Datax源码学习
淘宝开源框架Datax简介
DataX是什么?
DataX是一个在异构的数据库/文件系统之间高速交换数据的工具,实现了在任意的数据处理系统(RDBMS/Hdfs/Local filesystem)之间的数据交换,由淘宝数据平台部门完成。
DataX用来解决什么?
目前成熟的数据导入导出工具比较多,但是一般都只能用于数据导入或者导出,并且只能支持一个或者几个特定类型的数据库。这样带来的一个问题是,如果我们拥 有很多不同类型的数据库/文件系统(Mysql/Oracle/Rac/Hive/Other…),并且经常需要在它们之间导入导出数据,那么我们可能需 要开发/维护/学习使用一批这样的工具(jdbcdump/dbloader/multithread/getmerge+sqlloader /mysqldumper…)。而且以后每增加一种库类型,我们需要的工具数目将线性增长。(当我们需要将mysql的数据导入oracle的时候,有没 有过想从jdbcdump和dbloader上各掰下来一半拼在一起到冲动?) 这些工具有些使用文件中转数据,有些使用管道,不同程度的为数据中转带来额外开销,效率差别很非常大。很多工具也无法满足ETL任务中常见的需求,比如日 期格式转化,特性字符的转化,编码转换。另外,有些时候,我们希望在一个很短的时间窗口内,将一份数据从一个数据库同时导出到多个不同类型的数据库。 DataX正是为了解决这些问题而生。
(问题: 新增第n+1个数据源,是不是要新开发n个数据同步工具 ?)
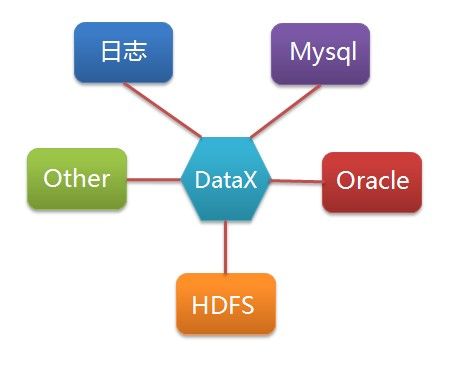
我们只需要针对新增的数据源开发的一套Reader/Writer插件,即可实现任意数据的互导
DataX特点?
- 在异构的数据库/文件系统之间高速交换数据
- 采用Framework + plugin架构构建,Framework处理了缓冲,流控,并发,上下文加载等高速数据交换的大部分技术问题,提供了简单的接口与插件交互,插件仅需实现对数据处理系统的访问
- 运行模式:stand-alone
- 数据传输过程在单进程内完成,全内存操作,不读写磁盘,也没有IPC
- 开放式的框架,开发者可以在极短的时间开发一个新插件以快速支持新的数据库/文件系统。(具体参见《DataX插件开发指南》)
DataX结构模式(框架+插件)
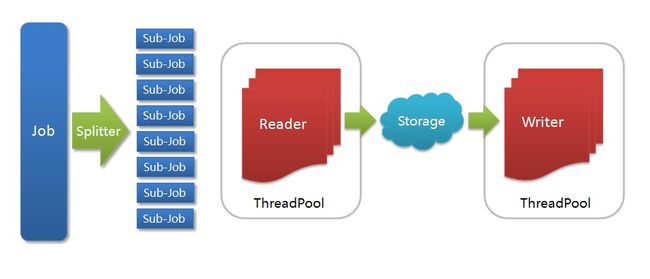
- Job: 一道数据同步作业
- Splitter: 作业切分模块,将一个大任务与分解成多个可以并发的小任务.
- Sub-job: 数据同步作业切分后的小任务
- Reader(Loader): 数据读入模块,负责运行切分后的小任务,将数据从源头装载入DataX
- Storage: Reader和Writer通过Storage交换数据
- Writer(Dumper): 数据写出模块,负责将数据从DataX导入至目的数据地
DataX框架内部通过双缓冲队列、线程池封装等技术,集中处理了高速数据交换遇到的问题,提供简单的接口与插件交互,插件分为Reader和 Writer两类,基于框架提供的插件接口,可以十分便捷的开发出需要的插件。比如想要从oracle导出数据到mysql,那么需要做的就是开发出 OracleReader和MysqlWriter插件,装配到框架上即可。并且这样的插件一般情况下在其他数据交换场合是可以通用的。更大的惊喜是我们 已经开发了如下插件:
Reader插件
- hdfsreader : 支持从hdfs文件系统获取数据。
- mysqlreader: 支持从mysql数据库获取数据。
- sqlserverreader: 支持从sqlserver数据库获取数据。
- oraclereader : 支持从oracle数据库获取数据。
- streamreader: 支持从stream流获取数据(常用于测试)
- httpreader : 支持从http URL获取数据。
Writer插件
- hdfswriter:支持向hdbf写入数据。
- mysqlwriter:支持向mysql写入数据。
- oraclewriter:支持向oracle写入数据。
- streamwriter:支持向stream流写入数据。(常用于测试)
您可以按需选择使用或者独立开发您自己的插件 (具体参见《DataX插件开发指南》)
DataX在淘宝的运用
DataX上线后,我们对淘宝数据平台原有作业进行了逐步批量迭代替换。数据同步工具归一化为DataX后,大大提高了用户拖表数据速度和内存利用率, 同时针对归一化后的DataX工具,我们能够做到更好应对mysql切库、数据同步监控等以前零散工具下很难完成的运维任务。
下面是部分工具替换后的比对情况:

