Python基础语法(五)—常用模块和模块的安装和导入
Python基础语法(五)—常用模块的使用和模块的安装和导入,本文介绍的Python模块有:os、sys、time、datetime、random、pickle、json、hashlib、shutil、re。
原文:https://blog.zeruns.tech/archives/581.html
Python基础语法(一):https://blog.zeruns.tech/archives/54.html
Python基础语法(二):https://blog.zeruns.tech/archives/112.html
Python基础语法(三)——函数:https://blog.zeruns.tech/archives/150.html
Python基础语法(四)—列表、元组、字典、集合、字符串:https://blog.zeruns.tech/archives/299.html
什么是模块?
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就可以称之为一个模块(Module)。
使用模块有什么好处?
- 最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
- 使用模块还可以避免函数名和变量名冲突。每个模块有独立的命名空间,因此相同名字的函数和变量完全可以分别存在不同的模块中,所以,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
模块分类
模块分为三种:
- 内置标准模块(又称标准库)执行help(‘modules’)查看所有python自带模块列表
- 第三方开源模块,可通过
pip install 模块名联网安装 - 自定义模块
第三方开源模块的安装使用
https://pypi.org/ 是python的开源模块库,截止2020年7.31日 ,已经收录了253763个来自全世界python开发者贡献的模块,几乎涵盖了你想用python做的任何事情。 事实上每个python开发者,只要注册一个账号就可以往这个平台上传你自己的模块,这样全世界的开发者都可以容易的下载并使用你的模块。
那如何从这个平台上下载安装模块呢?
1.直接在上面这个页面上点 Download files,下载后,解压并进入目录,执行以下命令完成安装
python setup.py build #编译源码
python setup.py install #安装源码
2.直接通过pip安装
pip3 install requests #paramiko 是模块名
pip命令会自动下载模块包并完成安装。
软件一般会被自动安装你python安装目录的这个子目录里
\你的Python安装目录\Lib\site-packages
pip命令默认会连接在国外的python官方服务器下载,速度比较慢,你还可以使用国内的清华大学源,数据会定期同步国外官网,速度快好多
windows
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
centos
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
模块导入&调用
import random #导入整个random模块
from random import randint #导入 random 模块里的 randint 函数
from random import randint as suijishu ##导入 random 模块里的 randint 函数并重命名为 suijishu
from random import * #导入random模块下的所有方法(调用时无需输入random这个前缀),不建议使用
random.xxx #调用
注意:模块一旦被调用,即相当于执行了另外一个py文件里的代码
自定义模块
这个最简单, 创建一个.py文件,就可以称之为模块,就可以在另外一个程序里导入
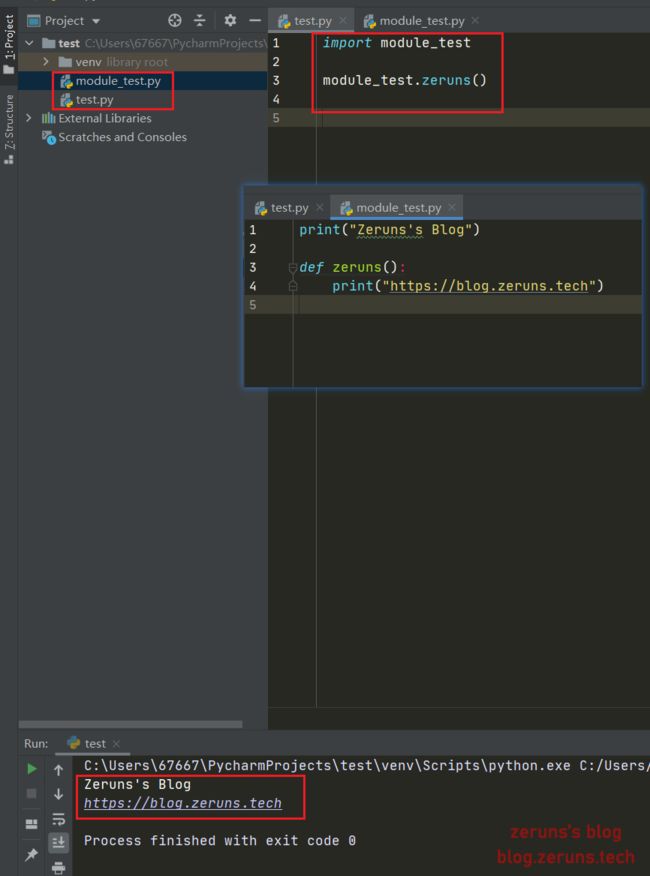
模块查找路径
发现,自己写的模块只能在当前路径下的程序里才能导入,换一个目录再导入自己的模块就报错说找不到了, 这是为什么?
