C++和双检锁的风险
本篇文章介绍了为什么在c++11之前使用单例模式的双检测锁写法会出问题。以及在c++11中怎么解决的这些问题。第一篇论文主要讨论了为什么会出问题,第二篇论文讨论了怎么利用c++11来解决这些问题。如果有翻译不确定的地方放上了原文供大家参考。
文章目录
- C++ 和双检锁的风险(C++ and the Perils of Double-Checked Locking)
- 介绍
- 单例模式与多线程
- 双重检查锁定模式
- DCLP与指令排序
- C++11 中的双重检查锁定模式(Double-Checked Locking is Fixed In C++11)
- 什么是双重检查锁定?
- 用 C++11 获得与释放屏障
- 使用 Mintomic 屏障
- 使用 C++11 低级排序约束
- 使用 C++11 的顺序一致原子
- 使用 C++11 的数据相关性排序
- 使用 C++11 中的静态初始化器
- 译者总结
C++ 和双检锁的风险(C++ and the Perils of Double-Checked Locking)
介绍
在新闻组或网络上谷歌一下各种设计模式的名称,你一定会发现其中最常被提及的是Singleton。然而,尝试将Singleton付诸实践,你肯定会遇到一个重要的限制:按照传统的实现方式(正如我们在下面所解释的那样),Singleton并不是线程安全的。
为解决这一缺陷,我们已经做出了很多努力。其中最流行的方法是一种设计模式,即双重检查锁定模式(DCLP)。DHCP的设计是为了高效并且线程安全的去初始化一个共享变量(例如Singleton),但它有一个问题:不可靠。此外,在不对传统模式实现进行实质性修改的情况下,几乎没有任何可移植的方法在C++(或C语言)中使其可靠。更有趣的是,DCLP在单核处理器和多核处理器架构上会因为不同的原因而失败。
本文解释了为什么Singleton不是线程安全的,DCLP如何试图解决这个问题,为什么DCLP在单处理器和多处理器架构上都可能失败,以及为什么你不能(可移植地)对此做任何事情。同时,阐明了源代码中语句排序、序列点、编译器和硬件优化以及语句执行的实际顺序之间的关系。最后,本文对如何向Singleton(和类似的构造)添加线程安全性提出了一些建议,从而使生成的代码既可靠又高效。
单例模式与多线程
单例模式的传统实现是在第一次请求该对象时,使指针指向一个new出来的新对象。
// from the header file
class Singleton {
public:
static Singleton *instance();
private:
static Singleton *pInstance;
};
// from the implementation file
Singleton *Singleton::pInstance = 0;
Singleton *Singleton::instance() {
if (pInstance == 0) // 14
pInstance = new Singleton; // 15
return pInstance;
}
在单线程环境中,这通常可以正常工作,尽管中断可能会有问题。如果你在Singleton::instance中,接收到一个中断,并从处理程序中调用Singleton::instance,你可以看到你会如何陷入麻烦。不过,如果没有中断,这个实现能在单线程环境中工作的很好。
不幸的是,这种实现在多线程环境中不可靠。假设线程A进入实例函数,通过第14行执行(CSDN好像不支持显示代码行数,我用注释把行数打在对应代码后面了),然后被挂起。在挂起时,它刚刚确定pInstance为空,即尚未创建Singleton对象。
线程B现在进入instanceand执行第14行。它看到pInstance为空,所以它进入第15行,并为pInstance new一个单例对象,并使指针pInstance指向这个对象。然后它将pInstance返回给实例的调用方。
在稍后的某个时刻,线程A被允许继续运行,它做的第一件事是移动到第15行,在那里它new出另一个单例对象并使pInstance指向它。显然,这违反了单例对象的含义,因为现在有两个单例对象。从技术上讲,第11行是pInstance初始化的地方,但出于实际目的,是第15行使它指向我们希望它指向的地方,因此在本文的其余部分中,我们将把第15行视为pInstance初始化的地方。
使经典的单例实现线程安全是很容易的。在测试pInstance是否为空之前加锁:
Singletonton *Singleton::instance()
{
Lock lock; // acquire lock (params omitted for simplicity)
if (pInstance == 0)
pInstance = new Singleton;
