留部分插件重新打包dataX
原生的dataX结构是稳定的框架配合可横向扩展的插件,主要分reader和writer插件,基本上主流的数据存储工具都有配好的reader和writer了。使用时可以根据需要保留部分插件。
1.1 修改pom.xml文件
在DataX-master根目录下的pom.xml文件将核心组件、公共组件、reader/writer插件都以module的方式组装到一起,把不需要的注释掉就行了。

如图所示,我只保留了oraclereader和hdfswriter,因为后面我需要从oracle中抽取数据到hadoop-hive的orc表中。
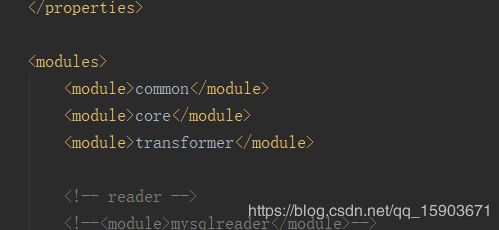
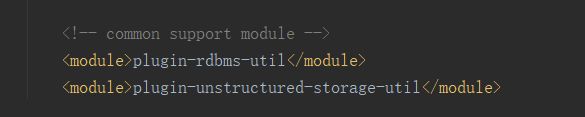
下手留神,这几个module别删掉了。
1.2 修改package.xml文件
在pom.xml文件的下方可以看到plugin标签里定义了maven-assembly-plugin插件来辅助打包,指定package.xml文件为描述文件
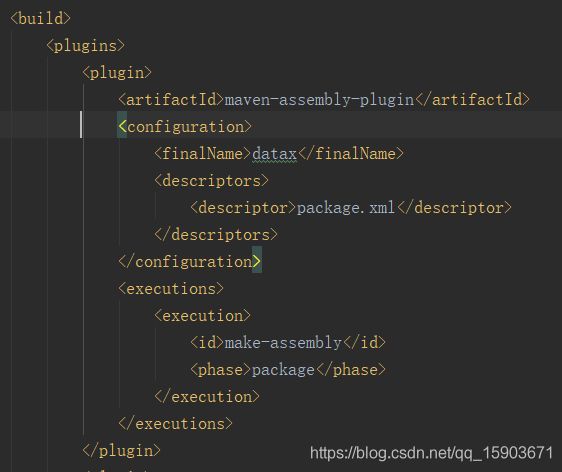
那么,打包前就要找到这个pacakge.xml了(这里是相对路径,package.xml和pom.xml在同一个目录下)
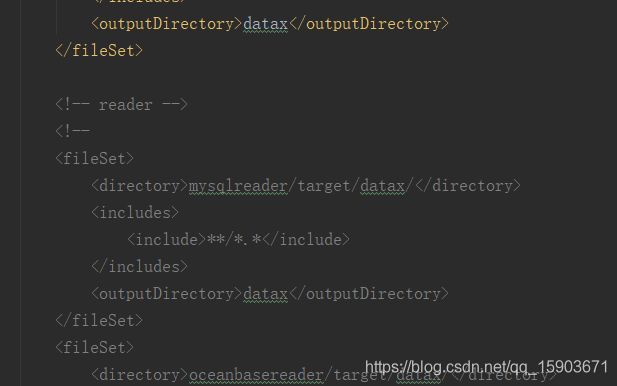
package.xml里fileSet标签中又看到了众多的插件,不要的干掉!!!pom.xml文件里注释掉多余插件是让maven打包前减少不必要的编译检查源码、检查并下载依赖包等操作,而package.xml里注释掉多余的插件是不再拷贝各插件中的jar文件、配置文件等到打包的目标路径。这样,生成的dataX包就不会像原来那么大了。
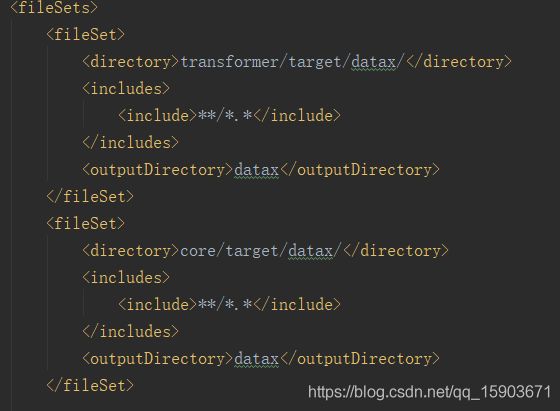
手下留情,上图中的几个fileSet就还是要保留的。
1.3 maven重新打包dataX
依据userGuid.md文件中的操作说明,使用maven指令进行打包。
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
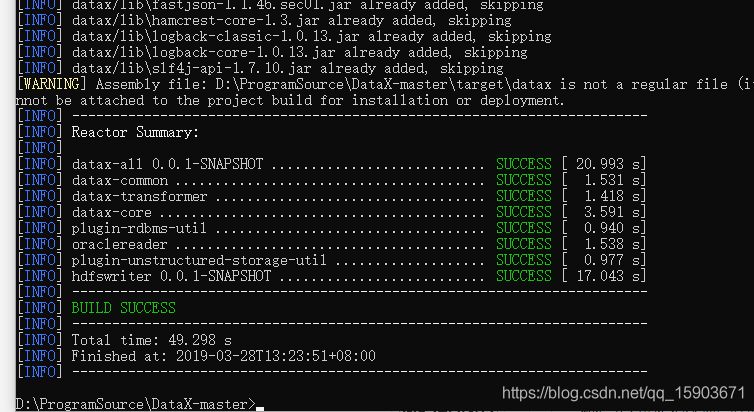
1.4 打包完成后生成的文件在哪?我们一步一步找
pom.xml文件中看finalName这行写的是datax
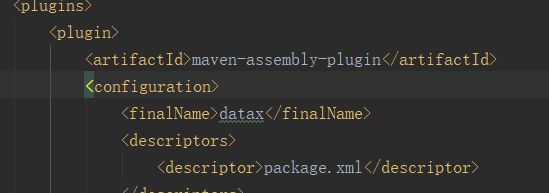
那么,到pom.xml的路径下找target/datax/*
然后,看package.xml,outputDirectory标签里还是datax,接着找 target/datax/datax/*