这与导入模块的查找路径有关
import sys
print(sys.path)
输出(注意不同的电脑可能输出的不太一样)
['C:\\Users\\67667\\PycharmProjects\\test',
'C:\\Users\\67667\\AppData\\Local\\Programs\\Python\\Python38-32\\python38.zip', 'C:\\Users\\67667\\AppData\\Local\\Programs\\Python\\Python38-32\\DLLs', 'C:\\Users\\67667\\AppData\\Local\\Programs\\Python\\Python38-32\\lib', 'C:\\Users\\67667\\AppData\\Local\\Programs\\Python\\Python38-32', 'C:\\Users\\67667\\PycharmProjects\\test\\venv', 'C:\\Users\\67667\\PycharmProjects\\test\\venv\\lib\\site-packages']
你导入一个模块时,Python解释器会按照上面列表顺序去依次到每个目录下去匹配你要导入的模块名,只要在一个目录下匹配到了该模块名,就立刻导入,不再继续往后找。
注意列表第一个元素是当前目录,所以你自己定义的模块在当前目录会被优先导入。
我们自己创建的模块若想在任何地方都能调用,那就得确保你的模块文件至少在模块路径的查找列表中。
我们一般把自己写的模块放在一个带有“site-packages”字样的目录里,我们从网上下载安装的各种第三方的模块一般都放在这个目录。
系统调用
os模块
os模块提供了很多允许你的程序与操作系统直接交互的功能
import os
得到当前工作目录,即当前Python脚本工作的目录路径:os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真的存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split()
例如:os.path.split('/home/swaroop/byte/code/poem.txt') 结果:('/home/swaroop/byte/code', 'poem.txt')
分离扩展名:os.path.splitext()
例如:os.path.splitext('/usr/local/test.py') 结果:('/usr/local/test', '.py')
获取路径名:os.path.dirname()
获得绝对路径: os.path.abspath()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取操作系统环境变量HOME的值:os.getenv("HOME")
返回操作系统所有的环境变量:os.environ
设置系统环境变量,仅程序运行时有效:os.environ.setdefault('HOME','/home/alex')
给出当前平台使用的行终止符:os.linesep Windows使用'\r\n',Linux and MAC使用'\n'
指示你正在使用的平台:os.name 对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'
重命名:os.rename(old,new)
创建多级目录:os.makedirs(r"c:\python\test")
创建单个目录:os.mkdir("test")
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
获取文件大小:os.path.getsize(filename)
结合目录名与文件名:os.path.join(dir,filename)
改变工作目录到dirname: os.chdir(dirname)
获取当前终端的大小: os.get_terminal_size()
杀死进程: os.kill(10884,signal.SIGKILL)

sys模块
import sys
sys.argv #命令行参数List,第一个元素是程序本身路径
sys.exit(n) #退出程序,正常退出时exit(0)
sys.version #获取Python解释程序的版本信息
sys.maxint #最大的Int值
sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform #返回操作系统平台名称
sys.stdout.write('please:') #标准输出 , 引出进度条的例子, 注,在py3上不行,可以用print代替
val = sys.stdin.readline()[:-1] #标准输入
sys.getrecursionlimit() #获取最大递归层数
sys.setrecursionlimit(1200) #设置最大递归层数
sys.getdefaultencoding() #获取解释器默认编码
sys.getfilesystemencoding #获取内存数据存到文件里的默认编码
时间模块 time 和 datetime
time模块
在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp), 表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。例子:1596258440.116188
- 格式化的时间字符串,比如“2020-08-01 13:07:20”
- 元组(struct_time)共九个元素。由于Python的time模块实现主要调用C库,所以各个平台可能有所不同,Windows上:time.struct_time(tm_year=2020, tm_mon=8, tm_mday=1, tm_hour=13, tm_min=10, tm_sec=43, tm_wday=5, tm_yday=214, tm_isdst=0)