return pInstance;
} // release lock (via lock destructor)
这种解决方案的缺点是代价可能很高昂。每次访问Singleton都需要获取一个锁,但实际上,我们只在初始化pInstance时需要一个锁。应该只在实例第一次被调用时才加锁。如果在程序运行过程中调用了n次实例,我们只需要在第一次调用实例时加锁。当你知道n-1次加锁是非必须的,那为什么还要为n次加锁买单呢?DCLP的设计是为了阻止你这么做。
双重检查锁定模式
DCLP的关键是观察到大多数对instance的调用会看到pInstance是非空的,因此甚至不会尝试初始化它。因此,DCLP在尝试获取锁之前会检测pInstance是否为空。只有当监测成功时(即pInstance还没有被初始化),才会获得锁,之后再进行一次测试,以确保pInstance仍然是空的(因此被称为双重检查锁)。第二个测试是必要的,因为,我们刚刚看到,有可能在pInstance第一次被监测到获得锁的这段时间里,另一个线程碰巧初始化了pInstance。
下面是典型的DCLP实现:
Singletonton *Singleton::instance()
{
if (pInstance == 0)
{
Lock lock; // 1st test
if (pInstance == 0) // 2nd test
pInstance = new Singleton;
}
return pInstance;
}
在定义DCLP的论文中讨论了一些实现问题(例如,volatile限定singleton指针的重要性(the importance of volatile-qualifying the singleton pointer),以及单独缓存对多处理器系统的影响,我们在下面讨论这两个问题;以及确保某些读写操作的原子性的必要性,我们在本文中不讨论这个问题。),但它们没有考虑一个更基本的问题,即确保DCLP期间执行的机器指令以可接受的顺序执行。我们在这里重点讨论的就是这个根本问题。
DCLP与指令排序
再次考虑初始化pInstance的代码:
pInstance = new Singleton;
这句代码发生了三件事:
1) 分配内存空间以保存单例对象。
2) 在分配的内存中构造一个单例对象。
3) 使pInstance指向分配的内存。
至关重要的是观察到编译器并不受限制地按照这个顺序执行这些步骤!特别是,编译器有时被允许交换步骤2和3。为什么他们会想这么做,这个问题我们稍后再谈。现在,让我们关注一下如果他们这样做会发生什么。
考虑下面的代码,其中我们将pInstance的初始化行扩展为上面提到的三个组成任务,并将步骤1(内存分配)和步骤3(pInstance分配)合并为步骤2(单例构造)之前的单个语句。我们的想法不是让一个人来写这段代码。相反,编译器可能会生成与此等效的代码,以响应人类编写的传统DCLP源代码(如前所示)。
Singletonton *Singleton::instance()
{
if (pInstance == 0)
{
Lock lock;
if (pInstance == 0)
{
pInstance = // Step 3
operator new(sizeof(Singleton)); // Step 1
new (pInstance) Singleton; // Step 2
}
}
return pInstance;
}
一般来说,这并不是对DCLP源代码的有效翻译,因为在步骤2中调用的Singleton构造函数可能会抛出一个异常,如果抛出异常,重要的是pInstance还没有被修改。一般来说,这就是为什么编译器不能将步骤3移到步骤2之上。然而,在某些条件下,这种转变是合法的。也许最简单的这种情况就是编译器可以证明Singleton的构造函数不能抛出异常,但这不是唯一的条件。一些可以抛出异常的构造函数也可以将其指令重新排序,这样就会出现这个问题。
鉴于上述原理,考虑以下事件的顺序:
- 线程A进入实例,执行pInstance的空值检测,获取锁,并执行了由步骤1(检空)和步骤3(地址赋值给指针)组成的语句,然后被挂起了。此时pInstance指针非空,在pInstance指针指向的内存中还没有构造任何Singleton对象。
- 线程B进入实例,检测到pInstance为非空,并将其返回给实例调用方。 然后调用者通过指针访问单例类时就会发现,还没有被构造出来(The caller then dereferences the pointer to access the Singleton that, oops, has not yet been constructed.)。
只有在步骤1和步骤2完成后再执行步骤3,DCLP才会正常工作,但在C或C++中没有办法表达这个约束条件。这就是DCLP的核心匕首:我们需要定义一个相对指令排序的约束,但我们的语言没有给我们表达这个约束的方法。
