第八十三篇 搭建神经网络logistic回归
心得:学习神经网络知识,面对很多的数学公式和推导,很难况且已经忘记了大部分关于微积分和概率论的东西,学神经网络这些都是基础,所以在之后碰到对应的知识点会详细的记录下来。加油~
文章目录:
- 一、logistic回归是什么
- 二、神经网络相关概念
- 1. 输入层,输出层,隐藏层
- 2. 权重和偏值
- 2. 激活函数(Activation Function)
- 3.损失函数
- 3. 导数
- 4. 梯度下降法
- 6. 向量化
- 7 .向前传播,向后传播
- 三、神经网络初步建立
一、logistic回归是什么
面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)
回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率
以下模型将是我们的计算的流程:
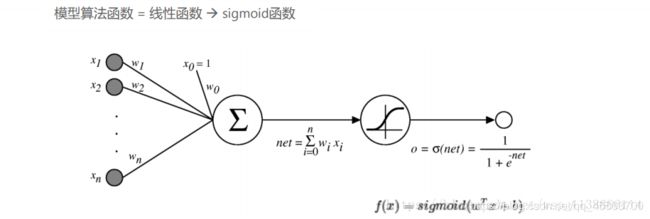
通过训练数据x来计算出向前传播成本cost,计算向后传播对应的导数,dw,db,通过迭代来更新参数w,b,来训练出一个契合数据的模型。
我们会通过吴恩达老师的logistic例子来对我们整个知识点,做一个归纳和总结,我们将会实现的内容是:
样本数据:大量关于猫的图片,有一部分不是猫。来搭建一个神经网络模型,来判断给的图片是不是猫,对图片做一个分类的问题
二、神经网络相关概念
1. 输入层,输出层,隐藏层
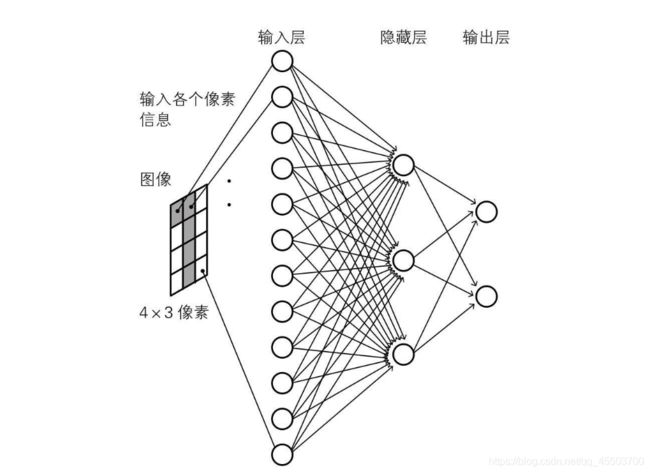
输入层:
如上图所示,十二个神经单元对应 4 * 3 像素(黑白),如果该像素是黑的,则对应神经元兴奋,否则静息
输出层:
输出层负责输出最后结果,输出层有两个节点,如果识别结果偏向0,那么第一个节点兴奋度会高于第二个节点,如果识别结果偏向1,那么第二个节点兴奋度会高于第一个节点
隐藏层:
为什么使用深层表示:
1 在人脸识别和声音识别中,往往前几次是用来选特征,后几层是组合
2 单层不能解决异或问题
3 层数需要根据实际项目去调试,不一定越多越好
单个隐藏层的意义
隐藏层的意义就是把输入数据的特征,抽象到另一个维度空间,来展现其更抽象化的特征,这些特征能更好的进行线性划分。单层不能解决异或XOR问题,所以出现了多个隐藏层。
多个隐藏层的意义
多个隐藏层其实是对输入特征多层次的抽象,最终的目的就是为了更好的线性划分不同类型的数据(隐藏层的作用)
2. 权重和偏值
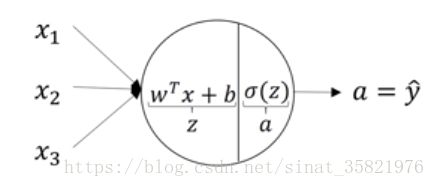
x1,x2,x3分别为输入x=[x1,x2,x3],那函数的输出 z = wx + b
w 为函数的权重,决定了函数的斜率
b 为函数偏值,决定了函数平移多少(当b>0的时候,直线往左边移动,当b<0的时候,直线往右边移动)
在之后训练建模的过程中,我们通过不断的训练来寻找最合适的w和b,达到最优为止。
https://blog.csdn.net/xwd18280820053/article/details/70681750
2. 激活函数(Activation Function)
作用:
将线性的函数转化为非线性函数,这样在神经网络表达中会更丰富。
-
sigmod函数

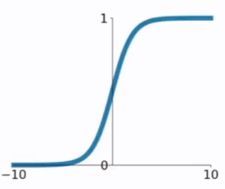
在sigmod函数中我们可以看到,其输出是在(0,1)这个开区间内,这点很有意思,可以联想到概率,但是严格意义上讲,不要当成概率。sigmod函数曾经是比较流行的,它可以想象成一个神经元的放电率,在中间斜率比较大的地方是神经元的敏感区,在两边斜率很平缓的地方是神经元的抑制区。常用于输出层的激活函数,隐藏层不建议使用 -
tanh函数

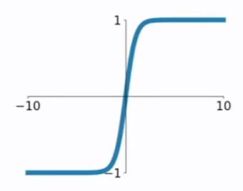
tanh是双曲正切函数,tanh函数和sigmod函数的曲线是比较相近的,首先相同的是,这两个函数在输入很大或是很小的时候,输出都几乎平滑,梯度很小,不利于权重更新;不同的是输出区间,tanh的输出区间是在(-1,1)之间,而且整个函数是以0为中心的,这个特点比sigmod的好。
