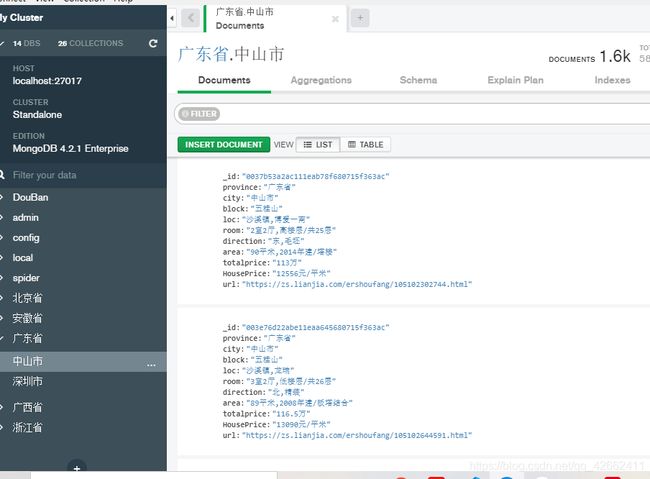
爬虫实例5:使用scrapy框架获取链家网二手房最新信息(获取单个城市所有街区二手房信息可以使用selenium动态获取页数)
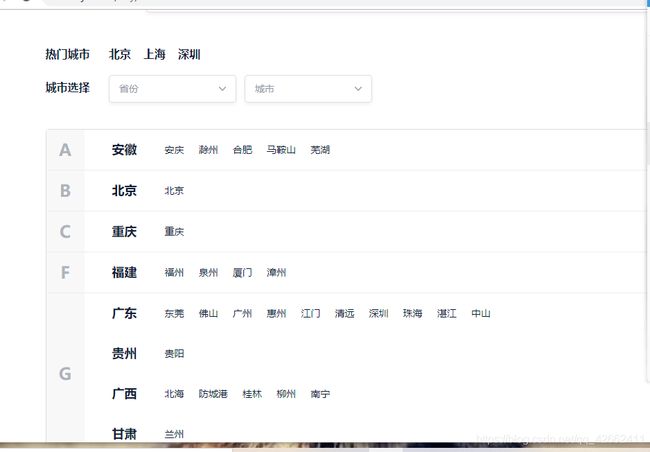
1-首先进行分析链家网 链家网址:https://www.lianjia.com/city/ 获取省市
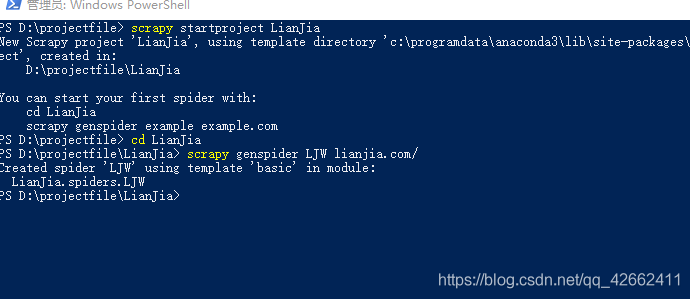
2-创建文件 打开虚拟机或者powershell 执行命令scrapy startproject LianJia
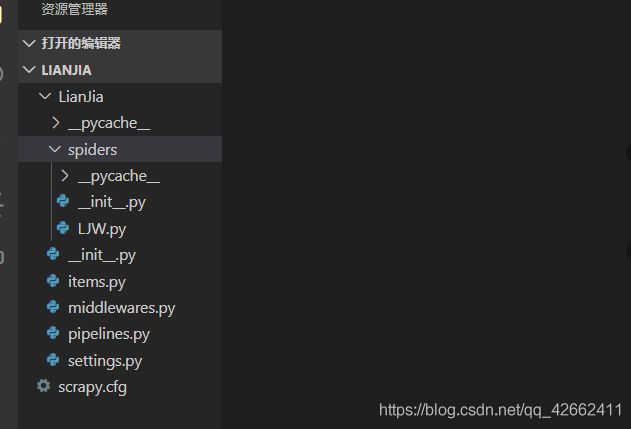
3-通过使用vscode或者pycharm找到创建的文件夹 如果是使用虚拟机创建文件夹 需要download下载在本地pycharm 这里我使用的是vscode 创建文件在powershell 中进行 在vscode显示如图
4-接下来就是对各个.py文件进行操作
(1)首先对settings.py文件中将ROBOTSTXT_OBEY = True改为ROBOTSTXT_OBEY = False

(2)接下来在items.py中构建需要的字段值

import scrapy
class LianjiaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
_id = scrapy.Field() #id值 这个在mongoDB 数据库中作为独一无二的序号
province = scrapy.Field() #省
city = scrapy.Field() #市
block = scrapy.Field() #区
loc = scrapy.Field() # 所在区域
room = scrapy.Field() #几室几厅
direction = scrapy.Field() #地理位置朝向
area = scrapy.Field() #面积
totalprice = scrapy.Field() #总价
HousePrice = scrapy.Field() #房价
url = scrapy.Field() #房子链接
(3)在spiders.LJW下开始构造函数 进行对链家网的爬取
import scrapy
class LjwSpider(scrapy.Spider):
name = 'LJW'
allowed_domains = ['lianjia.com/'] #允许的域名
start_urls = ['http://lianjia.com//'] #开始的链家
def parse(self, response):
pass
起始打开LJW.py文件就是上面这些代码 我们需要一一修改
import scrapy
class LjwSpider(scrapy.Spider):
name = 'LJW'
allowed_domains = ['lianjia.com/']
start_urls = ['https://www.lianjia.com/city/']
def parse(self, response):
pass
(4)接下来就不一一展示 直接进行代码的操作
# -*- coding: utf-8 -*-
import scrapy
from LianJia.items import LianjiaItem
import math
import uuid
from threading import RLock
import copy
lock = RLock()
class LjwSpider(scrapy.Spider):
name = 'LJW'
allowed_domains = ['lianjia.com']
start_urls = ['https://www.lianjia.com/city/']
def parse(self, response):
item = LianjiaItem()
#print(response.url,'==============')
#这里是包含省市
provinces_ele = response.xpath('//div[@class="city_province"]')
for ele in provinces_ele:
province = ele.xpath('./div[@class="city_list_tit c_b"]/text()').get()
#print(province,'========================')
citys_ele = ele.xpath('./ul/li/a') #城市的名称以及链接
for i in citys_ele:
city = i.xpath('./text()').get()
url = i.xpath('./@href').get()
#根据判断 有些地区没有二手房信息 这种就不要 比如https://cz.fang.lianjia.com/
if 'fang' in url:
continue
#print(city,url,province,'==================')
lock.acquire()
item['province'] = province+'省'
item['city'] = city+'市'
#print(item,'==================')
#注意 这里有个天坑 需要利用深浅复制 才能将item里面的city province传入到下面的解析函数中
#否则会出现城市与省份的一一不对应
copy_item = copy.deepcopy(item)
yield scrapy.Request(url,callback=self.parse_city,meta={'item':copy_item})
lock.release()
def parse_city(self,response):
#print(response.meta['item'],'=============')
url = response.url+'ershoufang/'
#print(url,'================')
yield scrapy.Request(url,callback=self.parse_block,meta={'item':response.meta['item']})
def parse_block(self,response):
#print(response.url,'================')
item = response.meta['item']
blocks_ele = response.xpath('//div[@class="position"]/dl[2]/dd/div[1]/div[1]/a')
for i in blocks_ele:
block = i.xpath('./text()').get()
item['block'] = block
#print(item,'==================')
