python高级用法及注意事项
让你的程序运行的更快
下面列出一些常见简单的优化策略:
- 有选择的消除属性访问:每次使用句点操作符(.)来访问属性时都会带来开销。在底层,这会触发调用特殊方法,比如 getattribute() 和 getattr(),而调用这些方法常常会导致字典查询操作。
- 理解变量所处的位置:通常来说,访问局部变量要比全局变量要快。对于需要频繁访问的名称,想要提高运行速度,可以通过让这些名称尽可能成为局部变量来达成。
- 避免不必要的抽象:任何时候当使用额外的处理层比如装饰器、属性或者描述符来包装代码时,代码的速度就会变慢。
- 使用内建的容器:内建的数据类型处理速度一般要比自己写的快的多。
- 避免产生不必要的数据结构或者拷贝操作
一、重要用法
1、bfs-宽度优先搜索:
除了用dqueue,另一种就是用list代替队列,此时set代替list效率会提高
https://blog.csdn.net/qq_19446965/article/details/102739705
2、set转成tuple可以序列化
sets = set()
tuples = tuple(sets)3、set的高效操作
set.intersection(set1, set2 ... etc)
https://www.runoob.com/python3/ref-set-intersection.html
4、python的排序模块bisect
https://www.cnblogs.com/skydesign/archive/2011/09/02/2163592.html
5、字符转统计
str.count(sub, start= 0,end=len(string))
https://www.runoob.com/python/att-string-count.html
另一种是,collections.Counter(),返回的是dict
https://blog.csdn.net/u014755493/article/details/69812244
6、将多维数据转为一维数组
array = [[3, 4, 5], [4, 22, 44, 6], [7, 8]]
res = []
[res.extend(m) for m in array]
print(res) # [3, 4, 5, 4, 22, 44, 6, 7, 8]itertools.chain方法:
print(list(itertools.chain.from_iterable(array)))
# [3, 4, 5, 4, 22, 44, 6, 7, 8]
# or
print(list(itertools.chain(*array)))
# [3, 4, 5, 4, 22, 44, 6, 7, 8]operator方法:
import operator
from functools import reduce
array = [[3, 4, 5], [4, 22, 44, 6], [7, 8]]
print(reduce(operator.add, array))
# [3, 4, 5, 4, 22, 44, 6, 7, 8]7、设置字典的默认类型
避免了if判断:collections.defaultdict(set/list/int)
from collections import defaultdict
d = defaultdict(list)
d['a'].append(1)
d['a'].append(1)
print(d)
# out: defaultdict(list, {'a': [1, 1]})
s = defaultdict(set)
s['a'].add(1)
s['a'].add(1)
s['a'].add(2)
print(s)
# out: defaultdict(set, {'a': {1, 2}})https://www.jianshu.com/p/26df28b3bfc8
让字典保持有序 collections.OrderedDict
使用OrderedDict 创建的dict 会严格按照初始添加的顺序进行。其内部维护了一个双向链表,它会根据元素加入的顺序来排列键的位置。因此OrderedDict的大小是普通字典的2倍多。
注意:3.6版本的dict()函数使得结果不再无序
8、Python zip(*) 和itertools.zip_longest()
https://www.runoob.com/python/python-func-zip.html
参数前面加上* 号 ,意味着参数的个数不止一个,另外带一个星号(*)参数的函数传入的参数存储为一个元组(tuple)
a = ["abchh", "abcsdf", "abdshf"]
for b in zip(*a):
print(b)
>>>
('a', 'a', 'a')
('b', 'b', 'b')
('c', 'c', 'd')
('h', 's', 's')
('h', 'd', 'h')itertools.zip_longest(v1, v2, fillvalue=0)使用最长的迭代器来作为返回值的长度,并且可以使用fillvalue来制定那些缺失值的默。
- 当参数长度一致时和zip一样。
- 当参数长度不一时,zip和较短的保持一致,itertools.zip_longest()和较长的保持一致。
https://blog.csdn.net/sinat_28576553/article/details/85136614
import itertools
list1 = ["A","B","C","D","E"] #len = 5
list2 = ["a", "b", "c", "d","e"] #len = 5
list3 = [1, 2, 3, 4] #len = 4
print(list(itertools.zip_longest(list1, list3)))
#[('A', 1), ('B', 2), ('C', 3), ('D', 4), ('E', None)]
print(list(zip(list1, list3)))
#[('A', 1), ('B', 2), ('C', 3), ('D', 4)]9、 检查你的Python版本
from sys import version_info
if version_info.major != 2 and version_info.minor != 7:
raise Exception('请使用Python 2.7来完成此项目')指定python版本:
#!python2 //由python2解释器运行
#!python3 //由python3解释器运行10、队列大小的设定:
self.history = deque(maxlen=2)
11、判断是否包含负数
symbols = np.concatenate(X)
if (symbols < 0).any(): # contains negative integers
return False12、判断差值,接着上文