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2020 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 59 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为-1 |
UTC时间
UTC(Coordinated Universal Time,世界协调时)亦即格林威治天文时间,世界标准时间。在中国为UTC+8,又称东8区。DST(Daylight Saving Time)即夏令时。
time模块的方法
-
time.localtime([secs]):将一个时间戳转换为当前时区的struct_time。若secs参数未提供,则以当前时间为准。
-
time.gmtime([secs]):和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
-
time.time():返回当前时间的时间戳。
-
time.mktime(t):将一个struct_time转化为时间戳。
-
time.sleep(secs):线程推迟指定的时间运行,单位为秒。
-
time.asctime([t]):把一个表示时间的元组或者struct_time表示为这种形式:’Sun Oct 1 12:04:38 2019’。如果没有参数,将会将time.localtime()作为参数传入。
-
time.ctime([secs]):把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
-
time.strftime(format[, t]):把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。
- 举例:time.strftime("%Y-%m-%d %X", time.localtime()) 输出
2020-08-01 15:52:25
- 举例:time.strftime("%Y-%m-%d %X", time.localtime()) 输出
-
time.strptime(string[,format]):把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
-
举例:print(time.strptime(‘2020-08-01 15:52’,"%Y-%m-%d %H:%M"))
输出
time.struct_time(tm_year=2020, tm_mon=8, tm_mday=1, tm_hour=15, tm_min=52, tm_sec=0, tm_wday=5, tm_yday=214, tm_isdst=-1)
-
-
字符串转时间格式对应表
Meaning Notes %aLocale’s abbreviated weekday name. %ALocale’s full weekday name. %bLocale’s abbreviated month name. %BLocale’s full month name. %cLocale’s appropriate date and time representation. %dDay of the month as a decimal number [01,31]. %HHour (24-hour clock) as a decimal number [00,23]. %IHour (12-hour clock) as a decimal number [01,12]. %jDay of the year as a decimal number [001,366]. %mMonth as a decimal number [01,12]. %MMinute as a decimal number [00,59]. %pLocale’s equivalent of either AM or PM. (1) %SSecond as a decimal number [00,61]. (2) %UWeek number of the year (Sunday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Sunday are considered to be in week 0. (3) %wWeekday as a decimal number [0(Sunday),6]. %WWeek number of the year (Monday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Monday are considered to be in week 0. (3) %xLocale’s appropriate date representation. %XLocale’s appropriate time representation. %yYear without century as a decimal number [00,99]. %YYear with century as a decimal number. %zTime zone offset indicating a positive or negative time difference from UTC/GMT of the form +HHMM or -HHMM, where H represents decimal hour digits and M represents decimal minute digits [-23:59, +23:59]. %ZTime zone name (no characters if no time zone exists). %%A literal ‘%’character.