一般二分类问题中,隐藏层用tanh函数,输出层用sigmod函数
- ReLU函数

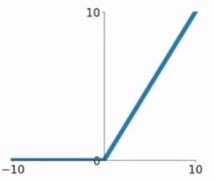
ReLU(Rectified Linear Unit)函数是目前比较火的一个激活函数,相比于sigmod函数和tanh函数,它有以下几个优点:
- 在输入为正数的时候,不存在梯度饱和问题
- 计算速度要快很多。ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。(sigmod和tanh要计算指数,计算速度会比较慢)
- PReLU函数
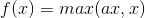
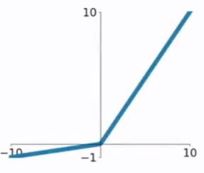
PReLU也是针对ReLU的一个改进型,在负数区域内,PReLU有一个很小的斜率,这样也可以避免ReLU死掉的问题。相比于ELU,PReLU在负数区域内是线性运算,斜率虽然小,但是不会趋于0,这算是一定的优势吧。
https://blog.csdn.net/kangyi411/article/details/78969642
3.损失函数
损失函数(loss function)也叫代价函数(cost function)。是神经网络优化的目标函数,神经网络训练或者优化的过程就是最小化损失函数的过程(损失函数值小了,对应预测的结果和真实结果的值就越接近)。损失函数也有很多种,拿常用的交叉熵损失函数举例,其单个样本二分类的损失函数公式如下:
![]()
![]()
y hat 输出通过激活函数输出的值,y是我们标记的数据值
对于m样本的损失函数可以使用:
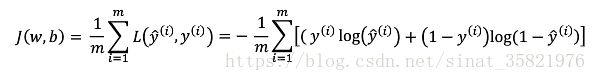
在logistic回归中:
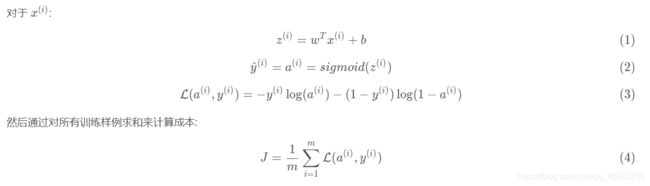
(1)代表计算函数输出值z
(2)代表激活函数的输出
(3)代表成本函数的值
(4)代表m个样本中的成本
https://blog.csdn.net/sinat_35821976/article/details/80611958
3. 导数
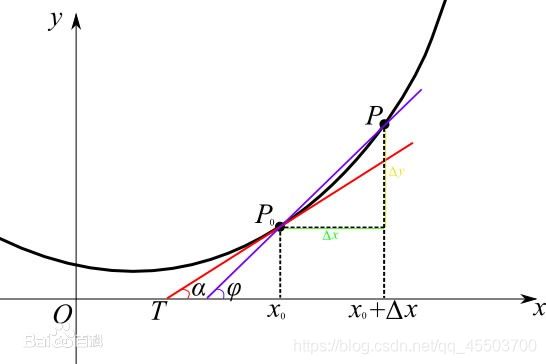
导数函数表示:

通俗来讲函数的导数就是某一点的斜率,在直线中斜率是不会发生变化的,在曲线中斜率会一直发生改变,函数的导数一般可查看微积分课本
4. 梯度下降法
梯度下降就是让梯度中所有偏导函数都下降到最低点的过程.(划重点:下降)
都下降到最低点了,那每个未知数(或者叫维度)的最优解就得到了,所以他是解决函数最优化问题的。具体算法是通过某点的导数,来设定学习率来一步步缩小成本,直至导数为0,解为最优解。
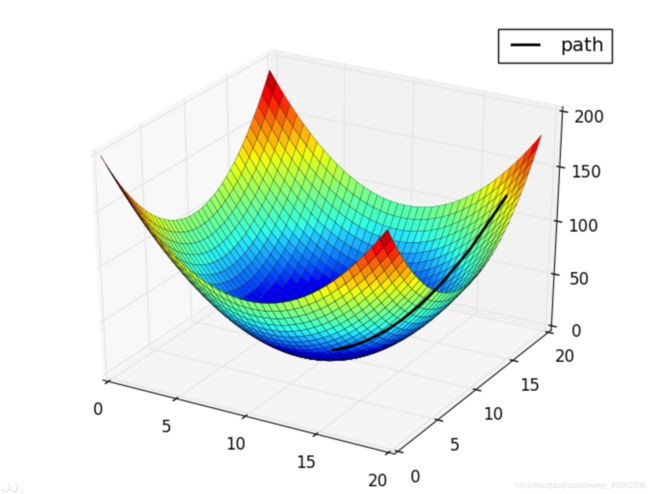
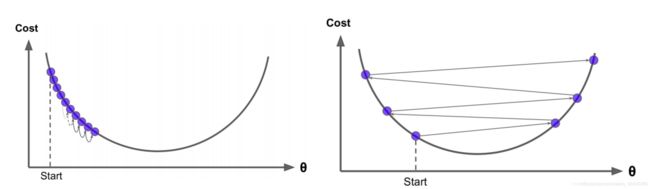
图中为不同学习率,学习的过程,明显学习率越小,学习迭代次数会越多,但最优解就越好;反而学习率大的时候不容易找到最优解,学习速度块。
在UFLDL中反向传导算法一节也是直接给出的公式:
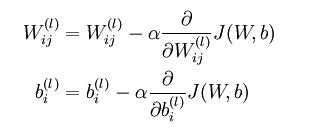
梯度下降推导式
6. 向量化
使用向量是为了提升代码的运行效率。可以去除显式for循环,用向量来代替,数据量大的时候,将会很大程度提升整个程序的运行效果。
向量加法:
对应位置相加
import numpy as np
a = np.array([-1, 2])
b = np.array([3, 1])
print a + b # [2 3]
Matrix product (矩阵乘法)

注意事项编辑
1、当矩阵A的列数(column)等于矩阵B的行数(row)时,A与B可以相乘。
2、矩阵C的行数等于矩阵A的行数,C的列数等于B的列数。
3、乘积C的第m行第n列的元素等于矩阵A的第m行的元素与矩阵B的第n列对应元素乘积之和。
也称之为点积
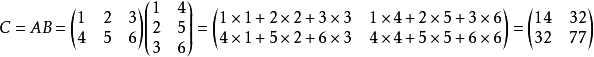