symbols.sort()
np.all(np.diff(symbols) <= 1)首先看diff含义:离散差值
import numpy as np
a=np.array([1, 6, 7, 8, 12])
diff_x1 = np.diff(a)
print(diff_x1)
# [5 1 1 4]
# [6-1,7-6,8-7,12-8]所以上述的含义是判断symbols中连续元素的差值是都小于等于1
13、string.endswith
string.endswith(str, beg=[0,end=len(string)])
string[beg:end].endswith(str)- string: 被检测的字符串
- str: 指定的字符或者子字符串(可以使用元组,会逐一匹配)
- beg: 设置字符串检测的起始位置(可选,从左数起)
- end: 设置字符串检测的结束位置(可选,从左数起)
如果存在参数 beg 和 end,则在指定范围内检查,否则在整个字符串中检查
14、Python 缓存机制与 functools.lru_cache
http://kuanghy.github.io/2016/04/20/python-cache
在 Python 的 3.2 版本中,引入了一个非常优雅的缓存机制,即 functool 模块中的 lru_cache 装饰器,可以直接将函数或类方法的结果缓存住,后续调用则直接返回缓存的结果。lru_cache 原型如下:
@functools.lru_cache(maxsize=None, typed=False)
使用 functools 模块的 lur_cache 装饰器,可以缓存最多 maxsize 个此函数的调用结果,从而提高程序执行的效率,特别适合于耗时的函数。参数 maxsize 为最多缓存的次数,如果为 None,则无限制,设置为 2 的幂 时,性能最佳;如果 typed=True(注意,在 functools32 中没有此参数),则不同参数类型的调用将分别缓存,例如 f(3) 和 f(3.0)。
使用前提:
- 同样的函数参数一定得到同样的结果
- 函数执行时间很长,且要多次执行
本质:函数调用的参数 ==> 返回值
适用场景:单机上需要空间换时间的地方,可以用缓存来将计算编程快速查询
注意:leetcode好多的题用DFS不能通过,增添了缓存机制后,能顺利通过,简单!
例:
from functools import lru_cache
@lru_cache(None)
def add(x, y):
print("calculating: %s + %s" % (x, y))
return x + y
print(add(1, 2))
print(add(1, 2))
print(add(2, 3))输出结果:
calculating: 1 + 2
3
3
calculating: 2 + 3
5从结果可以看出,当第二次调用 add(1, 2) 时,并没有真正执行函数体,而是直接返回缓存的结果。
https://www.cnblogs.com/JerryZao/p/9551515.html
缺点:
- 函数参数要可序列化(set,tuple,int,等),不支持list,dict等
- 不支持缓存过期,key无法过期,失效
- 不支持清除操作
- 不支持分布式,是一个单机缓存
15.python字符串中连续相同字符个数
import itertools
res = [(k, len(list(g))) for k, g in itertools.groupby('TTFTTTFFFFTFFTT')]
res:[('T', 2), ('F', 1), ('T', 3), ('F', 4), ('T', 1), ('F', 2), ('T', 2))]Python的内建模块itertools提供了非常有用的用于操作迭代对象的函数。
https://blog.csdn.net/qq_19446965/article/details/106866531
16、使用多个分隔符分隔字符串
python基础 - 正则表达式(re模块)
https://blog.csdn.net/qq_19446965/article/details/107051655
17、heapq.nsmallest 和 heapq.nlargest
先说说import heapq:
- heapify:对序列进行堆排序,
- heappush:在堆序列中添加值
- heappop:删除最小值并返回
- heappushpop:添加并删除堆中最小值且返回,添加之后删除
- heapreplace:添加并删除队中最小值且返回,删除之后添加
heapq(Python内置的模块)
__all__ = ['heappush', 'heappop', 'heapify', 'heapreplace', 'merge', 'nlargest', 'nsmallest', 'heappushpop']
heapq.nlargest(n, iterable, key=None)
heapq.nsmallest(n, iterable, key=None)
n:查找个数 iterable:可迭代对象 key:同sorted
例:按照 num1和num2的数对和进行排序
heapq.nsmallest(k, itertools.product(nums1, nums2), key=sum)heapq.merge(list1,list2)
合并list1和list2,还进行了排序
list1 = [1, 2, 3, 4, 5, 12]
set1 = {2, 3, 9, 23, 54}
s = list(merge(list1,set1))
print(s) #[1, 2, 2, 3, 3, 4, 5, 9, 12, 54, 23]18、list比较
list_x = [124, 32525, 2141, 354]
list_y = [114, 231, 341, 153]
print(list_x > list_y) # True
print(list_x < list_y) # Flase
print((list_x > list_y) - (list_x < list_y)) # 1
list_x = [124, 231, 341, 153]
list_y = [124, 231, 341, 153]
print((list_x > list_y) - (list_x < list_y)) # 0
list_x = [124, 231, 341, 153]
list_y = [134, 231, 341, 153]
print((list_x > list_y) - (list_x < list_y)) # -119、max与map结合应用
versions = ["192.168.1.1", "192.168.1.2", "292.168.1.1", "192.178.1.1"]
res = max(versions, key=lambda x: list(map(int, x.split('.'))))
