第一单元总结
度量分析
类分析
第一次作业复杂度:

第一次作业没有摆脱以前的思维,还是一main到底,第二次作业开始重构,由于使用的数据结构还是hashmap,可能与大部分同学相似,在此不做过多的说明。
第二次作业复杂度:

可以看出由于与划分了不同的数据结构,结构之间开始有所依赖,操作开始复杂。
值得一提的是,在本次作业中,对类似
情况也进行了化简。
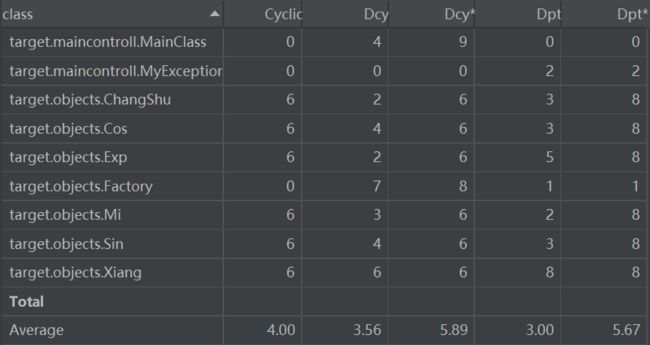
由于第一第二次数据结构设计不合理,仅仅有基本的hashmap存储数据结构,因此略过,主要对第三次作业进行分析。
上图是最终第三次作业的类的结构:
类数量:10
平均属性个数:2
平均方法个数:平均在5-6(实现大量重写方法)
方法平均规模:15
方法最大规模:54
方法复杂度:部分方法存在嵌套调用,除此之外控制结构并不复杂。分支结构嵌套不超 过两层。
总代码规模:900行
耦合情况:
存储类中出现循环依赖,传递依赖,这主要与采用的存储方式有关。
继承关系:
继承主要以接口实现,主要的数据类型都继承了一个单一的类。
UML图:主要数据结构的组成以及变化