是的,C和C ++标准确实定义了序列点(sequence points),这些序列点定义了评估顺序的约束。 例如,C++标准第1.9节的第7段鼓励性地指出:
在执行序列中的某些指定点,称为序列点,之前评价的所有副作用都应完成,后续评价的副作用也应没有发生(At certain specified points in the execution sequence called sequence points, all side effects of previous evaluations shall be complete and no side effects of subsequent evaluations shall have taken place.)。
此外,两个标准都规定,每个语句的末尾都有一个序列点。所以看来,只要你注意你的语句顺序,一切都会落到实处。
哦,奥德修斯,不要让你自己被海妖的声音所诱惑,因为有很多麻烦等着你和你的伙伴们!(咳咳。。这句话真的是英文原文中存在的。)
这两个标准都以抽象机的可观察行为来定义正确的程序行为。但并不是这台机器的一切都可以观察到。例如,考虑这个简单的函数。
void Foo()
{
int x = 0, y = 0; // Statement 1
x = 5; // Statement 2
y = 10; // Statement 3
printf("%d, %d", x, y); // Statement 4
}
这个函数看起来很傻,但它可能是由Foo调用的其他函数内联的结果。
在C和C++中,标准都会保证Foo函数将会打印“5, 10”,所以我们知道这会发生。但是我们所知道的都是关于我们得到保证的程度。我们根本不知道语句1-3是否会被执行,事实上一个好的优化器会去掉它们。如果执行语句1-3,我们知道语句1将在语句2-4之前,并且假设对printf的调用没有内联并且结果进一步优化,我们知道语句4将在语句1-3之后,但是我们对语句2和3的相对顺序一无所知。编译器可以选择先执行语句2,先执行语句3,甚至并行执行它们,前提是硬件有某种方法可以做到这一点。这很有可能。现代处理器有很大的字长和几个执行单元。两个或更多的算术单位是常见的。(例如,Pentium 4有三个整数ALU,PowerPC的G4e有四个,安腾有六个。)他们的机器语言允许编译器生成在一个时钟周期内并行执行两个或更多指令的代码。
优化编译器仔细分析并重新排序代码,以便一次执行尽可能多的任务(在可观察行为的约束范围内)。在常规的串行代码中发现和利用这种并行性是重新安排代码和引入失序执行的最重要原因。但这不是唯一的原因。编译器(和链接器)还可以对指令重新排序,以避免从寄存器溢出数据,保持指令管道满,执行公共子表达式消除,并减小生成的可执行文件的大小。
当执行这些类型的优化时,C和C++的编译器和链接器只受语言标准所定义的抽象机上的可观察行为的约束,而且–这是重要的一点–这些抽象机是隐含的单线程的。作为语言,C和C++都没有线程,所以编译器在优化时不用担心线程程序被破坏。因此,他们有时这样做不应该让你感到惊讶。
译者注:借用这篇文章的前半部分表达了为什么c++单例双检测锁会出现问题,但是该文章接下来讨论的内容已被c++11实现,转到另一篇文章讨论怎么用c++11的方法合法的使用双检测锁。
C++11 中的双重检查锁定模式(Double-Checked Locking is Fixed In C++11)
英文版原版网址:https://preshing.com/20130930/double-checked-locking-is-fixed-in-cpp11/
双重检查锁定模式(DCLP)是无锁编程中有点臭名昭著的案例。直到2004年,在Java中还没有安全的方法来实现它。在C++11之前,没有安全的方法在可移植的C++中实现它。
随着这种模式因其在这些语言中暴露出的缺点而受到人们的关注,人们开始对它进行写作。2000年,一群高知名度的Java开发者聚集在一起,签署了一份题为 "双核锁定已被打破 "的宣言。2004年,Scott Meyers和Andrei Alexandrescu发表了一篇题为 "C++和双重检查锁定的危险 "的文章。这两篇论文都是很好的引子,说明了什么是DCLP,以及为什么,当时那些语言不足以实现它。
这些都是过去的事了。Java现在有一个修订的内存模型,对volatilekeyword有了新的语义,这使得安全地实现DCLP成为可能。同样,C++11也有一个闪亮的新内存模型和原子库,可以实现各种可移植的DCLP实现。C++11又启发了Mintomic,这是我今年早些时候发布的一个小库,它使得在一些旧的C/C++编译器上也可以实现DCLP。
在这篇文章中,我将重点介绍DCLP的C++实现。
什么是双重检查锁定?