print(res) # 292.168.1.120、四舍五入
https://www.tr0y.wang/2019/04/08/Python%E5%9B%9B%E8%88%8D%E4%BA%94%E5%85%A5/index.html
import decimal
decimal.getcontext().rounding = decimal.ROUND_HALF_UP
a = decimal.Decimal('2.135').quantize(decimal.Decimal('0.00'))
b = decimal.Decimal('2.145').quantize(decimal.Decimal('0.00'), rounding=decimal.ROUND_HALF_UP)
print(a, b) # 2.14 2.1521、set集合的各种运算:
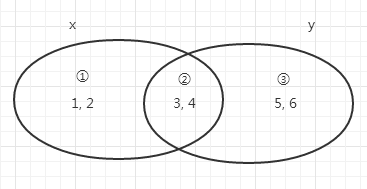
集合 x <==> ① + ②
集合 y <==> ② + ③
交集 x&6 <==> ② x.intersection(y)
并集 x|y <==> ① + ② + ③ x.union(y)
差集 x-y <==> ① x.difference(y)
差集 y-x <==> ③ y.difference(x)
对称差集 x^y == y^x <==> ① + ③ x.symmetric_difference(y) = y.symmetric_difference(x)
22、.format的应用
a = list("HELLO")
print("{0[0]}, {0[2]}".format(a)) # H La = {"c": "foo", "d": "bar"}
print("{c} {d}".format(**a)) # foo bar
a = "foo", "bar"
print("{0} {1}".format(*a)) # foo bar
a = ["foo", "bar"]
print("{0} {1}".format(*a)) # foo bar
a = {"foo", "bar"}
print("{0} {1}".format(*a)) # foo bar / bar foo --set无序22、*args and **kwargs
当定义函数的时候使用了*,意味着那些通过位置传递的参数将会被放在带有*前缀的变量中, 所以:
def one(*args):
print args # 1
one()
#()
one(1, 2, 3)
#(1, 2, 3)
def two(x, y, *args): # 2
print x, y, args
two('a', 'b', 'c')
#a b ('c',)第一个函数one只是简单地讲任何传递过来的位置参数全部打印出来而已,在代码#1处我们只是引用了函数内的变量args, *args仅仅只是用在函数定义的时候用来表示位置参数应该存储在变量args里面。Python允许我们制定一些参数并且通过args捕获其他所有剩余的未被捕捉的位置参数,就像#2处所示的那样。
*操作符在函数被调用的时候也能使用。一个用*标志的变量意思是变量里面的内容需要被提取出来然后当做位置参数被使用。例:
def add(x, y):
return x + y
lst = [1,2]
add(lst[0], lst[1]) # 1
3
add(*lst) # 2
3#1处的代码和#2处的代码所做的事情其实是一样的,在#2处,python为我们所做的事其实也可以手动完成。这也不是什么坏事,*args要么是表示调用方法大的时候额外的参数可以从一个可迭代列表中取得,要么就是定义方法的时候标志这个方法能够接受任意的位置参数。
接下来提到的**会稍多更复杂一点,**代表着键值对的餐宿字典,和*所代表的意义相差无几,也很简单对不对:
def foo(**kwargs):
print kwargs
foo()
#{}
foo(x=1, y=2)
#{'y': 2, 'x': 1}注意点:参数arg、*args、**kwargs三个参数的位置必须是一定的。必须是(arg,*args,**kwargs)这个顺序,否则程序会报错。
dct = {'x': 1, 'y': 2}
def bar(x, y):
return x + y
bar(**dct)
#323、 Python Number 类型转换
- ord(x ) 将一个字符转换为它的整数值
- hex(x ) 将一个整数转换为一个十六进制字符串
- oct(x ) 将一个整数转换为一个八进制字符串
- bin(x ) 将一个整数转换为一个二进制字符串
num = "0011"
a = int(num, base=2) # 以二进制转换
print(a) # 3
num2 = "a"
b = int(num2, base=16) # 以16进制转换
print(b) # 1024、判断一个列表是否是其中的一个子集
Counter方法:
from collections import Counter
print(not Counter([1, 2]) - Counter([1])) # False
print(not Counter([1, 2]) - Counter([1, 2])) # True
print(not Counter([1, 2, 2]) - Counter([1, 2])) # False
print(not Counter([1, 2]) - Counter([1, 2, 2])) # Trueissubset方法:
set([1, 2, 2]).issubset([1, 2, 3]) # True还有:
set(one).intersection(set(two)) == set(one)
set(one) & (set(two)) == set(one) 这些都有个缺点,不能判断有重元素的子集问题。
25、Python os.walk() 方法
os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。
import os
for root, dirs, files in os.walk(".", topdown=False):
for name in files:
print(os.path.join(root, name))
for name in dirs:
print(os.path.join(root, name))- root 所指的是当前正在遍历的这个文件夹的本身的地址
- dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
- files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
https://www.runoob.com/python/os-walk.html
26、python 四位数整数补零
(1)数字前面补零
n = 123
n = "%04d" % n
print(n) # 0123
print(type(n)) # str(2) 字符串前面补零
s = "123"
s = s.zfill(5)
print(s) # 0012327、numpy.log1p() 函数
numpy.log1p() 函数返回 numpy.log(1+number),甚至当 number 的值接近零也能计算出准确结果。
28、Python中Numpy库中的np.sum(array,axis=0,1,2...)
