python︱大规模数据存储与读取、并行计算:Dask库简述
数据结构与pandas非常相似,比较容易理解。
- 原文文档:http://dask.pydata.org/en/latest/index.html
github:https://github.com/dask
dask的内容很多,挑一些我比较看好的内容着重点一下。
.

一、数据读取与存储
先来看看dask能读入哪些内容:
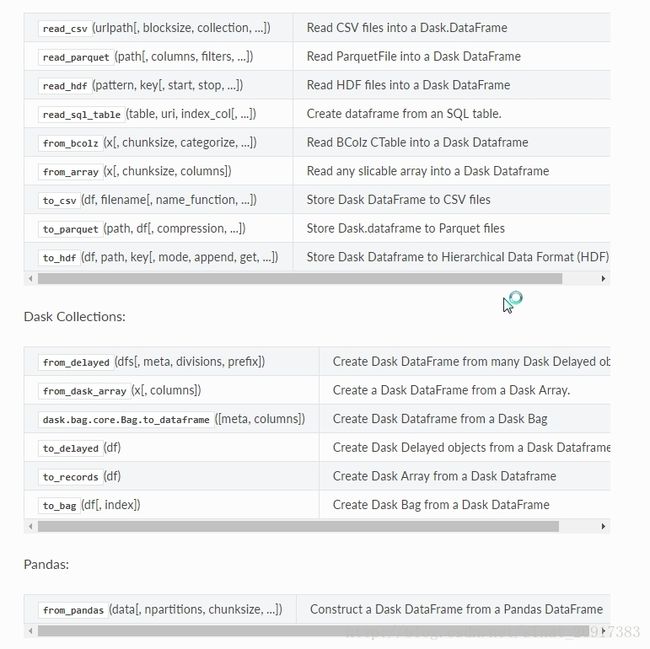
1、csv
dask并不能读入excel,这个注意
# pandas
import pandas as pd
df = pd.read_csv('2015-01-01.csv')
df.groupby(df.user_id).value.mean()
#dask
import dask.dataframe as dd
df = dd.read_csv('2015-*-*.csv')
df.groupby(df.user_id).value.mean().compute()非常相似,除了.compute()
.
2、Dask Array读取hdf5
import numpy as np import dask.array as da
f = h5py.File('myfile.hdf5') f = h5py.File('myfile.hdf5')
x = np.array(f['/small-data']) x = da.from_array(f['/big-data'],
chunks=(1000, 1000))
x - x.mean(axis=1) x - x.mean(axis=1).compute()左是Pandas,右边是dask
.
3、Dask Bag
import dask.bag as db
b = db.read_text('2015-*-*.json.gz').map(json.loads)
b.pluck('name').frequencies().topk(10, lambda pair: pair[1]).compute()读取大规模json文件,几亿都很easy
>>> b = db.read_text('myfile.txt')
>>> b = db.read_text(['myfile.1.txt', 'myfile.2.txt', ...])
>>> b = db.read_text('myfile.*.txt')读取txt
>>> import dask.bag as db
>>> b = db.from_sequence([{'name': 'Alice', 'balance': 100},
... {'name': 'Bob', 'balance': 200},
... {'name': 'Charlie', 'balance': 300}],
... npartitions=2)
>>> df = b.to_dataframe()变为dataframe格式的内容
.
4、Dask Delayed 并行计算
from dask import delayed
L = []
for fn in filenames: # Use for loops to build up computation
data = delayed(load)(fn) # Delay execution of function
L.append(delayed(process)(data)) # Build connections between variables
result = delayed(summarize)(L)
result.compute().
5、concurrent.futures自定义任务
from dask.distributed import Client
client = Client('scheduler:port')
futures = []
for fn in filenames:
future = client.submit(load, fn)
futures.append(future)
summary = client.submit(summarize, futures)
summary.result().
二、Delayed 并行计算模块
一个先行例子,本来的案例:
def inc(x):
return x + 1
def double(x):
return x + 2
def add(x, y):
return x + y
data = [1, 2, 3, 4, 5]
output = []
for x in data:
a = inc(x)
b = double(x)
c = add(a, b)
output.append(c)
total = sum(output)再来看看用delay加速的:
from dask import delayed
output = []
for x in data:
a = delayed(inc)(x)
b = delayed(double)(x)
c = delayed(add)(a, b)
output.append(c)
total = delayed(sum)(output)还可以将计算流程可视化:
total.visualize() # see image to the right.
三、和SKLearn结合的并行算法
广义回归GLM:https://github.com/dask/dask-glm
tensorflow深度学习库:Dask-Tensorflow
以XGBoost为例,官方:https://github.com/dask/dask-xgboost
来看一个案例code
.