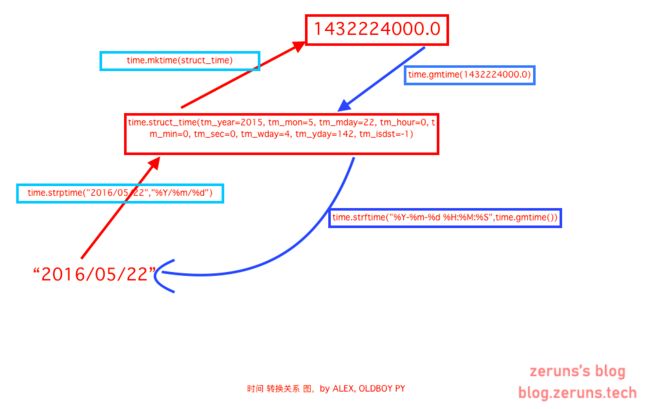
最后为了容易记住转换关系,看下图
datetime模块
相比于time模块,datetime模块的接口则更直观、更容易调用
datetime模块定义了下面这几个类:
- datetime.date:表示日期的类。常用的属性有year, month, day;
- datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond;
- datetime.datetime:表示日期时间。
- datetime.timedelta:表示时间间隔,即两个时间点之间的长度。
- datetime.tzinfo:与时区有关的相关信息。(这里不详细充分讨论该类,感兴趣的童鞋可以参考python手册)
我们需要记住的方法仅以下几个:
- d=datetime.datetime.now() 返回当前的datetime日期类型
d.timestamp(),d.today(),d.year,d.timetuple()等方法可以调用
- datetime.date.fromtimestamp(1596270517) 把一个时间戳转为datetime日期类型
- 时间运算
>>> print(datetime.datetime.now())
2020-08-01 16:30:24.940736
>>> datetime.datetime.now()
datetime.datetime(2020, 8, 1, 16, 30, 42, 475749)
>>> print(datetime.datetime.now() + datetime.timedelta(4)) #当前时间 +4天
2020-08-05 16:31:04.921738
>>> print(datetime.datetime.now() + datetime.timedelta(hours=4)) #当前时间 +4小时
2020-08-01 20:31:19.610740
- 时间替换
>>> print(d.replace(year=2999,month=11,day=30))
2999-11-30 16:28:37.857495
随机模块 random
程序中有很多地方需要用到随机字符,比如登录网站的随机验证码,通过random模块可以很容易生成随机字符串
>>> import random
>>> random.randrange(1,10) #返回1-10之间的一个随机数,不包括10
6
>>> random.randint(1,10) #返回1-10之间的一个随机数,包括10
6
>>> random.randrange(0, 100, 2) #随机选取0到100间的偶数
76
>>> random.random() #返回一个随机浮点数
0.9257294868672783
>>> random.choice('https://blog.zeruns.tech') #返回一个给定数据集合中的随机字符
'z'
>>> random.sample('https://blog.zeruns.tech',3) #从多个字符中选取特定数量的字符
['g', 'h', 'o']
#生成随机字符串
>>> import string
>>> ''.join(random.sample(string.ascii_lowercase + string.digits, 8))
'clvebqw4'
#重新排序
>>> a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> random.shuffle(a)
>>> a
[1, 9, 7, 0, 5, 8, 4, 2, 3, 6]
序列化模块 pickle 和 json
什么叫序列化?
序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes
为什么要序列化?