https://blog.csdn.net/qq_19446965/article/details/106866460
29、导入数据
https://blog.csdn.net/qq_19446965/article/details/106882889
30、urllib、urllib2、urllib3用法及区别
python2.X 有这些库名可用: urllib, urllib2, urllib3, requests
python3.X 有这些库名可用: urllib, urllib3, requests
两者都有的urllib3和requests, 它们不是标准库. urllib3 提供线程安全连接池和文件post支持,与urllib及urllib2的关系不大. requests 自称HTTP for Humans, 使用更简洁方便
(1)对于python2.X:
urllib和urllib2的主要区别:
- urllib2可以接受Request对象为URL设置头信息,修改用户代理,设置cookie等, urllib只能接受一个普通的URL.
- urllib提供一些比较原始基础的方法而urllib2没有这些, 比如 urlencode
import urllib
with urllib.urlopen('https://mp.csdn.net/console/editor/html/104070046') as f:
print(f.read(300))(2)对于python3.X:
这里urllib成了一个包, 此包分成了几个模块,
- urllib.request 用于打开和读取URL,
- urllib.error 用于处理前面request引起的异常,
- urllib.parse 用于解析URL,
- urllib.robotparser用于解析robots.txt文件
python2.X 中的 urllib.urlopen()被废弃, urllib2.urlopen()相当于python3.X中的urllib.request.urlopen()
import urllib.request
with urllib.request.urlopen('https://mp.csdn.net/console/editor/html/104070046') as f:
print(f.read(300))其余区别详见:
- https://blog.csdn.net/permike/article/details/52437492
- https://www.cnblogs.com/onefine/p/10499342.html
31、__slots__魔法
在Python中,每个类都有实例属性。默认情况下Python⽤⼀个字典来保存⼀个对象的实例属性。这⾮常有⽤,因为它允许我们在运⾏时去设置任意的新属性。然⽽,对于有着已知属性的⼩类来说,它可能是个瓶颈。这个字典浪费了很多内存。
Python不能在对象创建时直接分配⼀个固定量的内存来保存所有的属性。因此如果你创建许多对象(我指的是成千上万个),它会消耗掉很多内存。不过还是有⼀个⽅法来规避这个问题。这个⽅法需要使⽤__slots__来告诉Python不要使⽤字典,⽽且只给⼀个固定集合的属性分配空间。使⽤ __slots__:
class MyClass(object):
__slots__ = ['name', 'identifier']
def __init__(self, name, identifier):
self.name = name
self.identifier = identifier
self.set_up()__slots__为你的内存减轻负担。通过这个技巧,内存占⽤率⼏乎40%~50%的减少。
32、namedtuple和enum
https://blog.csdn.net/qq_19446965/article/details/106866330
33、生成器(Generators)和协程
https://blog.csdn.net/qq_19446965/article/details/106845837
34、生成随机数组
https://blog.csdn.net/qq_19446965/article/details/106752111
35、matplotlib和networkx 绘图
matplotlib:https://blog.csdn.net/qq_19446965/article/details/106745837
networkx:https://blog.csdn.net/qq_19446965/article/details/106744268
36、 处理excel实例
https://blog.csdn.net/qq_19446965/article/details/106610855
37、读写XML文档(lxml方式)
https://blog.csdn.net/qq_19446965/article/details/106610710
38、装饰器总结
https://blog.csdn.net/qq_19446965/article/details/105182259
39、获取文件夹和文件的路径
https://blog.csdn.net/qq_19446965/article/details/104567692
40、enumerate也接受⼀些可选参数
my_list = ['apple', 'banana', 'grapes', 'pear']
for c, value in enumerate(my_list, 1):
print(c, value)
# 输出:
(1, 'apple')
(2, 'banana')
(3, 'grapes')
(4, 'pear')41、时间转换
(1)本地时间的区别
import time
from datetime import datetime
time_at = time.time()
print(time.localtime(time_at)) # time.struct_time(tm_year=2020, tm_mon=6, tm_mday=20, tm_hour=20, tm_min=19, tm_sec=8, tm_wday=5, tm_yday=172, tm_isdst=0)
print(datetime.utcfromtimestamp(time_at).strftime('%Y-%m-%d %H:%M:%S')) # 2020-06-20 12:19:08
print(datetime.fromtimestamp(time_at).strftime('%Y-%m-%d %H:%M:%S')) # 2020-06-20 20:19:08(2)时间戳转换成date
import time
import pandas as pd
from datetime import datetime
def time_to_datetime(time_at):