import numpy as np
a = np.array([3, 5, 2])
b = np.array([1, 4, 7])
print a.dot(b) # 37
print np.dot(a, b) # 37(另一种等价写法)
7 .向前传播,向后传播
向前传播:
输入层样本从输入层进入网络,经隐藏层逐层传递至输出层,如果输出层实际输出与期望输出不同,则转至误差反向传播,如果输出层的实际输出与期望相同,结束学习。
向后传播:
将输出误差按原路反传计算,通过隐藏层反向直至输入层,在反传过程中误差分摊给各个单元,计算输出对权值和偏值得导数,通过梯度下降法完成,通过设定学习步长和迭代次数来调整。
三、神经网络初步建立
https://blog.csdn.net/u013733326/article/details/79827273
- 准备训练数据和测试数据(定义特征值)
- 初始化权重w和偏值b
- 循环迭代次数
- 向前传播计算损失
- 向后传播计算导数(梯度)
- 更新参数
- 通过调整好的参数去预测
步骤流程图:
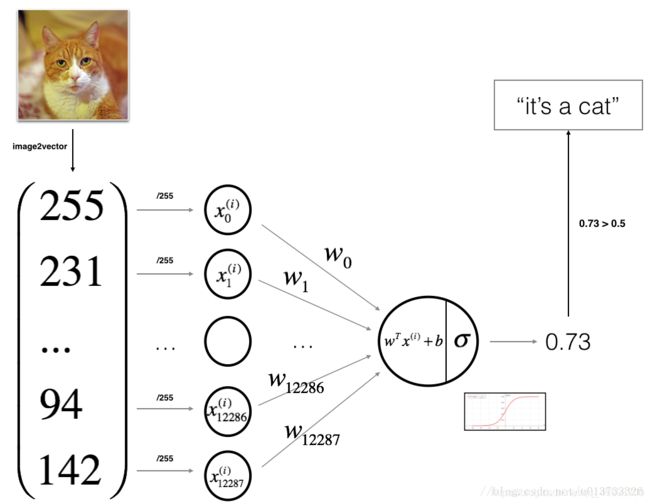
import numpy as np
import matplotlib.pyplot as plt
import h5py
# from lr_utils import load_dataset
def load_dataset():
#提取数据
train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((1, train_set_y_orig.shape[0]))
test_set_y_orig = test_set_y_orig.reshape((1, test_set_y_orig.shape[0]))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
#训练集_图片的维数 : (209, 64, 64, 3)
#训练集_标签的维数 : (1, 209)
#测试集_图片的维数: (50, 64, 64, 3)
#测试集_标签的维数: (1, 50)
# 将训练集的维度降低并转置。
# 原始数据的维数 (209, 64, 64, 3) -->>我们需要转为 (64*64*3,209)
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0], -1).T
# 将测试集的维度降低并转置。
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0], -1).T
# 因为在RGB中不存在比255大的数据,所以我们可以放心的除以255,让标准化的数据位于[0,1]之间
train_set_x = train_set_x_flatten / 255
test_set_x = test_set_x_flatten / 255
def sigmoid(z):
"""
参数:
z - 任何大小的标量或numpy数组。
返回:
s - sigmoid(z)
"""
s = 1 / (1 + np.exp(-z))
return s
def initialize_with_zeros(dim):
"""
此函数为w创建一个维度为(dim,1)的0向量,并将b初始化为0。
参数:
dim - 我们想要的w矢量的大小(或者这种情况下的参数数量)
返回:
w - 维度为(dim,1)的初始化向量。
b - 初始化的标量(对应于偏差)
"""
w = np.zeros(shape=(dim, 1))
b = 0
# 使用断言来确保我要的数据是正确的
assert (w.shape == (dim, 1)) # w的维度是(dim,1)
assert (isinstance(b, float) or isinstance(b, int)) # b的类型是float或者是int
return (w, b)
def propagate(w, b, X, Y):
"""
实现前向和后向传播的成本函数及其梯度。
参数:
