SparkOnYarn专题四--cluster模式和client模式资源分配的详解
版权声明:本文为博主原创文章,未经博主允许不得转载!!
欢迎访问:https://blog.csdn.net/qq_21439395/article/details/80678493
交流QQ: 824203453
hadoop版本: hadoop 2.8.0 spark版本: spark2.2.0
1. yarn中容器的资源分配说明
在yarn集群中,对每一个请求的容器都有资源限定,在hadoop2.8.0的版本中,默认最小值是1024MB。
也有是说每一个容器的最小的内存资源是1g,然后每一个容器的资源,按照最小内存的倍数递增。
http://hadoop.apache.org/docs/r2.8.4/hadoop-yarn/hadoop-yarn-common/yarn-default.xml

| yarn.scheduler.minimum-allocation-mb |
1024 |
补充: 如果想要修改这个配置,修改yarn-site.xml文件,添加相关配置即可。
| |
下面所有的验证依然是基于默认的配置,也即1024M。
2. spark on yarn的资源分配
2.1. executor的资源配置
2.1.1. executor内存配置详解
yarn-client模式和yarn-cluster模式下,executor资源的分配都是一致的。
当spark任务提交到yarn集群运行时,可以通过--executor-memory 来指定每一个executor的内存分配。
但每一个executor真正申请的资源数量是:是由 –executor-memory 和spark.yarn.executor.memoryOverhead共同决定的。
spark.yarn.executor.memoryOverhead指的是:
每个executor要分配的堆外内存量。这个内存,可以解决诸如VM开销,其他本机开销等问题。
spark.yarn.executor.memoryOverhead的值,是参数分配值的0.1倍,最少384MB。
spark官方配置:
http://spark.apache.org/docs/2.2.0/running-on-yarn.html

每一个executor的资源分配,相关源码:
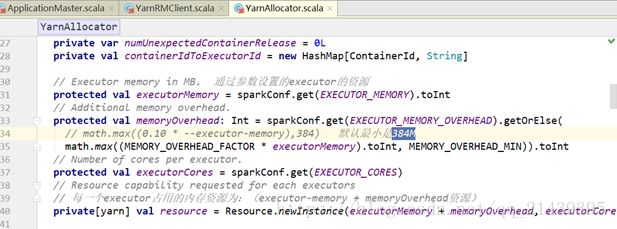
刚才说的是每一个executor指定的资源分配,但是在yarn中,executor都是运行在容器中的。根据上述yarn的容器资源分配,所有最终这个executor所在的容器的资源分配,一定是最小资源的整数倍。
示例:假定使用yarn的默认资源配置,1个容器分配的最小的资源数量是1g。
通过—executor-memory 1g
那么这个executor,
申请的资源是:1g + math.max(1024*0.1 ,384) = 1384Mb。
yarn容器占用的资源是: 1384向上取1024的整数倍。 也即2g。
如果yarn的最小内存分配是512M,那么这里yarn最终的资源是1.5g。
2.1.2. executor资源分配总结:
--executor-cores : executor 使用的核数。 默认值是一个
--executor-memory: 每一个executor使用的内存。 默认值是1g
--num-executors : executor的总的数量。 默认值是2个
2.2. cluster模式下的driver资源配置:
2.2.1. Driver/ApplicationMaster内存分配详解:
cluster模式下,driver程序和ApplicationMaster进程在一个容器中。
可以通过—driver-memory 来指定Driver所在yarn容器的内存大小,也就是ApplicationMaster所在容器的内存大小。
driver的内存分配方案,同executor的内存分配,也即指定内存加上堆外内存。
验证:
| spark-submit --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 500m --class org.apache.spark.examples.SparkPi /root/apps/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar 1000 |
ApplicationMaster:
2g + 384mb 向上取整 3g

每一个executor:指定的资源是500m + 384m 向上取整 1g

2.2.2. Driver(ApplicationMaster)的资源配置总结:
--driver-memory : 内存配置
--driver-cores: driver使用的cores数量。
2.3. Client模式下的资源分配:
2.3.1. ExecutorLauncher的内存分配详解:
client模式下,driver运行在客户端,ExecutorLauncher进程会占用一个容器。
在这种模式下,--driver-memory并不能作用于ExecutorLauncher的进程内存。
提交任务验证:
| spark-submit --master yarn --deploy-mode client --driver-memory 2g --executor-memory 500m --class org.apache.spark.examples.SparkPi /root/apps/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar 1000 |
第一个容器(ExecutorLauncher)资源占用情况:

实际上ApplicationMaster(executorLauncher)容器使用的资源是1g (512m +384m 向上取整)。
所以,在client模式下,driver-memory的配置没有生效。
那么实际ExecutorLauncher占用的资源是1g。准确的说是512M + 384M 再向上取整。
spark yarn参数配置:
http://spark.apache.org/docs/2.2.0/running-on-yarn.html

![]()
spark.yarn.am.memory 用于在client模式下,分配资源给ApplicationMaster(也就是ExecutorLauncher)。cluster模式下,使用的是spark.driver.memory配置。
所以在client模式下,通过--conf spark.yarn.am.memory=2g 指定ApplicationMaster的资源分配
| spark-submit --master yarn --deploy-mode client --conf spark.yarn.am.memory=2g --executor-memory 500m --class org.apache.spark.examples.SparkPi /root/apps/spark-2.2.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.2.0.jar 1000 |
当指定 am.memory=2g,yarn的容器的最小资源是默认值1024Mb
启动容器所占用的资源为:2g + 384m 取整 3g
![]()
2.3.2. ExecutorLauncher的资源配置总结:
--conf spark.yarn.am.memory=2g executorLauncher的内存配置
--conf spark.yarn.am.cores=3 executorLauncher的cores
版权声明:本文为博主原创文章,未经博主允许不得转载!!
欢迎访问:https://blog.csdn.net/qq_21439395/article/details/80678493
交流QQ: 824203453