return datetime.fromtimestamp(time_at).strftime('%Y-%m-%d %H:%M:%S')
print(type(time.time())) #
print(time.time()) # 1592655986.43079
str_time = time_to_datetime(time.time())
print(type(str_time)) #
print(str_time) # 2020-06-20 20:26:26
date_time = pd.to_datetime(str_time)
print(type(date_time)) #
print(date_time) # 2020-06-20 20:26:26 43、Python如何读取、拆分大文件
import pandas as pd
pd.read_table("data/ex1.csv", chunksize=10000, header=None, sep=',')
for chunk in data:
print(chunk)44、re.match和re.search
a = "back.text"
b = "text.back"
pattern = "back"
if re.match(pattern, a):
print(1)
if re.match(pattern, b):
print(2)
if re.search(pattern, a):
print(3)
if re.search(pattern, b):
print(4)
# 1 3 445、字典中按照键的顺序输出
dict_1 = {"c": 45254, "a": 333, "b": 908}
for key in dict_1:
print(key, dict_1[key])
>>>
c 45254
a 333
b 908
for key in sorted(dict_1):
print(key, dict_1[key])
>>>
a 333
b 908
c 4525446、python 保留n位小数
以保留2位小数为例 a = 21.2345:
1、round
print(round(a, 2)) # 21.23 flaot 2、%nf
print('%.2f' % a) # 21.23 str # 3、'{:.%2f}'.format()
print('{:.2f}'.format(a)) # 21.23 str47、字符串格式化千分位逗号分隔
print("{:,}".format(99999999)) # 99,999,99948、删除某目录下的所有文件
import shutil
shutil.rmtree(r'G:\test')会连带目录一起删掉,如果想不删目录的话,需要自己写代码来递归删除文件夹中的内容,或者还是用这个函数,但是删完以后再新建文件夹。
import shutil
shutil.rmtree('要清空的文件夹名')
os.mkdir('要清空的文件夹名')
其他方法:
- os.remove() 方法用于删除指定路径的文件。如果指定的路径是一个目录,将抛出OSError。
- os.rmdir() 方法用于删除指定路径的目录。仅当这文件夹是空的才可以, 否则, 抛出OSError。
- os.removedirs() 方法用于递归删除目录。像rmdir(), 如果子文件夹成功删除, removedirs()才尝试它们的父文件夹,直到抛出一个error(它基本上被忽略,因为它一般意味着你文件夹不为空)。
- os.unlink() 方法用于删除文件,如果文件是一个目录则返回一个错误。
递归删除目录和文件的方法(类似DOS命令DeleteTree):
import os
for root, dirs, files in os.walk(top, topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))如果想把一个文件从一个文件夹移动到另一个文件夹,并同时重命名,用shutil也很简单:
shutil.move('原文件夹/原文件名','目标文件夹/目标文件名') 49、重组 mat (or array).reshape(c, -1)
特殊用法:mat (or array).reshape(c, -1);
必须是矩阵格式或者数组格式,才能使用 .reshape(c, -1) 函数, 表示将此矩阵或者数组重组,以 c行d列的形式表示(-1的作用就在此,自动计算d:d=数组或者矩阵里面所有的元素个数/c, d必须是整数,不然报错)
50、pickle存取文件
import pickle
in_data = [1, 3, 5, 7, 9]
output_file = open("test.pkl", 'wb')
pickle.dump(in_data, output_file)
output_file.close()
input_file = open("test.pkl", 'rb')
out_data = pickle.load(input_file)
print(out_data) # [1, 3, 5, 7, 9]
# 使用上下文管理器 with:
with open('test.pkl', 'rb') as input_file:
pickled_data = pickle.load(input_file)
print(out_data)51、如何查看安装python和包的版本
https://blog.csdn.net/qq_19446965/article/details/106979433
52、pip 安装与使用
https://blog.csdn.net/qq_19446965/article/details/106978982
53、Numpy和Pandas使用
Numpy:https://blog.csdn.net/qq_19446965/article/details/106961131
Pandas:https://blog.csdn.net/qq_19446965/article/details/106963047
54、python 配置虚拟环境,多版本管理
https://blog.csdn.net/qq_19446965/article/details/106981079
55、切片操作 slice
items = [0, 1, 2, 3, 4, 5, 6]
print(items[2:4])
# Out[24]: [2, 3]
a = slice(2, 4)
print(items[a])
# Out[25]: [2, 3]对迭代器做切片操作 itertools.islice
对生成切做切片操作,普通的切片不能用,可以使用itertools.islice()函数
import itertools
def count(n):
while True:
yield n
n += 1
c = count(0)
print(c)
# Out[6]:
for x in itertools.islice(c, 10, 20):
print(x)
