医学图像分割——Unet
这是一个学习记录博~可能有错,欢迎讨论
P.S. 本文所用的unet源码来自Unet源码。
目标
实现胃部超声图像的病灶分割
医学数据以及预处理简介
医学图像的数据格式十分复杂,数据形式有什么CT图像,MRI图像(目前还没接触过~),超声图像等(详细信息可以参考:医学图像了解。),而数据格式上有诸如dicom(.dcm,.IMA,常用的python处理库有:SimpleITK, pydicom库),Nifit(.nii或.nii.gz,常用的python处理库有:SimpleITK, nibabel库),NRRD(.nrrd,常用的python处理库有:SimpleITK,pynrrd库)等。
这里再插一句,对于CT图像呢,有图像值与HU值这个概念,CT值属于医学领域的概念,通常称亨氏单位(hounsfield unit ,HU),反映了组织对X射线吸收程度,范围一般是[-1024,3071]。图像值属于计算机领域的概念,例如灰度图像的范围一般是[0,255]。
在网上有看到这样的解释(CT图像之Hu值变换与窗宽窗位调整):
对于nii格式的图片,经过测试,nibabel, simpleitk常用的api接口,都会自动的进行上述转化过程,即取出来的值已经是Hu了。(除非专门用nib.load('xx').dataobj.get_unscaled()或者itk.ReadImage('xx').GetPixel(x,y,z)才能取得原始数据)
对于dcm格式的图片,经过测试,simpleitk, pydicom常用的api接口都不会将原始数据自动转化为Hu!!(itk snap软件读入dcm或nii都不会对数据进行scale操作)
但我认为这个解释不是很对,因为我用simpleItk读取dcm格式的数据时,得出来的值就是Hu值(我也不太明白为什么),所以我觉得大家还是把数据打印出来看看,自己判断一下是不是需要转Hu值吧。
对CT图像,在Hu值这个问题解决好之后,就要进行窗宽窗位的预处理了(窗宽窗位的解释参考来自CT图像之Hu值变换与窗宽窗位调整)。窗宽(window width)和窗位(window center),是用于选择感兴趣的CT值范围的,因为各种组织结构或病变具有不同的CT值,因此想要获得某一组织结构的最佳显示时,要选择适合观察该组织或病变的窗宽和窗位。
举个例子,CT原图可能是这样的:

而在选取了窗宽窗位并对原图进行了clip之后的图是这样的:
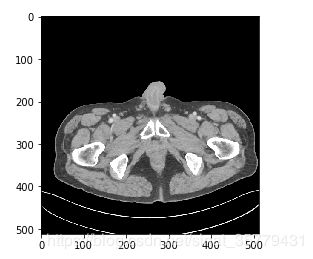
是不是清晰了很多呢。
本实验数据及预处理
实验数据
实验使用的数据为胃部超声图像,这里使用的超声数据是一般导出jpg格式的(一般会转成nrrd或者dcm来勾画病灶)。
数据预处理
增强对比度
超声图像有的会比较暗,需要增加一下对比度的话可以使用如python+opencv直方图均衡化,以及tensorflow中常见的图片预处理操作等方法。
数据增强
数据量不够的情况下需要进行数据增强,可以使用keras中的Data generator来进行操作,具体做法可以参考Unet源码。
提取包含病灶的slices
CT图像一般都很多的slices组成,很多时候病灶不会在全部的slices上出现,所以需要我们提取一下包含有病灶的slices,虽然本实验不涉及这个问题,但还是介绍一下吧。这个过程呢,就是检测一下mask数据,看一下在该层slice上是否有病灶出现,有就保留该slice,没有就舍弃。
def getRangImageDepth(image):
"""
args:
image ndarray of shape (depth, height, weight)
"""
# 得到轴向上出现过目标(label>=1)的切片
### image.shape为(depth,height,width),否则要改axis的值
z = np.any(image, axis=(1,2)) # z.shape:(depth,)
### np.where(z)[0] 输出满足条件,即true的元素位置,返回为一个列表,用0,-1取出第一个位置和最后一个位置的值
startposition,endposition = np.where(z)[0][[0,-1]]
return startposition, endposition
Unet训练中需要注意的几个点
这个Unet源码是用keras写的,代码比较简单易懂,所以这里不对代码做过多的介绍,如有问题,可以下面留言,这里只记录一下容易踩坑的点~
图像的位深
如果采用的数据是jpg格式的,可能会有图像位深问题的存在,从而导致预测失败,具体可以参考Unet训练自己的数据集,预测结果全黑。