w - 权重,大小不等的数组(num_px * num_px * 3,1)
b - 偏差,一个标量
X - 矩阵类型为(num_px * num_px * 3,训练数量)
Y - 真正的“标签”矢量(如果非猫则为0,如果是猫则为1),矩阵维度为(1,训练数据数量)
返回:
cost- 逻辑回归的负对数似然成本
dw - 相对于w的损失梯度,因此与w相同的形状
db - 相对于b的损失梯度,因此与b的形状相同
"""
m = X.shape[1]
# 正向传播
A = sigmoid(np.dot(w.T, X) + b) # 计算激活值,请参考公式2。
cost = (- 1 / m) * np.sum(Y * np.log(A) + (1 - Y) * (np.log(1 - A))) # 计算成本,请参考公式3和4。
# 反向传播
dw = (1 / m) * np.dot(X, (A - Y).T) # 请参考视频中的偏导公式。
db = (1 / m) * np.sum(A - Y) # 请参考视频中的偏导公式。
# 使用断言确保我的数据是正确的
assert (dw.shape == w.shape)
assert (db.dtype == float)
cost = np.squeeze(cost)
assert (cost.shape == ())
# 创建一个字典,把dw和db保存起来。
grads = {
"dw": dw,
"db": db
}
return (grads, cost)
def optimize(w, b, X, Y, num_iterations, learning_rate, print_cost=False):
"""
此函数通过运行梯度下降算法来优化w和b
参数:
w - 权重,大小不等的数组(num_px * num_px * 3,1)
b - 偏差,一个标量
X - 维度为(num_px * num_px * 3,训练数据的数量)的数组。
Y - 真正的“标签”矢量(如果非猫则为0,如果是猫则为1),矩阵维度为(1,训练数据的数量)
num_iterations - 优化循环的迭代次数
learning_rate - 梯度下降更新规则的学习率
print_cost - 每100步打印一次损失值
返回:
params - 包含权重w和偏差b的字典
grads - 包含权重和偏差相对于成本函数的梯度的字典
成本 - 优化期间计算的所有成本列表,将用于绘制学习曲线。
提示:
我们需要写下两个步骤并遍历它们:
1)计算当前参数的成本和梯度,使用propagate()。
2)使用w和b的梯度下降法则更新参数。
"""
costs = []
# 迭代循环来更新参数
for i in range(num_iterations):
# 计算成本和导数
grads, cost = propagate(w, b, X, Y)
dw = grads["dw"]
db = grads["db"]
w = w - learning_rate * dw
b = b - learning_rate * db
# 记录成本
if i % 100 == 0:
costs.append(cost)
# 打印成本数据
if (print_cost) and (i % 100 == 0):
print("迭代的次数: %i , 误差值: %f" % (i, cost))
params = {
"w": w,
"b": b}
grads = {
"dw": dw,
"db": db}
return (params, grads, costs)
def predict(w, b, X):
"""
使用学习逻辑回归参数logistic (w,b)预测标签是0还是1,
参数:
w - 权重,大小不等的数组(num_px * num_px * 3,1)
b - 偏差,一个标量
X - 维度为(num_px * num_px * 3,训练数据的数量)的数据
返回:
Y_prediction - 包含X中所有图片的所有预测【0 | 1】的一个numpy数组(向量)
"""
m = X.shape[1] # 图片的数量
Y_prediction = np.zeros((1, m))