directory指定了源文件的相对地址,includes 标签里配置的是把所有东西都搞出来。
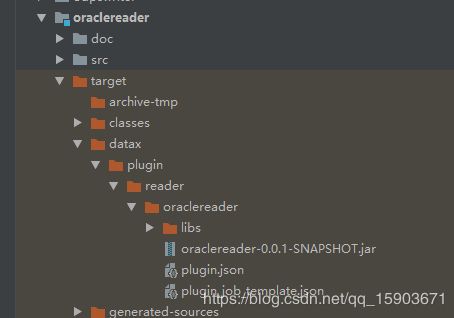
看一下oraclereader的目录结构,directory标签指定的oraclereader/target/datax路径下其实就是一个plugin文件夹。也就是说这个plugin文件夹打包时会被拷贝到 target/datax/datax/这个路径下面,当然plugin里面的东西会一并打包进来。
其实所有的插件都是统一将plugin路径下的所有文件拷贝到target/datax/datax/路径下,这样target/datax/datax下面的plugin路径下就会保存所有的插件,框架可以通过遍历的plugin路径的方式查找插件。

我们来看一下跟pom.xml同目录的target目录的结构。plugin里找到oraclereader和hdfswriter,没有其他插件,目的达成。
二、配置json控制文件
2.1 查看json模板:
依据userGuid.md中的说明。使用 python datax.py -r {YOUR_READER} -w {YOUR_WRITER} 指令查看一下json文件模板。
注意:dataX官方提供的源码和工具在windows上查看模板会报错,博主对源码进行了修改使其支持windows。
如果你没下载源码也没关系,datax.py是脚本文件,打开编辑,修改下方内容即可:
readerTemplatePath = "%s/plugin/reader/%s/plugin_job_template.json" % (DATAX_HOME,reader)
writerTemplatePath = "%s/plugin/writer/%s/plugin_job_template.json" % (DATAX_HOME,writer)
if isWindows():
readerTemplatePath = "%s\\plugin\\reader\\%s\\plugin_job_template.json" % (DATAX_HOME,reader)
writerTemplatePath = "%s\\plugin\\writer\\%s\\plugin_job_template.json" % (DATAX_HOME,writer)
下面三行是添上去的,在windows上查看模板要用windows认识的地址间隔符。
为什么要查看模板?因为datax的结构是统一的框架+横向扩展的reader/writer插件。不同的reader和writer需要不同的配置信息,比如oracle需要驱动+ip+port+user+passwd,而本地csv文件需要地址、是否有表头等信息。这样导致json文件中的reader和writer在使用不同的数据源和目的库的情况下json的参数是不同的。
2.2 配置自己的json模板
。。。
三、测试
1. datax的执行是使用python脚本的,如果是windows下学习测试的话可参考我的博文安装datax指定的2.6版本python
https://blog.csdn.net/qq_15903671/article/details/88792048
2. json文件准备好: 依据自己保留了哪些reader和writer,参考2.1查看json模板并修改成自己的配置
3. 依据userGuid.md操作说明,cmd使用指令 python datax.py ./***yourjson***.json