检查数据类型
在这个Unet源码的data.py文件中有对图像做一些预处理,比如reshape成网络所需的4维张量,以及对图像/255以将uint8转为网络所需的float型,这个根据自己的数据可能需要对代码进行一些修改,所以不要忘记检查这部分。
输入图像大小的设置
unet中会下采样4次,并且还要在上采样时还要与下采样中的特征图进行concatenate,因此,当图片的size在下采样时不能一直维持在偶数时,上采样进行特征结合就会出现问题。例如,37x37的下采样变成了18x18,而18x18在上采样时会变成36x36,在进行concatenate时,36x36和37x37就会出现大小不匹配的问题。
对于这个问题,简单一点的解决方法就是把图片设置成每次下采样都能满足偶数的大小,如256x256;如果不想这样的话,我们也可以用tf.pad对图像张量进行填充,举例:
### 判断concatenate的特征图大小是否一致
if drop4.get_shape().as_list() != up6.get_shape().as_list():
# _,height, width, depth = up6.shape
# 只要你使用Model,就必须保证该函数内全为layer,不能有其他函数,如果有其他函数必须用Lambda封装为layer
up6_padded = Lambda(lambda x: tf.pad(x, [[0, 0], [1, 0], [0, 0], [0, 0]], 'REFLECT'))(up6)
merge6 = concatenate([drop4, up6_padded], axis=3)
else:
merge6 = concatenate([drop4, up6], axis=3)
这里对tf.pad进行一下简要说明,
tf.pad(
tensor,
paddings,
mode='CONSTANT',
name=None
)
- tensor是待填充的张量
- paddings指出要给tensor的哪个维度进行填充,以及填充方式,要注意的是paddings的rank必须和tensor的rank相同
- mode指出用什么进行填充,可以取三个值,分别是"CONSTANT" ,“REFLECT”,“SYMMETRIC,mode=“CONSTANT” 填充0;mode="REFLECT"映射填充,按边缘翻且不复制边缘;mode="SYMMETRIC"对称填充,从对称轴开始复制,把边缘也复制了。
- name是这个节点的名字
在本实验中,我们的tensor是一个四维张量, [[0, 0], [1, 0], [0, 0], [0, 0]]分别对应[,height,width,depth],0表示不进行填充, [1, 0]表示对在图片上边填充一行,下边不填充,如果设置为[1,1]的话就代表在图片上下各填充1行;同样的,如果width为[2,3]就表示在图片的左边填充2列,右边填充3列。
更换loss函数
Unet源码中采用的是交叉熵损失来进行训练的,对于医学图像而言,有时候需要分割的病灶很小,这时候使用交叉熵损失有训练失败的可能,需要更换loss函数,这里有一个讲解的比较详细的博客,可以参考一下,从loss处理图像分割中类别极度不均衡的状况—keras。
例如将交叉熵损失换成Dice loss,具体做法为:
def dice_coef(y_true, y_pred, smooth=1):
intersection = K.sum(y_true * y_pred, axis=[1,2,3])
union = K.sum(y_true, axis=[1,2,3]) + K.sum(y_pred, axis=[1,2,3])
return K.mean( (2. * intersection + smooth) / (union + smooth), axis=0)
def dice_coef_loss(y_true, y_pred):
return 1 - dice_coef(y_true, y_pred, smooth=1)
然后将modle.compile改一下:
model.compile(optimizer = Adam(lr = 1e-5), loss = dice_coef_loss, metrics = [dice_coef])
更改学习率、batchsize和epoch
学习率不对也可能会导致预测失败,所以需要自己调整,然后在测试看看。
还有batchsize和epoch也要根据自己的数据集的情况进行调整。
emmm…暂时就这么多啦~