第一次作业
1. 架构分析
第一次作业由于只涉及幂函数,难度较低,无论是在字符串判断还是优化上都没有太值得挑出来讲的地方。
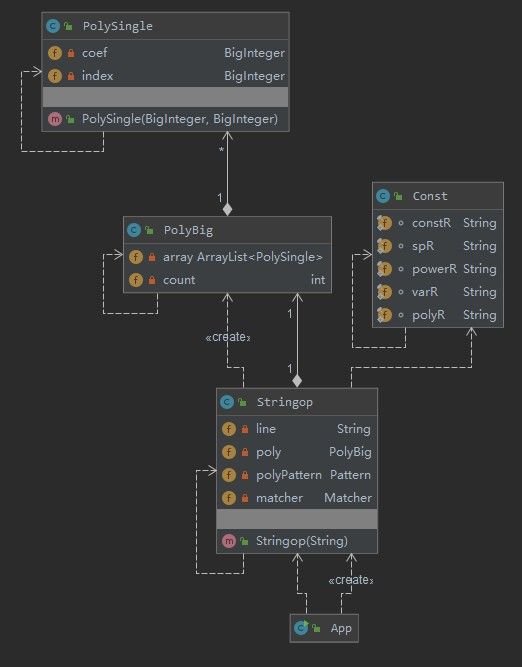
在架构上,我只是将处理输入数据的模块和存储多项式的模块分开,PolySingle为因子,PolyBig为并没有做更多的处理。
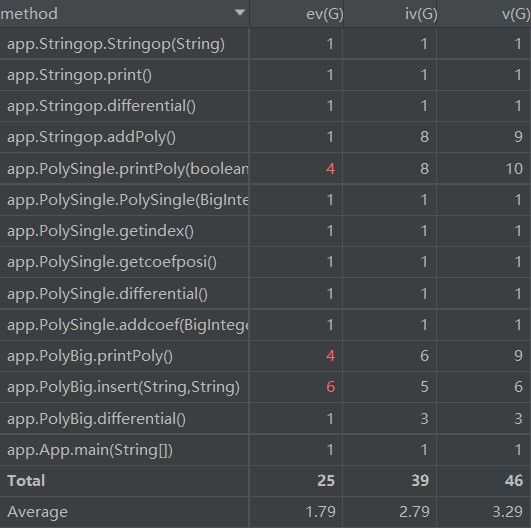
字符串判断中,我在去除了所有空格和制表符后以因子为单位进行正则匹配,读进因子后提取出指数、系数,生成一个因子的对象。我将合并同类项的步骤直接放在了处理字符串当中(可以看到insert方法的复杂度较高),而不是处理完后对所有的项进行合并,这样处理起来思路较为清晰。
2. bug处理
第一次作业在互测和强测中没有出现bug,也没有找出他人的bug。由于对正项提前等细节进行了处理,性能分也为满分。
3. 总结
虽然是分数最高的一次,但是实际上我对于架构方面并没有做过多考虑,整体上仍然偏向于面向过程。
第二次作业
1. 架构分析
第二次作业增加了三角函数和WF判定。由于约定不会出现空格插入而导致的WF,从而字符串判断的总体处理和第一次相差无几,只是对不同类的WF进行了分类处理。
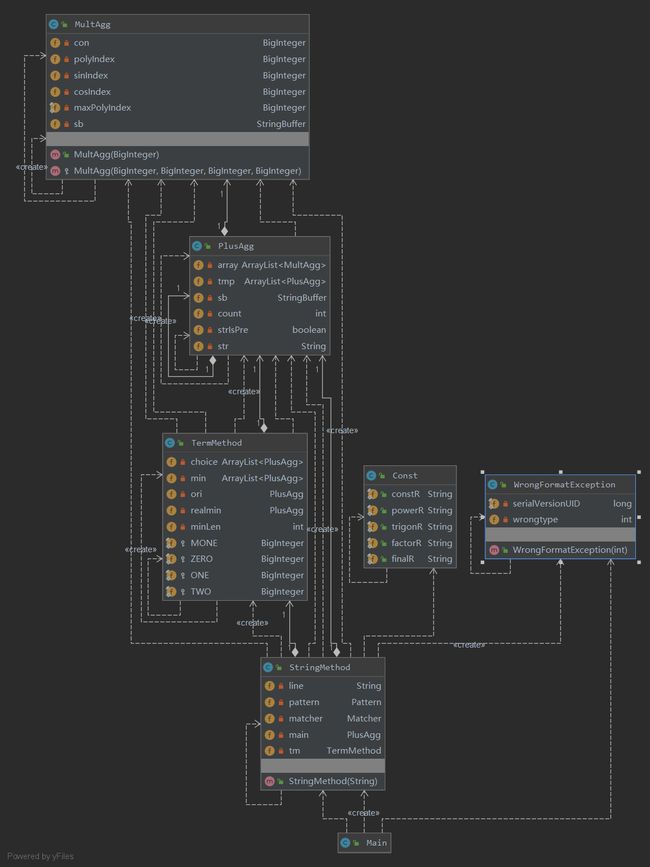
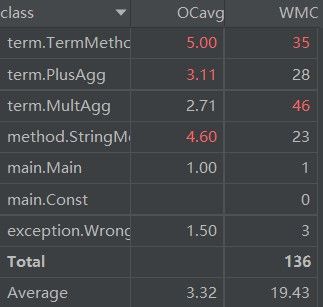
在架构上,写了一个特别复杂为之后拓展留接口的版本,但是由于写出来一团糟,所以最终改用了四元组方式(即a*x**b*sin(x)**c*cos(x)**d),命名为MultAgg。StringMethod主要负责读入,TermMethod主要负责深搜化简(从metrics可以看出,几个Method类循环复杂度都较高)。四元组使得合并同类项(只用判断指数是否对应相等)、求导(仅为四元组的线性变换)都变得十分轻松,需要优化的就只有三角函数化简相关了。
优化中,我使用了sin(x)**2+cos(x)**2=1和其变体进行化简(还加了一个a*sin(x)**4-a*cos(x)**4的特判),进行深度优先搜索,对于每一种四元组对,对所有可能的变换进行输出和长度比较,仅当输出长度严格小于原长度才继续进行搜索。(对于拆项化简导致长度先变长后变短我也思考过,但是还是在简洁性和性能之间做了一个权衡)