# 10
# ...
# 19 56、将多个映射合并为单个映射 Chainmap
问题的背景是我们有多个字典或者映射,想把它们合并成为一个单独的映射,有人说可以用update进行合并,这样做的问题就是新建了一个数据结构以致于当我们对原来的字典进行更改的时候不会同步。如果想建立一个同步的查询方法,可以使用ChainMap,python3 中使用。
from collections import ChainMap
a = {'x': 1, 'z': 3}
b = {'y': 2, 'z': 4}
c = ChainMap(a, b)
print(c)
# Out[5]: ChainMap({'z': 3, 'x': 1}, {'z': 4, 'y': 2})
print(c['x'])
print(c['y'])
print(c['z'])
c["z"] = 4
print(c)
# Out[12]: ChainMap({'z': 4, 'x': 1}, {'z': 4, 'y': 2})
c.pop('z')
print(c)
# Out[14]: ChainMap({'x': 1}, {'z': 4, 'y': 2})
del c["y"]
# ---------------------------------------------------------------------------
# KeyError: "Key not found in the first mapping: 'y'"57、文本过滤和清理str.translate
s = 'python\fis\tawesome\r\n'
print(s)
# Out[10]: 'python\x0cis\tawesome\r\n'
remap = {ord('\t'): '|', # 替换
ord('\f'): '|', # 替换
ord('\r'): None # 删除
}
a = s.translate(remap)
print(a)
# Out[22]: 'python|is|awesome\n'58、分数的计算 fractions.Fraction
from fractions import Fraction
a = Fraction(5, 4)
b = Fraction(7, 16)
c = a + b
print(c.numerator)
# Out[30]: 27
print(c.denominator)
# Out[31]: 1669、时间换算 datetime.timedelta
from datetime import timedelta
a = timedelta(days=2, hours=6)
b = timedelta(hours=4.5)
c = a + b
print(c.days)
# Out[36]: 2
print(c.seconds)
# Out[37]: 37800
print(c.seconds / 3600)
# Out[38]: 10.5
print(c.total_seconds() / 3600)
# Out[39]: 58.570、委托迭代 iter()方法
对自定义的容器对象,其内部持有一个列表丶元组或其他的可迭代对象,我们想让自己的新容器能够完成迭代操作。一般来说,我们所要做的就是定义一个__iter__()方法,将迭代请求委托到对象内部持有的容器上。
class Person:
def __init__(self, vaule):
self._value = vaule
self._children = []
def __repr__(self):
return 'Person({!r})'.format(self._value)
def __iter__(self):
return iter(self._children)
person = Person(30)
person._children = ["zhangSan", "liSi", "wangErMaZi"]
print(person)
# Out[38]: Person(30)
for p in person:
print(p)
# Out[39]: zhangSan
# Out[40]: liSi
# Out[41]: wangErMaZi71、反向迭代 reversed()
假如想要反向迭代序列中的元素,可以使用内建的 reversed()函数。也可以在自己的类中实现__reversed__()方法。具体实现类似于__iter__()方法。
a = [1, 2, ,3 ,4]
for x in reversed(a):
print(x)72、 迭代所有可能的组合或排列
- itertools.permutations 接受一个元素集合,将其中所有的元素重排列为所有可能的情况,并以元组序列的形式返回。
- itertools.combinations 不考虑元素间的实际顺序,同时已经排列过的元素将从从可能的候选元素中移除。若想解除这一限制,可用combinations_with_replacement。
from itertools import permutations
items = ['a', 'b', 'c']
for p in permutations(items):
print(p)
# ('a', 'b', 'c')
# ('a', 'c', 'b')
# ('b', 'a', 'c')
# ('b', 'c', 'a')
# ('c', 'a', 'b')
# ('c', 'b', 'a')
from itertools import combinations
for c in combinations(items, 2):
print(c)
# ('a', 'b')
# ('a', 'c')
# ('b', 'c')
from itertools import combinations_with_replacement
for c in combinations_with_replacement(items, 2):
print(c)
# ('a', 'a')
# ('a', 'b')
# ('a', 'c')
# ('b', 'b')
# ('b', 'c')
# ('c', 'c')73、在类中定义多个构造函数
要定义一个含有多个构造函数的类,应该使用类方法。
import time
class Date:
# Primary constructor
def __init__(self, year, month, day):
self.year = year
self.month = month
self.day = day
# Alternate constructor
@classmethod
def today(cls):
t = time.localtime()
return cls(t.tm_year, t.tm_mon, t.tm_mday)
b = Date.today()