假设你有一个实现了著名的Singleton模式的类,你想让它成为线程安全的类。显而易见的办法是通过加锁来保证相互的排他性。如果两个线程同时调用Singleton::getInstances,那么只有其中一个线程会创建这个单例。
Singleton *Singleton::getInstance()
{
Lock lock; // scope-based lock, released automatically when the function returns
if (m_instance == NULL)
{
m_instance = new Singleton;
}
return m_instance;
}
这是完全合法的方法,但是一旦单例被创建,实际上就不再需要锁了。锁不一定慢,但是在高并发的条件下,不具有很好的伸缩性。
双重检查锁定模式避免了在单例已经存在时候的锁定。不过如Meyers-Alexandrescu的论文所显示的,它并不简单。在那篇论文中,作者描述了几个有缺陷的用C++实现DCLP的尝试,并剖析了每种情况为什么是不安全的。最后,在第12页,他们给出了一个安全的实现,但是它依赖于非指定的,特定平台的内存屏障(memory barriers)。
Singleton *Singleton::getInstance()
{
Singleton *tmp = m_instance;
... // insert memory barrier if (tmp == NULL)
{
Lock lock;
tmp = m_instance;
if (tmp == NULL)
{
tmp = new Singleton;
... // insert memory barrier m_instance = tmp;
}
}
return tmp;
}
这里,我们可以发现双重检查锁定模式是由此得名的:在单例指针m_instance为NULL的时候,我们仅仅使用了一个锁,这个锁使偶然访问到该单例的第一组线程继续下去。而在锁的内部,m_instance被再次检查,这样就只有第一个线程可以创建这个单例了。
这与可运行的实现非常相近。只是在突出显示的几行漏掉了某种内存屏障。在作者写这篇论文的时候,还没有填补此项空白的轻便的C/C++函数。现在,C++11已经有了。
用 C++11 获得与释放屏障
你可以用获得与释放屏障安全的完成上述实现,这个问题我在之前的文章中已经详细解释过。然而,为了使这段代码真正具有可移植性,你还必须将m_instance包裹在一个C++11的原子类型中,并使用放松的原子操作来操作它。这是最终的代码,获取与释放屏障部分高亮了(译注:没法高亮,在后面打了注释)。
std::atomic Singleton::m_instance;
std::mutex Singleton::m_mutex;
Singleton *Singleton::getInstance()
{
Singleton *tmp = m_instance.load(std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_acquire); // 获取屏障
if (tmp == nullptr)
{
std::lock_guard lock(m_mutex);
tmp = m_instance.load(std::memory_order_relaxed);
if (tmp == nullptr)
{
tmp = new Singleton;
std::atomic_thread_fence(std::memory_order_release); // 释放屏障
m_instance.store(tmp, std::memory_order_relaxed);
}
}
return tmp;
}
即使是在多核系统上,它也可以可靠的工作,因为内存屏障在创建单例的线程与其后任何跳过这个锁的线程之间,创建了一种同步的关系。Singleton::m_instance充当警卫变量,而单例本身的内容充当有效载荷。
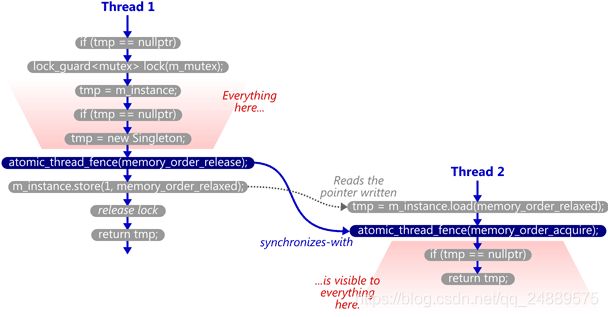
这就是那些有缺陷的DCLP实现所缺少的。在没有任何同步(synchronizes-with)关系的情况下,无法保证第一个线程执行的所有写入–特别是在Singleton构造函数中执行的写入–对第二个线程是可见的,即使m_instance指针本身是可见的! 第一个线程持有的锁也无济于事,因为第二个线程不需要获得任何锁,它可以并发运行(译注:还是上面说的CPU指令乱序执行的问题,第一个线程还没调用构造函数就已经将指针返回。第二个线程获取到的是空指针)。
如果你想更深入的理解这些屏障为什么以及如何使得DCLP具有可信赖性,在我以前的文章中有一些背景信息,就像这个博客早前的文章一样(译注:以前的文章:http://preshing.com/20130922/acquire-and-release-fences)。
使用 Mintomic 屏障
Mintomic是一个小型的C库,它提供了C++11的原子库的一个功能子集,包括获取和释放屏障,它可以在旧的编译器上工作。Mintomic依赖于C++11内存模型的假设–具体来说,就是空中存储(out-of-thin-air stores)–从技术上讲,老的编译器无法保证这一点,但这是我们在没有C++11的情况下所能做的最好的事情。 请记住,这些是我们多年来编写多线程C++代码的情况。空中存储经过一段时间的实践证明是不受欢迎的,好的编译器往往不会这么做。