baseUrl = response.url[:-12]
#print(block,baseUrl,'==================') # https://zb.lianjia.com
url = baseUrl+i.xpath('./@href').get().strip()
#print(url,'=====================')
yield scrapy.Request(url,callback=self.parse_block_page,meta={'item':item})
def parse_block_page(self,response):
#分析可得 获取每个街区的页数时 是动态页面 需要用到selenium
#我一开始用selenium爬取时 可以用 但是效率低 而且爬到一半会停止 总是不能爬取完事
#这里采取 分析每个区的页数 除以30 然后进行四舍五入 来获取页数
item=response.meta['item']
count = int(response.xpath("//h2[@class='total fl']/span/text()").get().strip())
#item['count'] = str(count)+'页'
#print(item,'================')
if math.ceil(int(count) / 30) > 100:
max_page = 100 #超过100页默认是100页
else:
max_page = math.ceil(int(count) / 30)
base_url = response.url + "pg%dco32/"
#https://hf.lianjia.com/ershoufang/feixi/pg%dco32/
#print(base_url,'**********************')
for index in range(1,max_page+1):
url = base_url % index #这里是获取每个区域不同也的信息
yield scrapy.Request(url=url, callback=self.parse_block_item, meta={"item": item})
def parse_block_item(self,response):
#获取详情页的30条信息
item = response.meta["item"]
item_urls = response.xpath('//ul[@class="sellListContent"]/li/a/@href').getall()
for item_url in item_urls:
url = item_url
#print(url,'=========================')
yield scrapy.Request(url,callback=self.detail,meta={'item':item})
def detail(self,response):
item = response.meta["item"]
item["_id"] = uuid.uuid1().hex
item["loc"] = ",".join(response.xpath("//div[@class='areaName']/span[@class='info']/a/text()").getall())
item["room"] = ",".join(response.xpath("//div[@class='room']/div/text()").getall())
item["direction"] = ",".join(response.xpath("//div[@class='type']/div/text()").getall())
item["area"] = ",".join(response.xpath("//div[@class='area']/div/text()").getall())
item["totalprice"] = response.xpath("//div[@class='price ']/span[@class='total']/text()").get() + "万"
item["HousePrice"] = response.xpath("//span[@class='unitPriceValue']/text()").get() + "元/平米"
item["url"] = response.url
return item
(5)构建用户代理中间件 当然你自己可以不构建 直接在settings.py将代理打开 并添加请求头就行 且在settings.py中激活
from fake_useragent import UserAgent
ua = UserAgent()
class UserAgentDownloaderMiddleware(object):
def process_request(self, request, spider):
request.headers['User-Agent'] = ua.random
return None
(6)构建管道 将数据储存到mongoDB数据库中 并且在settings.py中激活管道
from pymongo import MongoClient
class LianjiaPipeline(object):
def process_item(self, item, spider):
return item
# 保存数据
class SavePipeline(object):
def __init__(self):
self.client = MongoClient()
def process_item(self, item, spider):
if item:
print(item, "================================================")
province = str(item["province"])
city = str(item["city"])
if province and city:
self.client[province][city].insert_one(item)
return item
else:
return None
# 去重
class UniquePipeline(object):
def __init__(self):
self.client = MongoClient()
def process_item(self, item, spider):
province = str(item["province"])
city = str(item["city"])
if self.client[province][city].find_one(item):
return None
else:
return item
# 清洗
class ClearPipeline(object):
pass
(7)激活管道后 执行scrapy crawl LJW 在MongoDB数据库查看结果