1、加载数据
import dask.dataframe as dd
# Subset of the columns to use
cols = ['Year', 'Month', 'DayOfWeek', 'Distance',
'DepDelay', 'CRSDepTime', 'UniqueCarrier', 'Origin', 'Dest']
# Create the dataframe
df = dd.read_csv('s3://dask-data/airline-data/20*.csv', usecols=cols,
storage_options={'anon': True})
df = df.sample(frac=0.2) # we blow out ram otherwise
is_delayed = (df.DepDelay.fillna(16) > 15)
df['CRSDepTime'] = df['CRSDepTime'].clip(upper=2399)
del df['DepDelay']
df, is_delayed = persist(df, is_delayed)
progress(df, is_delayed)2、One hot encode编码
df2 = dd.get_dummies(df.categorize()).persist()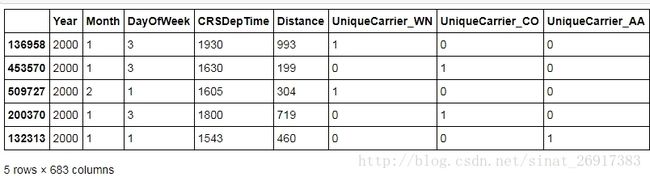
.
3、准备训练集和测试集 + 训练
data_train, data_test = df2.random_split([0.9, 0.1],
random_state=1234)
labels_train, labels_test = is_delayed.random_split([0.9, 0.1],
random_state=1234)训练
import dask_xgboost as dxgb
params = {'objective': 'binary:logistic', 'nround': 1000,
'max_depth': 16, 'eta': 0.01, 'subsample': 0.5,
'min_child_weight': 1}
bst = dxgb.train(client, params, data_train, labels_train)
bst.
4、预测
# Use normal XGBoost model with normal Pandas
import xgboost as xgb
dtest = xgb.DMatrix(data_test.head())
bst.predict(dtest)predictions = dxgb.predict(client, bst, data_test).persist()
predictions.head().
5、模型评估
from sklearn.metrics import roc_auc_score, roc_curve
print(roc_auc_score(labels_test.compute(),
predictions.compute()))
import matplotlib.pyplot as plt
%matplotlib inline
fpr, tpr, _ = roc_curve(labels_test.compute(), predictions.compute())
# Taken from http://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html#sphx-glr-auto-examples-model-selection-plot-roc-py
plt.figure(figsize=(8, 8))
lw = 2
plt.plot(fpr, tpr, color='darkorange', lw=lw, label='ROC curve')
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()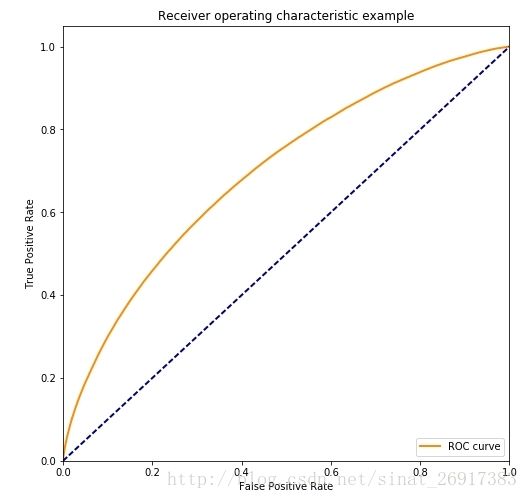
.
四、计算流程可视化部分——Dask.array
来源:https://gist.github.com/mrocklin/b61f795004ec0a70e43de350e453e97e
import numpy as np
import dask.array as da
x = da.ones(15, chunks=(5,))
x.visualize('dask.svg')
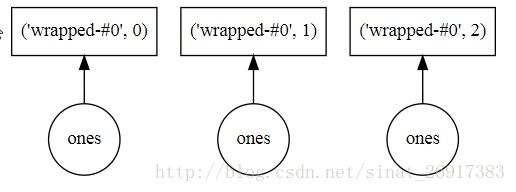
(x + 1).sum().visualize('dask.svg')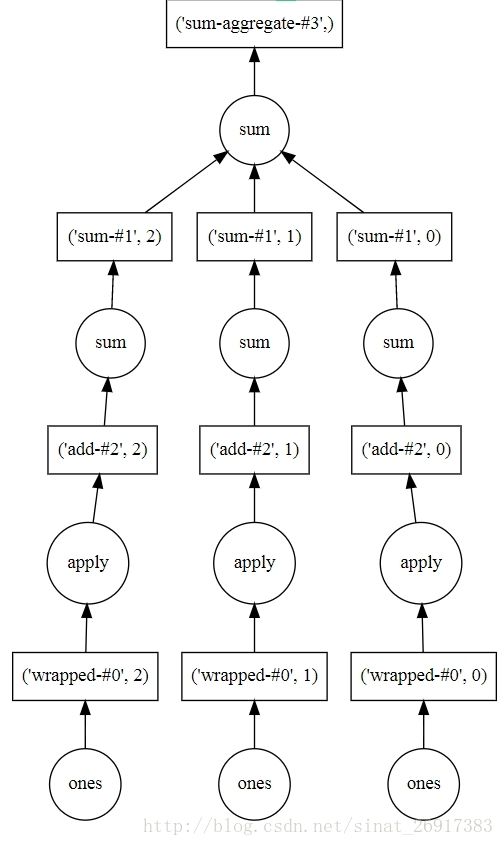
来一个二维模块的:
x = da.ones((15, 15), chunks=(5, 5))
x.visualize('dask.svg')
(x.dot(x.T + 1) - x.mean(axis=0)).std().visualize('dask.svg')