a = Date(2012, 12, 32)
类方法的一个关键特性就是把类作为其接收的第一个参数(cls),类方法中会用到这个类来创建并返回最终的实例。
74、添加日志记录
给程序简单的添加日志功能,最简单的方法就是使用 logging 模块了。 logging 的调用 (critical()、error()、warning()、info()、debug())分别代表着不同的严重级别,以降序排列。basicConfig()的 level参数是一个过滤器,所有等级低于此设定的消息都会被忽略掉。
import logging
def main():
logging.basicConfig(filename='app.log', level=logging.ERROR)
hostname = 'www.python.org'
item = 'spam'
filename = 'data.csv'
mode = 'r'
logging.critical('Host %s unknown', hostname)
logging.error("Couldn't find %r", item)
logging.warning('Feature is deprecated')
logging.info('Opening file %r, mode=%r', filename, mode)
logging.debug('Got here')
if __name__ == '__main__':
main()
输出 app.log:
![]()
75、python - 协程异步IO(asyncio)
https://blog.csdn.net/qq_19446965/article/details/107301416
76、python - 并发和多线程
https://blog.csdn.net/qq_19446965/article/details/107307062
77、创建自定义的异常
创建自定义的异常是非常简单的,只要将它们定义成继承自Exception 的类即可(也可以继承自其他已有的异常类型,如果这么做更有道理的话)。自定义的类应该总是继承自内建的Exception类,或者继承自一些本地定义的基类,而这个基类本身又是继承自Exception 的。虽然所有的异常也都继承自 BaseException,但不应该将它作为基类来产生新的异常。BaseException 是预留给系统退出异常的,比如 KeyboardInterrupt。因此捕获这些异常并不适用于它们本来的用途。
class NetworkError(Exception):
pass
class HostnameError(NetworkError):
pass
# when used
try:
msg = s.s.recv()
except HostnameError as e:
...如果打算定义一个新的异常并且改写 Exception 的 init()方法,请确保总是用所有传递过来的参数调用 Exception.init()。
class CustomError(Exception):
def __init__(self, message, status):
super().__init__(message, status)
self.message = message
self.status = status
二、python容易被忽略的问题
1、int()强制转换浮点数
在int()的强制转换浮点数时候,不管是正数还是负数,只取整数部分。
print(int(6.235)) # 6
print(int(-6.235)) # -6注意:这里不是向上或者向下取整,也不是四舍五入。
2、注意操作的返回值
a = print("python")
print(a) # None
list_1 = [1,2,3]
list_2 = [4,5,6]
print(list_1.extend(list_2)) # None
print(list_1) # [1, 2, 3, 4, 5, 6]
list_3 = [1,6,5,8,7,9,4,1,3]
new_list = list_3.sort()
print(new_list) # None
print(list_3) # [1, 1, 3, 4, 5, 6, 7, 8, 9]
list_4 = [1, 6, 5, 8, 7, 9, 4, 1, 3]
new_list = sorted(list_4)
print(new_list) # # [1, 1, 3, 4, 5, 6, 7, 8, 9]
print(list_4) # 不变[1, 6, 5, 8, 7, 9, 4, 1, 3]3、关联顺序
val x = sc.parallelize(List((1, "apple"), (2, "banana"), (3, "orange"), (4, "kiwi")), 2)
val y = sc.parallelize(List((5, "computer"), (1, "laptop"), (1, "desktop"), (4, "iPad")), 2)val x = sc.parallelize(List((1, "apple"), (2, "banana"), (3, "orange"), (4, "kiwi")), 2)
val y = sc.parallelize(List((5, "computer"), (1, "laptop"), (1, "desktop"), (4, "iPad")), 2)在这个里面x有的键y是可能没有的。
x.cogroup(y).collect()
可以从结果里看到,x有key为2,而y没有,则cogroup之后,y那边的ArrayBuffer是空。
res23: Array[(Int, (Iterable[String], Iterable[String]))] = Array(
(4,(ArrayBuffer(kiwi),ArrayBuffer(iPad))),
(2,(ArrayBuffer(banana),ArrayBuffer())),
(3,(ArrayBuffer(orange),ArrayBuffer())),
(1,(ArrayBuffer(apple),ArrayBuffer(laptop, desktop))),
(5,(ArrayBuffer(),ArrayBuffer(computer))))4、不同版本的取整不同
数字的处理
- python2的取整方式:print(,,, , )
| 3/2 | -3/2 | int(-3/2) | float(-3)/2 | int(float(-3)/2) | |
| python2 | 1 | -2 | -2 | -1.5 | -1 |
| python3 | 1.5 | -1.5 | -1 | -1.5 | -1 |
为什么python中7/-3等于-3,而c中等于-2?