Bug 分析
第一次bug:没有考虑系数为0的情况,低级错误
第二次bug:优化的时候分支语句写少了一个else,出现逻辑错误
第三次bug:没有考虑额到表达式合并时存在次数不为1的情况,以及由于设计太过粗糙导致的CPU超时问题
第三次bug有分析的必要,由于本人还是采用hashmap存储项之中因子,因此,对于相同的因子还是采取合并的策略,但是由于合并的时候没有考虑到可能有相同的表达式因子合并,因此出错。这样的错误和构建的数据结构还是有很大的关系的,对于直接采用表达式树可能就不存在这样的问题。另外,由于将表达式直接作为因子,没有再进一步地解析表达式,因此,此次的优化和运行都比较糟糕,这是没有好好考虑这次数据组织方式导致的,值得反思。
分析bug策略
覆盖性测试
bug主要出现在:
(1)临界数据:如**50,+-0
(2)同类数据的处理:如((x)-(x))
(3)符合输入要求的极端数据:如((((((((x)))))))))
(4)单独数据:如x ,1
(5)构造方法允许的不常见类型:+++1
(6)各种与空格相关的WF
(7)针对不同的程序结构,可以对先进行替换处理的程序采用加入替换字符扰乱的操作(尽管不能输入非法数据);对于采用了遍历某一个数据对象而没有catch异常的,可以考虑用空数据。
评测机
评测机对于黑盒测试的重要性自然不言而喻,能够短时间内进行大量测试。另外,值得注意的是,评测机虽然能够进行大量测试,但是白箱测试,以及边界数据的测试还是很有必要。
创建模式
思路:
第一次:直接通过捕获组获得每一个项
第二次:删除空字符后,整体匹配是否符合对应表达式的格式,随后再逐个对项进行匹配捕获,再对每一个所得的结果进行再度匹配每一个因子,采用分治的思想,层次化设计读取的方式。
第三次:与第二次读取方式大体上类似,只是在因子读取中由于出现了表达式因子,而java不支持递归正则表达式,采取将表达式的内容提取后递归读取的方法。另外,由于递归调用分析的存在,错误的传递也需要逐层传递。
我的创建模式并没有采用单独的工厂类进行创建,但是,考虑到实际的获得数据过程中进行了对于不同因子的识别和捕获,其实大致上与其他同学的工厂类相似(因为没有标准化的因子结构,各个因子之间有不同的组成成分,我觉得标准的工厂类没有太大意义)。如果需要重构,我会选择将生成部分独立成一个工厂类,而不是在扫描类中进行生成,工厂类中独立出来的部分可以继承自一个工厂接口,在扫描类中能够获得不同的类别及其内容后再调用相应的工厂类。这样,耦合度低,也避免了重类的产生。
对比和心得
对于表达式树的思考
参考过dalao的思路,发现自己的做法还是不好。优秀的代码采用的普遍都是表达式树的方法,这种结构能够很好地存储不同种因子之间的乘法关系以及不同项之间的加法关系,应该说是一种比较合理的存储结构(实际上对于表达式而言,以前学过的做法也是用表达式树存储对应的结构),再结合深度优先遍历(中序)就可以很好地得出了不同的层次关系。在这种结构中,每一个节点可以是不同的因子,包括幂函数,常数,三角函数和表达式因子。在进行求导的时候可以根据非叶节点的符号选择对应的方法进行求导(乘法则对叶节点两侧分别求导在相乘,加法则对非叶节点的两侧的节点分别求导再相加),这样对每一次子项求导所得的表达式树用乘法或者加法再进行链接构成新的表达式树。这种做法的可扩展性很好,毕竟所有的表达式都可以用加法和乘法表示。
对于相应的化简,由于没有细想,我只有一个大概的思路,就是先获得所有最高层的乘法结构,也就是项,从每一个项的根节点出发,通过遍历的形式合并同类项(这样有必要实现equals,hashcode方法,常数类可以直接相乘化简),再在最高的层次,也即表达式的层次合并相同的项(项也有必要实现equals()方法),并且相同的合并方法对表达式因子也要递归使用(但是表达式因子不合并),这样就能完成最基本的合并同类项化简。
对于输出而言,也只需要分别实现因子和项的toString方法再在表达式的层次递归调用即可。
自己的做法
###### 思考的过程
对于第三次作业,我重构了大部分的代码,下面阐述一下自己的思考过程,以帮助自己回想。
(1)数据结构的思考:
存储数据的结构可能是对于代码可扩展性,以及鲁棒性都有着极其重要的意义。
在一开始思考时,主要根据具体的要求,考虑到数据结构必须要有层次化设计,根据指导书的提示,将数据结构设计为因子(幂函数,三角函数,表达式因子,实现"因子"接口),项,表达式三层。
一开始思考了存储的结构的确想过表达式树的结构,但是依赖不太熟悉java的数据结构,二来对于合并同类项这种操作也不方便,因此,还是决定采用hashmap的形式来模拟加法结构和乘法结构,把每一个因子作为乘法的一个entry,每一个项作为表达式的一个元素。采用由下而上的求导方法以及toString方法肯定能够得出结果。
(但是,现在看来,直接把表达式作为因子的做法封装了整个表达式,对于外部几乎是不可访问的,这种对项的不可见性对于项内部的化简是由严重阻碍的)
(2)parse方法:
由于递归,直接的正则表达式已经不可能对表达式整体解析,因此,我选择采用层次化扫描。
parseExp -> parseItem -> parseFactor
要点:
(Ⅰ)如何处理WF:考虑到外层扫描对内层表达式是不可知的,因此,每次parseExp仅仅只对外层进行格式判断,内层判断通过扫描内层表达式的时候再输出,通过Exception的层次化传递.
(Ⅱ)如何处理识别表达因子,三角函数表达式的问题:可以明确的是,扫描的时候,对于括号的嵌套情况,采用贪心的,非贪心的匹配都是不合适,断言也不能处理.收到讨论区的启发,以及数据结构匹配括号的启发,栈能够很好地模拟括号嵌套的情况,因此决定采用栈,对最外层括号进行识别更换,如将'('换为'[',')'换为']',可以很好地实现判断.
(Ⅲ)扫描生成的数据:parseExp生成Exp对象(项的hashset),parseItem返回项的对象,parseFactor返回因子的对象,项和表达式都应该实现merge()方法,对项,表达式,因子,进行融合.
(3)求导方法:对于求导,依然应该实现层次化求导,自下而上实现不同层次数据的生成,具体来说,我的设计是,因子求导成为项,项求导得到表达式,表达式求导则再变为一个表达式因子(当时没有想太多化简的方面,仅仅是因为这样生成的层次更加易于管理).通过层次化调用不同的求导方法,可以生成新的表达式树.(由于在表达式生成的环节需要大量的clone()方法,要实现深克隆方法,应该注意每一种数据层次都要实现深克隆)
(4)toString方法:由于前面在生成表达式的时候使用hashmap装载数据,因此同类项的化简已经包含在merge()方法中,牢记着第二作业贸然添加化简方法导致的错误,我没有再对项的内部进行化简.但是,现在想来,一些简单的化简如果实现,就不会有超长的输出了(例如最简单的嵌套单个表达式因子所导致的层层冗余嵌套).
反思
由于思维惯性的影响,hash合并同类项的简便性,以及秉持着内置API肯定比自己写的结构要快的思想,我在第三次作业依然用了hashmap的结构。
我主要是利用hashmap存储因子,实现乘法结构;hashset存储项,实现加法结构。下面,详细地说一下。hashmap主要是由因子作为key,因子的幂作为value,这种做法,对于实现同类相合并自然有极大的优势(但是应该考虑到不同的表达式因子的合并后产生多次项的问题,task3bug所在),但是由于因子和幂分开,求导应该基于entry的基础。对于每一个项的求导则是生成一个表达式,这个过程也比较简单,只需要每次深克隆一次该项,去除求导因子再合并因子对应的导数即可,最后通过相加将不同的项合并成一个表达式。另外,表达式求导则是将不同项求导的合并成一个表达式树。
这种做法在生成的表达式树的时候就已经合并同类项了,还是十分方便的,并且对于遍历一个项内部因子或者表达式内部项的时候比较简单(已经封装好每一个项和表达式,优化比较容易)。但是,由于直接将表达式封装为一个数据类型,表达式内部对于外部是不可见的,因此想要优化项之中表达式因子是比较难的。另外,值得一提的是,对于不同类型实现hashcode的时候,应该注意不同的因子在化简的时候,还是应该注意到不同的hashcode在对内部数据操作前后应该相同(例如化简常数项的时候,消去常数;不同的幂函数合并),这样才能够保证在hash存储结构中正常,才符合变化前后对象视为同一个的原则。
体会
(1)写代码还是应该勇于尝试不熟悉的写法,坚持自己认为正确的,好的写法,这次由于畏首畏尾,还是采取了保守的写法。这种写法毕竟没有很好地模拟出表达式的结构,对于不同的要求可能又需要大的改动。另外,这种写法没有很好的优化能力,可以理解为是因为没能够很好模拟出表达式结构的表现,封装表达式作为一个因子本来就不能够对表达式进行很好的操作。
(2)对于必要的优化还是要进行的,想着60个字符不会超时,但是我还是太小看递归的消耗能力了.