w = w.reshape(X.shape[0], 1)
# 计预测猫在图片中出现的概率
A = sigmoid(np.dot(w.T, X) + b)
for i in range(A.shape[1]):
# 将概率a [0,i]转换为实际预测p [0,i]
Y_prediction[0, i] = 1 if A[0, i] > 0.5 else 0
# 使用断言
assert (Y_prediction.shape == (1, m))
return Y_prediction
def model(X_train, Y_train, X_test, Y_test, num_iterations=2000, learning_rate=0.5, print_cost=False):
"""
通过调用之前实现的函数来构建逻辑回归模型
参数:
X_train - numpy的数组,维度为(num_px * num_px * 3,m_train)的训练集
Y_train - numpy的数组,维度为(1,m_train)(矢量)的训练标签集
X_test - numpy的数组,维度为(num_px * num_px * 3,m_test)的测试集
Y_test - numpy的数组,维度为(1,m_test)的(向量)的测试标签集
num_iterations - 表示用于优化参数的迭代次数的超参数
learning_rate - 表示optimize()更新规则中使用的学习速率的超参数
print_cost - 设置为true以每100次迭代打印成本
返回:
d - 包含有关模型信息的字典。
"""
# 1.初始化参数w,b w的维数为图片数据的特征(64*64*3,1)
w, b = initialize_with_zeros(X_train.shape[0])
# 2.
parameters, grads, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
# 从字典“参数”中检索参数w和b
w, b = parameters["w"], parameters["b"]
# 预测测试/训练集的例子
Y_prediction_test = predict(w, b, X_test)
Y_prediction_train = predict(w, b, X_train)
# 打印训练后的准确性
# 当预测值与实际值一样时,值为零;预测值不准确时值为1,所以对为1的值求平均,就是不准确率
print("训练集准确性:", format(100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100), "%")
print("测试集准确性:", format(100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100), "%")
d = {
"costs": costs,
"Y_prediction_test": Y_prediction_test,
"Y_prediciton_train": Y_prediction_train,
"w": w,
"b": b,
"learning_rate": learning_rate,
"num_iterations": num_iterations}
return d
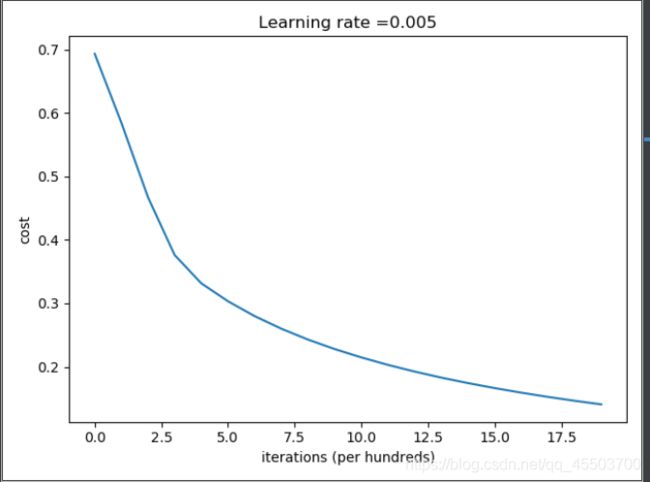
d = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations=2000, learning_rate=0.005, print_cost=True)
# 绘制图
print(d['costs'])
# squeeze 函数:从数组的形状中删除单维度条目,即把shape中为1的维度去掉
costs = np.squeeze(d['costs'])
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(d["learning_rate"]))
plt.show()