2. bug处理
第二次作业中互测出现了“把指数不超过10000理解成了指数小于10000”的极其弱智的错误,而强测中,由于我在本地测试对于自己的深度优先搜索过于自信没有设定熔断而导致了一个点超时。不过性能分上我只有两个点没有获得100,性能方面较为满意。
互测hack中,我使用了自己的回归测试样例为主,读代码为辅的策略,hack出了两个点。
3. 总结
第二次作业是我认为最满意的一次,也逐渐体会到了面向过程对复杂工程所带来的优势。但是如UML图所见,架构仍然比较乱,有提升的空间。
第三次作业
第三次作业中我由于各种原因低估了编写读取输入部分的代码所需要的时间,花了大量时间在构造数据结构存储上,而在编写读取输入部分的代码过程中,由于赶时间未考虑清楚使用了大量复杂逻辑,导致代码冗余且很多可能的WF判定被忽略,故而未通过中测。但是仍然在此简单整理一下第三次作业的思路。
1. 架构分析
这次作业相比于第二次作业增加了很多东西,判断的复杂程度有所提升,也增加了多项式的嵌套。我在顶层设计了一个抽象类Factor,MultAgg(项),PlusAgg(表达式),Trigon(三角函数),Power(幂函数)继承于此。其中去括号(如果表达式中只有一个项,把项提取出来;如果项中只有一个表达式因子,把表达式因子提取出来)、合并同类项(判断可相乘的合并,如cos(x)与cos(x)**3,可相加的合并,如2*x*sin(x)与3*x*sin(x))都是在读取中完成。至于求导就是新建表达式,按求导规则将因子一个个装填进表达式当中,再将新建的表达式与原表达式合并。
2. bug分析
读取数据方面bug较多,如对项前的正负号判断出错,对表达式因子未用括号括起来的情况有时没法判断。数据结构中的bug只有一个引用死循环,在使用深拷贝后解决。
3. 总结
这次未通过中测除了自身编程水平有待提高外,也还是因为没有考虑到整体布局而过于关注细枝末节,导致时间不够未能完成基本功能,引以为戒。在分析了其他同学的优秀代码后,我也对工厂模式的架构有了一个更清晰的了解。