这是一个使用Mintomic的获取和释放屏障的DCLP实现。基本上相当于前面的例子使用C++11的获取和释放屏障(译注:屏障加了注释)。
mint_atomicPtr_t Singleton::m_instance = {0};
mint_mutex_t Singleton::m_mutex;
Singleton *Singleton::getInstance()
{
Singleton *tmp = (Singleton *)mint_load_ptr_relaxed(&m_instance);
mint_thread_fence_acquire(); // get
if (tmp == NULL)
{
mint_mutex_lock(&m_mutex);
tmp = (Singleton *)mint_load_ptr_relaxed(&m_instance);
if (tmp == NULL)
{
tmp = new Singleton;
mint_thread_fence_release(); // release
mint_store_ptr_relaxed(&m_instance, tmp);
}
mint_mutex_unlock(&m_mutex);
}
return tmp;
}
使用 C++11 低级排序约束
C++11的获取和释放屏障可以正确地实现DCLP,应该可以在当今大多数多核设备上生成最优的机器代码(就像Mintomic一样),但它们并不被认为是非常流行的。在C++11中,实现同样效果的首选方法是使用具有低级排序约束的原子操作。正如我之前所展示的那样,写-释放可以与读-获取同步(译注:。。。看不懂,所以注释只加了1和2)。
std::atomic Singleton::m_instance;
std::mutex Singleton::m_mutex;
Singleton *Singleton::getInstance()
{
Singleton *tmp = m_instance.load(std::memory_order_acquire); // 1
if (tmp == nullptr)
{
std::lock_guard lock(m_mutex);
tmp = m_instance.load(std::memory_order_relaxed);
if (tmp == nullptr)
{
tmp = new Singleton;
m_instance.store(tmp, std::memory_order_release); // 2
}
}
return tmp;
}
从技术上讲,这种无锁同步的形式比使用独立屏障的形式不那么严格,上述操作只是为了防止自己周围的内存重排序,而独立屏障则是为了防止所有相邻操作周围的某些种类的内存重排序(the above operations are only meant to prevent memory reordering around themselves, as opposed to standalone fences, which are meant to prevent certain kinds of memory reordering around neighboring operations.)。尽管如此,在x86/64、ARMv6/v7和PowerPC架构上,两种形式的最佳机器代码是一样的。例如,在以前的一篇文章中,我展示了C++11低级排序约束如何在ARMv7编译器上发出dmb指令,这和你使用独立屏障的预期是一样的。
两种形式有可能产生不同机器代码的一个平台是Itanium。Itanium可以用一条CPU指令ld.acq实现C++11的load(memory_order_acquire),用st.rel实现store(tmp, memory_order_release)。我很想研究这些指令与独立屏障的性能差异,但没有机会接触到Itanium机器。
另一个这样的平台是最近推出的ARMv8架构。ARMv8提供了ldar和stlr指令,这些指令与Itanium的ld.acq和st.rel指令类似,只是它们还在stlrin指令和任何后续ldar之间执行更重的StoreLoad排序。事实上,ARMv8的新指令是为了实现C++11的SC原子论,接下来会介绍。
使用 C++11 的顺序一致原子
C++11提供了一种完全不同的方法来写无锁代码。(我们可以认为在某些特定的代码路径上DCLP是“无锁”的,因为并不是所有的线程都具有锁。)如果在所有原子库函数上,你忽略了可选的std::memory_order参数,那么默认值std::memory_order_seq_cst就会将所有的原子变量转变为顺序一致的(sequentially consistent) (SC)原子。通过SC原子,只要不存在数据竞争,整个算法就可以保证是顺序一致的。SC原子Java 5+中的volatile变量非常相似。
这里是使用SC原子的一个DCLP实现。如之前所有例子一样,一旦单例被创建,第二行高亮将与第一行同步。
std::atomic Singleton::m_instance;
std::mutex Singleton::m_mutex;
Singleton *Singleton::getInstance()
{
Singleton *tmp = m_instance.load(); // 1
if (tmp == nullptr)
{
std::lock_guard lock(m_mutex);
tmp = m_instance.load();
if (tmp == nullptr)
{