python的整数除法是 round down的,而C的整数除法是truncation toward zero。
类似的还有 %, python中 7%-3 == -2,而C中7%-3 == 1
5、字符串连接效率
https://zhuanlan.zhihu.com/p/38632822
(1)加号连接,
r = a + b(2)使用%操作符
r = '%s%s' % (a, b)(3) 使用format方法
r = '{}{}'.format(a, b)(4) 方法4:使用f-string
r = f'{a}{b}'(5)使用str.join()方法
r = ''.join([a, b])连接少量字符串时
使用加号连接符在性能和可读性上都是明智的,如果对可读性有更高的要求,并且使用的Python 3.6以上版本,f-string也是一个非常好的选择,例如下面这种情况,f-string的可读性显然比加号连接好得多。
a = f'姓名:{name} 年龄:{age} 性别:{gender}'
b = '姓名:' + name + '年龄:' + age + '性别:' + gender连接大量字符串时
join和f-string都是性能最好的选择,选择时依然取决于你使用的Python版本以及对可读性的要求,f-string在连接大量字符串时可读性并不一定好。切记不要使用加号连接,尤其是在for循环中。
6、Python的作用域
Python的作用域一共有4种,分别是:
· L (Local) 局部作用域
· E (Enclosing) 闭包函数外的函数中
· G (Global) 全局作用域
· B (Built-in) 内置作用域(内置函数所在模块的范围)
以 L –> E –> G –>B 的规则查找,即:在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。
global关键字用来在函数或其他局部作用域中使用全局变量。但是如果不修改全局变量也可以不使用global关键字
nonlocal关键字用来在函数或其他作用域中使用外层(非全局)变量
修改变量:
如果需要在函数中修改全局变量,可以使用关键字global修饰变量名。
Python 2.x中没有关键字为在闭包中修改外部变量提供支持,在3.x中,关键字nonlocal可以做到这一点。
7、多版本Python共存,系统找到Python的原理
https://blog.csdn.net/qq_37954088/article/details/88897617
(1)Windows系统通过环境变量path来找到系统程序所在的位置
(2)当多个版本的Python同时存在时,在环境变量path中靠前的Python版本将被执行
(3)当安装多个版本时,添加环境变量后,打开cmd键入Python即可查看版本
8、python模块中的__all__属性
https://blog.csdn.net/sxingming/article/details/52903377
用于模块导入时限制,如:
from module import *
此时被导入模块若定义了__all__属性,则只有__all__内指定的属性、方法、类可被导入。
若没定义,则导入模块内的所有公有属性,方法和类 。
注意正常导入还是可以的,只是import *不可以
9、类变量和实例变量的访问
- 访问User对象u的name属性(实际上访问__name实例变量)
==》print(u._User__name)
- 动态地为类和对象添加类变量
Person.name =“aa"
print(person1.name)
- Python 允许通过对象访问类变量,但无法通过对象修改类变量的值。因为,通过对象修改类变量的值,不是在给“类变量赋值”,而是定义新的实例变量。
- 类中,实例变量和类变量可以同名,但是在这种情况下,使用类对象将无法调用类变量,因为它会首选实例变量。
10、python函数定义和调用顺序
在函数中调用其他函数,不需要定义在前,调用在后
def fun1(a, b):
c = fun2(a, b)
print(c)
def fun2(a, b):
c = a + b
return c而实际的函数调用执行操作,就一定要先定义后调用
def fun3(a, b):
c = a + b
print(c)
fun3(1, 2)
11、from __future__ import print_function用法
阅读代码的时候会看到下面语句:
from __future__ import print_function查阅了一些资料,这里mark一下常见的用法!
首先我们需要明白该句语句是python2的概念,那么python3对于python2就是future了,也就是说,在python2的环境下,超前使用python3的print函数。
举例如下:
在python2.x的环境是使用下面语句,则第二句语法检查通过,第三句语法检查失败
1 from __future__ import print_function
2 print('you are good')
3 print 'you are good'所以以后看到这个句子的时候,不用害怕,只是把下一个新版本的特性导入到当前版本!