目前DataX在淘宝数据平台数据已经广泛地被用于数据同步作业,每天共计有 4000+道 DataX数据同步作业分布在全天各个时段运行。
DataX/DbSync/TT已经构成了淘宝数据平台数据提供的三大支柱:
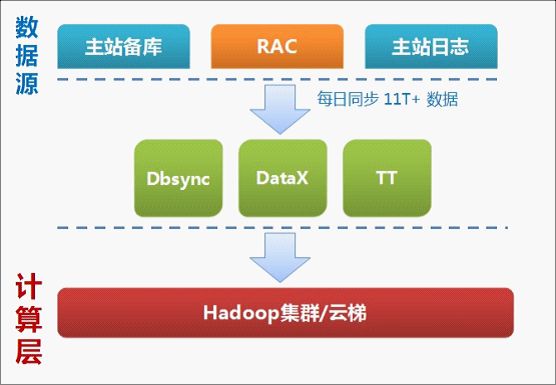
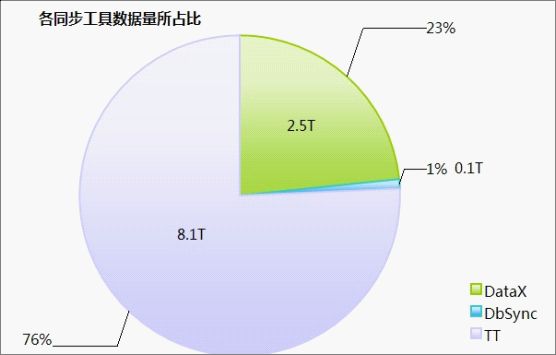
其中DataX每天为淘宝贡献 2.5T 数据量,占淘宝数据平台总体数据同步的 23% ,占数据库数据同步的 96% 。
Datax插件开发
项目中需要开发从HDFS向MySQL导数据的功能,因此需要开发hdfsreader和mysqlwriter这两个插件。
hdfsreader
HdfsDirSplitter.java
public class HdfsDirSplitter extends Splitter {
private Path p = null;
private FileSystem fs = null;
@Override
public int init() {
String dir = param.getValue(ParamKey.dir);
if (dir.endsWith("*")) {
dir = dir.substring(0, dir.lastIndexOf("*"));
}
String ugi = param.getValue(ParamKey.ugi, null);
if (dir == null) {
throw new DataExchangeException("Can't find the param ["
+ ParamKey.dir + "] in hdfs-spliter-param.");
}
p = new Path(dir);
String configure = param.getValue(ParamKey.hadoop_conf, "");
try {
fs = DFSUtils.createFileSystem(new URI(dir),
DFSUtils.getConf(dir, ugi, configure));
if (!fs.exists(p)) {
IOUtils.closeStream(fs);
throw new DataExchangeException("the path[" + dir
+ "] does not exist.");
}
} catch (Exception e) {
throw new DataExchangeException("Can't create the HDFS file system:"
+ e);
}
return PluginStatus.SUCCESS.value();
}
@Override
public List split() {
List v = new ArrayList();
try {
FileStatus[] status = fs.listStatus(p);
for (FileStatus state : status) {
if (!state.isDir()) {
String file = state.getPath().toString();
PluginParam oParams = SplitUtils.copyParam(param);
oParams.putValue(ParamKey.dir, file);
v.add(oParams);
}
}
} catch (IOException e) {
throw new DataExchangeException(
"some errors have happened in fetching the file-status:"
+ e.getCause());
} finally {
IOUtils.closeStream(fs);
}
return v;
}
} 在HdfsReader的split方法中调用
public List split(PluginParam param) {
HdfsDirSplitter spliter = new HdfsDirSplitter();
spliter.setParam(param);
spliter.init();
return spliter.split();
} 
HdfsReader.java中定义的内部类:

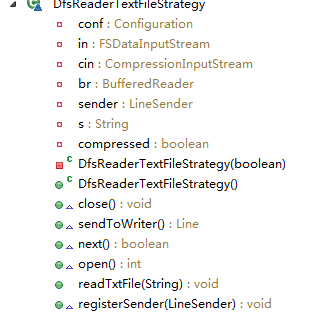
这里定义了一个DfsReaderStrategy的接口,定义了三个继承该接口的类,分别对应流文件、文本文件、复杂文本文件的处理。
HdfsReader中定义了一个DfsReaderStrategy的类变量
![]()
并在connect函数中进行初始化