tmp = new Singleton;
m_instance.store(tmp); // 2
}
}
return tmp;
}
SC原子被认为可以使程序员更容易思考。其代价是生成的机器代码似乎比之前的例子效率要低。
使用 C++11 的数据相关性排序
懒的翻译。。。
In all of the above examples I’ve shown here, there’s a synchronizes-with relationship between the thread which creates the singleton and any subsequent thread which avoids the lock. The guard variable is the singleton pointer, and the payload is the contents of the singleton itself. In this case, the payload is considered a data dependency of the guard pointer.
It turns out that when working with data dependencies, a read-acquire operation, which all of the above examples use, is actually overkill! We can do better by performing a consume operation instead. Consume operations are cool because they eliminate one of thelwsyncinstructions on PowerPC, and one of thedmbinstructions on ARMv7. I’ll write more about data dependencies and consume operations in a future post.
使用 C++11 中的静态初始化器
一些读者已经知道这篇文章的重点:C ++ 11不需要您跳过以上任何一个步骤即可获得线程安全的单例。 您可以简单地使用静态初始化器。
[更新:当心! 正如Rober Baker在评论中指出的那样,该示例在Visual Studio 2012 SP4中不起作用。 它仅在完全符合C ++ 11标准这一部分的编译器中工作。
Singleton &Singleton::getInstance()
{
static Singleton instance;
return instance;
}
让我们回到6.7.6节查看C++11的标准:
如果控制(control)在变量初始化时并发进入声明,并发执行应等待初始化完成。
这要靠编译器来填充实现细节,而DCLP是显而易见的选择。我们不能保证编译器会使用DCLP,但恰好有些编译器(也许大多数)会使用。下面是GCC 4.6在使用std=c++0xoption编译ARM时生成的一些机器代码。
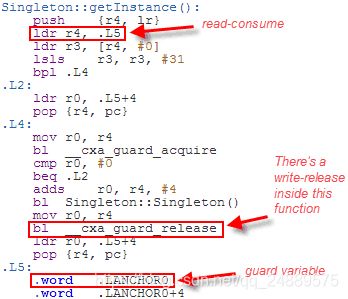
Since theSingletonis constructed at a fixed address, the compiler has introduced a separate guard variable for synchronization purposes. Note in particular that there’s nodmbinstruction to act as an acquire fence after the initial read of this guard variable. The guard variable is a pointer to the singleton, and therefore the compiler can take advantage of the data dependency to omit thedmbinstruction.__cxa_guard_releaseperforms a write-release on the guard, is therefore dependency-ordered-before the read-consume once the guard has been set, making the whole thing resilient against memory reordering, just like all the previous examples.
(译注:这段话是解释上面那个图的,本人不太懂。。就不翻译了)
如你所见,我们已伴随C++11走过了一段漫长的道路。双重检查锁定是一种稳定的模式,而且还远不止此!
就个人而言,我常常想,如果是需要初始化一个单例,最好是在程序启动的时候做这个事情。但是显然DCLP可以拯救你于泥潭。而且在实际的使用中,你还可以用DCLP来将任意数值类型存储到一个无锁的哈希表。在以后的文章中会有更多关于它的论述。
(译注:无锁哈希表:http://preshing.com/20130605/the-worlds-simplest-lock-free-hash-table)
译者总结
c++11用很多方式解决了多线程情况下单例模式初始化的问题。但是其中最简单的就是静态初始化(最后一个),2020-6-18测试的时候gcc4.8.5编译器已经支持这种写法。
白了个白。