你打游戏过程中,打累了,停下来,关掉游戏、想过2天再玩,2天之后,游戏又从你上次停止的地方继续运行,你上次游戏的进度肯定保存在硬盘上了,是以何种形式呢?游戏过程中产生的很多临时数据是不规律的,可能在你关掉游戏时正好有10个列表,3个嵌套字典的数据集合在内存里,需要存下来?你如何存?把列表变成文件里的多行多列形式?那嵌套字典呢?根本没法存。所以,若是有种办法可以直接把内存数据存到硬盘上,下次程序再启动,再从硬盘上读回来,还是原来的格式的话,那是极好的。
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump、loads、load
import pickle
data = {'test':123,'url':'https://blog.zeruns.tech'}
# pickle.dumps 将数据通过特殊的形式转换位只有python语言认识的字符串
p_str = pickle.dumps(data) # 注意dumps会把数据变成bytes格式
print(p_str)
# pickle.dump 将数据通过特殊的形式转换位只有python语言认识的字符串,并写入文件
with open('result.pk',"wb") as fp: # 文件 result.pk 可以改成其他名字和后缀
pickle.dump(data,fp)
# pickle.load 从文件里加载
with open('result.pk',"rb") as f:
d = pickle.load(f)
print(d)
Json模块也提供了四个功能:dumps、dump、loads、load,用法跟pickle一致
import json
data = {'test':123,'url':'https://blog.zeruns.tech'}
# json.dumps 将数据通过特殊的形式转换位所有程序语言都认识的字符串
j_str = json.dumps(data) # 注意json dumps生成的是字符串,不是bytes
print(j_str)
#dump入文件
with open('config.json','w') as fp:
json.dump(data,fp)
#从文件里load
with open("config.json") as f:
d = json.load(f)
print(d)
json vs pickle:
JSON:
优点:跨语言(不同语言间的数据传递可用json交接)、体积小
缺点:只能支持int\str\list\tuple\dict
Pickle:
优点:专为python设计,支持python所有的数据类型
缺点:只能在python中使用,存储数据占空间大
摘要算法模块 hashlib
HASH
Hash,一般翻译做“散列”,也有直接音译为”哈希”的,就是把任意长度的输入(又叫做预映射,pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
HASH主要用于信息安全领域中加密算法,他把一些不同长度的信息转化成杂乱的128位的编码里,叫做HASH值.也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系
MD5
什么是MD5算法
MD5讯息摘要演算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码杂凑函数,可以产生出一个128位的散列值(hash value),用于确保信息传输完整一致。MD5的前身有MD2、MD3和MD4。
MD5功能
输入任意长度的信息,经过处理,输出为128位的信息(数字指纹);
不同的输入得到的不同的结果(唯一性);
MD5算法的特点
- 压缩性:任意长度的数据,算出的MD5值的长度都是固定的
- 容易计算:从原数据计算出MD5值很容易
- 抗修改性:对原数据进行任何改动,修改一个字节生成的MD5值区别也会很大
- 强抗碰撞:已知原数据和MD5,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
MD5算法是否可逆?
MD5不可逆的原因是其是一种散列函数,使用的是hash算法,在计算过程中原文的部分信息是丢失了的。
MD5用途
- 防止被篡改:
- 比如发送一个电子文档,发送前,我先得到MD5的输出结果a。然后在对方收到电子文档后,对方也得到一个MD5的输出结果b。如果a与b一样就代表中途未被篡改。
- 比如我提供文件下载,为了防止不法分子在安装程序中添加木马,我可以在网站上公布由安装文件得到的MD5输出结果。
- SVN在检测文件是否在CheckOut后被修改过,也是用到了MD5.
- 防止直接看到明文:
- 现在很多网站在数据库存储用户的密码的时候都是存储用户密码的MD5值。这样就算不法分子得到数据库的用户密码的MD5值,也无法知道用户的密码。(比如在UNIX系统中用户的密码就是以MD5(或其它类似的算法)经加密后存储在文件系统中。当用户登录的时候,系统把用户输入的密码计算成MD5值,然后再去和保存在文件系统中的MD5值进行比较,进而确定输入的密码是否正确。通过这样的步骤,系统在并不知道用户密码的明码的情况下就可以确定用户登录系统的合法性。这不但可以避免用户的密码被具有系统管理员权限的用户知道,而且还在一定程度上增加了密码被破解的难度。)
- 防止抵赖(数字签名):
- 这需要一个第三方认证机构。例如A写了一个文件,认证机构对此文件用MD5算法产生摘要信息并做好记录。若以后A说这文件不是他写的,权威机构只需对此文件重新产生摘要信息,然后跟记录在册的摘要信息进行比对,相同的话,就证明是A写的了。这就是所谓的“数字签名”。
SHA-1
安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准(Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA)。对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。当接收到消息的时候,这个消息摘要可以用来验证数据的完整性。
SHA是美国国家安全局设计的,由美国国家标准和技术研究院发布的一系列密码散列函数。
由于MD5和SHA-1于2005年被山东大学的教授王小云破解了,科学家们又推出了SHA224, SHA256, SHA384, SHA512,当然位数越长,破解难度越大,但同时生成加密的消息摘要所耗时间也更长。目前最流行的是加密算法是SHA-256 .
MD5与SHA-1的比较
由于MD5与SHA-1均是从MD4发展而来,它们的结构和强度等特性有很多相似之处,SHA-1与MD5的最大区别在于其摘要比MD5摘要长32 比特。对于强行攻击,产生任何一个报文使之摘要等于给定报文摘要的难度:MD5是2128数量级的操作,SHA-1是2160数量级的操作。产生具有相同摘要的两个报文的难度:MD5是264是数量级的操作,SHA-1 是280数量级的操作。因而,SHA-1对强行攻击的强度更大。但由于SHA-1的循环步骤比MD5多80:64且要处理的缓存大160比特:128比特,SHA-1的运行速度比MD5慢。
用于加密相关的操作
Python3.x里用hashlib代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512, MD5 算法
import hashlib
# md5
md5 = hashlib.md5()
md5.update(b"https://blog.zeruns.tech")
print(md5.digest()) # 返回2进制格式的hash值
print(md5.hexdigest()) # 返回16进制格式的hash值
# 如果数据量很大可以分多次调用update(),最后计算结果一样
md5 = hashlib.md5()
md5.update(b"https://")
md5.update(b"blog.zeruns.tech")
print(md5.hexdigest()) # 返回16进制格式的hash值
# sha1
s1 = hashlib.sha1()
s1.update(b"blog.zeruns.tech")
print(s1.hexdigest())
# sha256
s256 = hashlib.sha256()
s256.update(b"blog.zeruns.tech")
print(s256.hexdigest())
# sha512
s512 = hashlib.sha512()
s512.update(b"blog.zeruns.tech")
print(s512.hexdigest())
输出结果

文件复制模块 shutil
import shutil
# shutil.copyfileobj(fsrc, fdst[,length]) 将文件内容拷贝到另一个文件中
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
# shutil.copyfile(src, dst) 拷贝文件
shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
# shutil.copymode(src, dst) 仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
# shutil.copystat(src, dst) 仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
# shutil.copy(src, dst) 拷贝文件和权限
shutil.copy('f1.log', 'f2.log')
# shutil.copy2(src, dst) 拷贝文件和状态信息
shutil.copy2('f1.log', 'f2.log')
# shutil.ignore_patterns(*patterns)
# shutil.copytree(src, dst, symlinks=False, ignore=None) 递归的去拷贝文件夹
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
# 目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除(排除后缀为 pyc 的文件和文件名前面包含 tmp 的文件),填ignore=None则不排除任何文件
# shutil.rmtree(path[, ignore_errors[, onerror]]) 递归的去删除文件,删除整个目录(回收站无法找回)
shutil.rmtree('folder1')
# shutil.move(src, dst) 递归的去移动文件,它类似mv命令,其实就是重命名。
shutil.move('folder1', 'folder3')
shutil.make_archive(base_name, format,…)
创建压缩包并返回文件路径,例如:zip、tar
可选参数如下:
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
import shutil
#将当前目录下的data文件夹下的文件打包放置当前程序目录
ret = shutil.make_archive("data_bak", 'gztar', root_dir='data')
#将C盘data文件夹下的文件打包放置C:/tmp/目录
ret = shutil.make_archive("C:/tmp/data_bak", 'gztar', root_dir='C:/data')
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
zipfile压缩&解压缩
import zipfile
# 压缩
z = zipfile.ZipFile('abc.zip', 'w')
z.write('a.log')
z.close()
# 解压
z = zipfile.ZipFile('abc.zip', 'r')
z.extractall(path='.')