在HdfsReader的startRead方法中会调用readerStrategy.sendToWriter()向writer写传数据
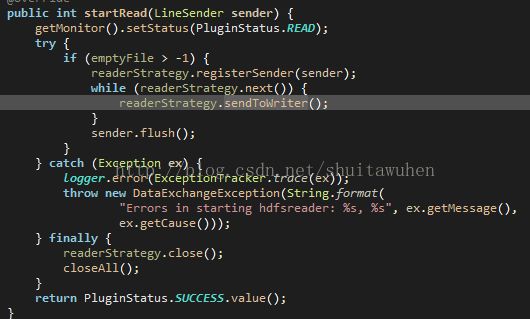
项目中实际调用的是DfsReaderTextFileStrategy这个类的对象实例
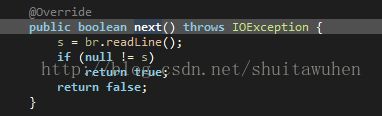
next函数从bufferreader中读取一行
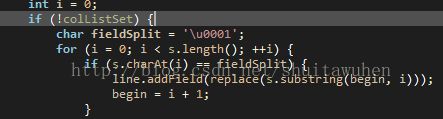
open函数,打开输入流,装入BufferReader

sentToWriter函数将BufferReader中的每一行取出,根据字段分隔符,切分字段,并将字段装入Line对象传给Writer

先前调试整个Datax框架的时候,一直有问题,在reader读取HDFS文件内容的时候,一直找不到字段分隔符,切分不出需要的字段。
这是在HdfsReader类中定义的类变量
![]()
最后我在sentToWriter函数中定义了一个同名的局部变量,覆盖了类变量问题就解决了
这个问题很奇葩,至今没有找到这个bug的根本原因。写了一个测试demo,发现类的私有类变量是可以传递给内部类使用的。。。后续继续分析。
今天重新过了一遍代码,发现自己犯了一个比较低级的错误。。
job_hdfs_2_mysql.xml

在配置文件中,我已经将field_split字段赋值了,定义了以'\t'分割;
这个配置文件会将HdfsReader.java中的类变量fieldSplit重新赋值,可分三个阶段分析;
1、private char fieldSplit = '\u0001';定义类变量并赋初值;
2、调用xml,对fieldSplit重新赋值,fieldSplit='\t',值可在xml文件中设定
3、for (i = 0; i < s.length(); ++i) {
if (s.charAt(i) == fieldSplit) {
line.addField(replace(s.substring(begin, i)));
begin = i + 1;
}
调用fieldSplit字段,此时的值已经是'\t'
总结:
之前因为没有注意到这个xml的配置,更改了Datax的源代码;虽然功能上实现了数据的迁移,但是破坏了Datax代码的扩展性。在实际应用中,应该在xml文件中将field_split字段定义为变量,由脚本来赋值,不应该直接写死。目的是适应字段分隔符不同的HDFS文件。xml文件中还有一个line_split的字段,就实际应用来说,这个可以写死,因为一般的行分隔符都是'\n',没有适配的必要。
mysqlwriter
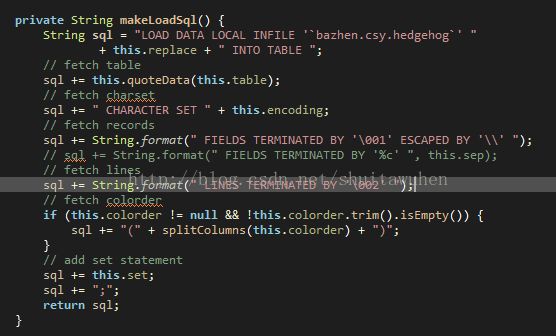
在mysqlwriter中,使用了LOAD DATA LOCAL INFILE这条sql语句,将数据一次性加载到mysql中,高效方便。
定义了导入mysql时的字段分隔符、行分隔符
注册插件
在conf/plugins.xml中,添加配置项,注册插件
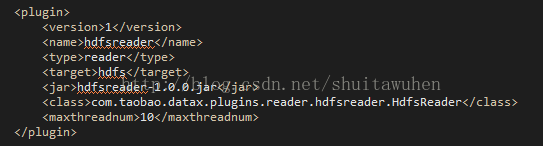
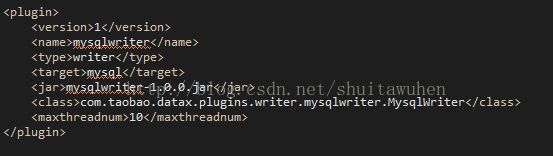
修改build.xml文件,并执行ant命令将插件打成jar包

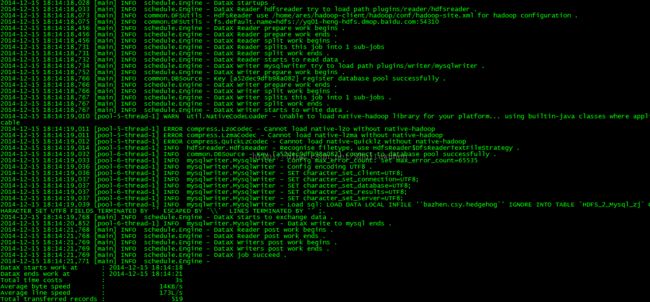
Datax运行结果: