前言:本篇关注Flink,对Fault Tolerance的源码实现进行阐述,主要介绍Api层及Flink现有实现。
本篇文章重点关注以下问题:
- 具备Fault Tolerance能力的两种对象:Function和Operator
-
分析两个接口,列举典型实现,并做简要分析
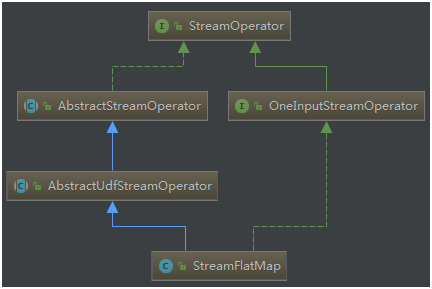
1. 具备Fault Tolerance能力的两种对象
- Function
- Operator
1.1 Function对象
org.apache.flink.api.common.functions.Function
所有用户自定义函数的基本接口,如已经预定义的FlatMapFunction就是基础自Function,Function并未定义任何方法,只是作为标识接口。
所有Function对象的Fault Tolerance都是通过继承CheckpointedFunction接口实现的,换话说,容错能力是Function的可选项,这点与Operator不同
1.2 Operator对象
org.apache.flink.streaming.api.operators.StreamOperator
所有Operator的基本接口,如已经预定义的StreamFilter、StreamFlatMap就是StreamOperator的实现。与Function是标识接口不同,StreamOperator内置了几个和检查点相关的接口方法,因此,在Operator中,容错能力是实现Operator的必选项,这点不难理解,因为Operator处于运行时时,诸如分区信息都是必要要做快照的。
2. CheckpointedFunction
org.apache.flink.streaming.api.checkpoint. CheckpointedFunction
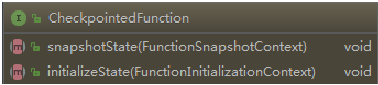
CheckpointedFunction接口是有状态转换函数的核心接口,两个接口方法:
- initializeState:Function初始化的时候调用,一般用作初始化state数据结构。
- snapshotState:请求state快照时被调用,方法签名中的参数FunctionSnapshotContext可以获取此Function中的所有State信息(快照),通过该上下文,可以获取该Function之前变更所产生的最终结果。
2.1 FlinkKafkaProducerBase
org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase

方法签名:
| public abstract class FlinkKafkaConsumerBase CheckpointListener, ResultTypeQueryable |
FlinkKafkaConsumerBase是Flink实现基于Kafka的Source的基类,Kafka提供基于offset并且可重复消费的机制,使其非常容易实现Fault Tolerance机制。
关键代码:
/** Consumer从各topic partitions读取的初始offsets. */
private Map subscribedPartitionsToStartOffsets;
/** 保存已消费的、但是Offset未提交至Broken或Zk的数据. */
private final LinkedMap pendingOffsetsToCommit = new LinkedMap();
/**
* 如果程序从Checkpoint启动,此变量保存此Consumer上次消费的offset
*
* 此变量主要由 {@link #initializeState(FunctionInitializationContext)} 进行赋值.
*
*/
private transient volatile TreeMap restoredState;
/** 在state backend上保存的State信息(Offset信息) . */
private transient ListState> unionOffsetStates;
@Override
public final void initializeState(FunctionInitializationContext context) throws Exception {
OperatorStateStore stateStore = context.getOperatorStateStore();
// 兼容1.2.0版本的State,可无视
ListState> oldRoundRobinListState =
stateStore.getSerializableListState(DefaultOperatorStateBackend.DEFAULT_OPERATOR_STATE_NAME);
// 各Partition的offset信息
this.unionOffsetStates = stateStore.getUnionListState(new ListStateDescriptor<>(
OFFSETS_STATE_NAME,
TypeInformation.of(new TypeHint>() {})));
if (context.isRestored() && !restoredFromOldState) {
restoredState = new TreeMap<>(new KafkaTopicPartition.Comparator());
// 兼容1.2.0版本的State,可无视
for (Tuple2 kafkaOffset : oldRoundRobinListState.get()) {
restoredFromOldState = true;
unionOffsetStates.add(kafkaOffset);
}
oldRoundRobinListState.clear();
if (restoredFromOldState && discoveryIntervalMillis != PARTITION_DISCOVERY_DISABLED) {
throw new IllegalArgumentException(
"Topic / partition discovery cannot be enabled if the job is restored from a savepoint from Flink 1.2.x.");
}
// 将待恢复的State信息保存进‘restoredState’变量中,以便程序异常时用于恢复
for (Tuple2 kafkaOffset : unionOffsetStates.get()) {
restoredState.put(kafkaOffset.f0, kafkaOffset.f1);
}
LOG.info("Setting restore state in the FlinkKafkaConsumer: {}", restoredState);
} else {
LOG.info("No restore state for FlinkKafkaConsumer.");
}
}
@Override
public final void snapshotState(FunctionSnapshotContext context) throws Exception {
if (!running) {
LOG.debug("snapshotState() called on closed source");
} else {
// 首先清空state backend对应offset的全局存储(State信息)
unionOffsetStates.clear();
// KafkaServer的连接器,根据Kafka版本由子类实现
final AbstractFetcher fetcher = this.kafkaFetcher;
if (fetcher == null) {
// 连接器还未初始化,unionOffsetStates的值从 restored offsets 或是 subscribedPartition上读取
for (Map.Entry subscribedPartition : subscribedPartitionsToStartOffsets.entrySet()) {
unionOffsetStates.add(Tuple2.of(subscribedPartition.getKey(), subscribedPartition.getValue()));
}
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) {
// 如果启用快照时同步提交Offset,则在初始化时,用restoredState给pendingOffsetsToCommit赋值
pendingOffsetsToCommit.put(context.getCheckpointId(), restoredState);
}
} else {
// 通过连接器获取当前消费的Offsets
HashMap currentOffsets = fetcher.snapshotCurrentState();
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) {
// 保存当前消费的Offset
pendingOffsetsToCommit.put(context.getCheckpointId(), currentOffsets);
}
// 给state backend对应offset的全局存储(State信息)赋值
for (Map.Entry kafkaTopicPartitionLongEntry : currentOffsets.entrySet()) {
unionOffsetStates.add(
Tuple2.of(kafkaTopicPartitionLongEntry.getKey(), kafkaTopicPartitionLongEntry.getValue()));
}
}
if (offsetCommitMode == OffsetCommitMode.ON_CHECKPOINTS) {
// pendingOffsetsToCommit的保护机制,最多存储100个元素,正也是此Map需要有序的原因
while (pendingOffsetsToCommit.size() > MAX_NUM_PENDING_CHECKPOINTS) {
pendingOffsetsToCommit.remove(0);
}
}
}
}
快照总结:
- initializeState方法从state backend中恢复State,并将相关信息保存入restoredState;
- snapshotState方法将当前准备放入state backend的state信息保存至unionOffsetStates,如果应用需要在快照的同时提交Offset,则将消费的Offset信息保存至pendingOffsetsToCommit。