z.close()
tarfile压缩&解压缩
import tarfile
# 压缩
t = tarfile.open('/tmp/egon.tar','w')
t.add('/test1/a.py',arcname='a.bak')
t.add('/test1/b.py',arcname='b.bak')
t.close()
# 解压
t = tarfile.open('/tmp/egon.tar','r')
t.extractall('/egon')
t.close()
正则表达式 re模块
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能
正则表达式语法:https://www.runoob.com/regexp/regexp-syntax.html
re的匹配语法有以下几种
- re.match 从头开始匹配
- re.search 匹配包含
- re.findall 把所有匹配到的字符放到以列表中的元素返回
- re.split 以匹配到的字符当做列表分隔符
- re.sub 匹配字符并替换
- re.fullmatch 全部匹配
re.match(pattern, string, flags=0)
从起始位置开始根据模型去字符串中匹配指定内容,匹配单个
- pattern 正则表达式
- string 要匹配的字符串
- flags 标志位,用于控制正则表达式的匹配方式
import re
obj = re.match('\d+', '123uuasf456') #如果能匹配到就返回一个可调用的对象,否则返回None
if obj:
print(obj.group()) # 输出结果:123
Flags标志符
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- re.M(MULTILINE): 多行模式,改变’^’和’$’的行为
- re.S(DOTALL): 使 . 匹配包括换行在内的所有字符
- re.X(re.VERBOSE) 可以给你的表达式写注释,使其更可读.
re.search(pattern, string, flags=0)
根据模型去字符串中匹配指定内容,匹配单个
import re
obj = re.search('\d+', 'u123uu888asf')
if obj:
print(obj.group()) # 输出结果:123
re.findall(pattern, string, flags=0)
match and search均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
import re
obj = re.findall('\d+', 'fa123uu888asf')
print(obj) # 输出结果:['123', '888']
re.sub(pattern, repl, string, count=0, flags=0)
用于替换匹配的字符串,比str.replace功能更加强大
>>> re.sub('[a-z]+','666','blog.zeruns.tech 六六六',)
'666.666.666 六六六'
>>> re.sub('\d+','|', 'alex22wupeiqi33oldboy55',count=2)
'alex|wupeiqi|oldboy55'
re.split(pattern, string, maxsplit=0, flags=0)
用匹配到的值做为分割点,把值分割成列表
>>> s='9-2*5/3+7/3*99/4*2998+10*568/14'
>>> re.split('[\*\-\/\+]',s)
['9', '2', '5', '3', '7', '3', '99', '4', '2998', '10', '568', '14']
>>> re.split('[\*\-\/\+]',s,3)
['9', '2', '5', '3+7/3*99/4*2998+10*568/14']
re.fullmatch(pattern, string, flags=0)
整个字符串匹配成功就返回re object, 否则返回None
re.fullmatch('\w+@\w+\.(com|cn|edu)',"[email protected]")
正则表达式实例
字符匹配
| 实例 | 描述 |
|---|---|
| python | 匹配 “python”. |
字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 “Python” 或 “python” |
| rub[ye] | 匹配 “ruby” 或 “rube” |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
特殊字符类
| 实例 | 描述 |
|---|---|
| . | 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用象 ‘[.\n]’ 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于 [A-Za-z0-9_]。 |
| \W | 匹配任何非单词字符。等价于 [^A-Za-z0-9_]。 |
推荐阅读:
- 高性价比和便宜的VPS/云服务器推荐:https://blog.zeruns.tech/archives/383.html
- 搭建内网穿透服务器,带Web面板:https://blog.zeruns.tech/archives/397.html
- 使用Cloudreve自建网盘:https://blog.zeruns.tech/archives/515.html
- 怎样搭建个人博客:https://blog.zeruns.tech/archives/218.html
- 学生优惠权益大全:https://blog.zeruns.tech/archives/557.html
- Python实现阿里云域名DDNS支持ipv4和ipv6:https://blog.zeruns.tech/archives/507.html