TensofFlow学习记录:全局均值池化
全局均值池化就是在平均池化层中使用同等大小的过滤器将其特征保存下来。这种结构用来代替深层网络结构最后的全连接输出层。这个方法也是《Network In Network》论文中所论述的。
以下为《Network In Network》论文中关于全局均值池化的翻译,原文请点击这里
传统卷积神经网络在网络的较低层执行卷积。对于分类任务,最后一个卷积层得到的特征图被向量化然后送入全连接层,接一个softmax逻辑回归层。这种结构将卷积结构与传统神经网络分类器连接起来,卷积层作为特征提取器,得到的特征用传统方式进行分类。
但是,全连接层容易过拟合,从而阻碍了整个网络的泛化能力。后来dropout被Hinton等人提出,用于正则化,在训练过程中随机地将全连接层的一半激活值置零,改善了它的泛化能力并且很大程度地预防了过拟合。
在本文中,我们提出了另一个策略,叫做全局平均池化层,用它来替代CNN中的全连接层。想法是在最后一个mlpconv层生成一个分类任务中相应类别的特征图。我们没有在特征图最顶端增加全连接层,而是求每个特征图的平均值,得到的结果向量直接输入softmax层。
(论文原话:The idea is to generate one feature map for each correspondingcategory of the classification task in the last mlpconv layer. Instead of adding fully connected layerson top of the feature maps, we take the average of each feature map, and the resulting vector is feddirectly into the softmax layer.)。
GAP(Global Average Pooling)相比全连接层的优点在于通过增强特征图与类别间的对应关系使卷积结构保留的更好,使特征图分类是可信的得到很好的解释;另一个优点是GAP层中没有参数设置,因此避免了过拟合;此外,GAP汇聚了空间信息,所以对输入的空间转换更鲁棒。
我们可以看到GAP作为一个正则化器,加强了特征图与概念(类别)的可信度的联系。这是通过mlpconv层实现的,因为他们比GLM更好逼近置信图(conficence maps)。
在《Network In Network》论文中作者利用其进行了1000物体分类问题,最后设计了一个4层的MLPConv+全局均值池化网络,如下图所示:
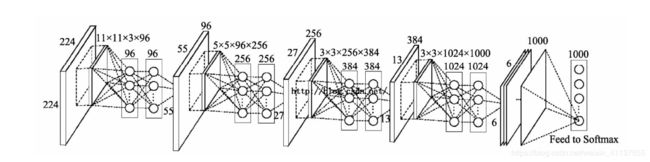
这里解释以下最后一个MLPConv层,它接受来自上一层输出的特征图,规格为13*13*384,在本MLPConv层中的卷积核规格为3*3*1024*1000,3代表卷积核的宽度和高度,1024表示卷积核的通道数,1000代表卷积核的数量,经过MLPConv层后得到的特征图规格为6*6*1000,表示有1000个特征图,每个特征图的维度为6*6,最后将这1000个特征图每个计算平局值,得到1000个数字,将这1000个数字送进Softmax函数。
实测:建立一个带有全局平均池化层的卷积神网络
建立一个用全局平均池化层取代全连接层的卷积神网络,该神经网络有3个卷积层,每个卷积层内卷积核的大小均为5*5,步长均为1,除了最后一个卷积层外,前面两个卷积层的后面都接一个池化层,每个池化层的核大小均为2*2,步长均为2。最后一个卷积层过后得到一个通道数为10的输出,将这个输出输入到全局平均池化层中,得到10个数字,再对这10个数字送进Softmax函数,其结果代表最终分类。
先编写Cifar10_data.py文件,用来预处理和读取图片
导入相关库和定义一些需要用到的变量
import os
import tensorflow as tf
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import numpy as np
import time
import math
num_classes = 10 #一共有10个类别
num_examples_pre_epoch_for_train = 50000 #50000个样本用于训练
num_examples_pre_epoch_for_eval = 10000 #10000个样本用于测试
max_steps = 4000 #训练4000步
batch_size = 100 #每次训练100个样本
num_examples_for_eval = 10000
data_dir = "C:/Users/Administrator/Desktop/Tensorflow/cifar-10-batches-bin" #下载的样本的路径
class CIFAR10Record(object): #定义一个空类,用于返回读取的Cifar-10数据
pass
接着定义一个read_cifar10()函数用于读取文件队列中的数据
def read_cifar10(file_queue): #file_queue为图片路径
result = CIFAR10Record() #创建一个CIFAR10Record对象
label_bytes = 1 #标签占一个字节
result.height = 32 #图像高为32像素
result.width = 32 #图像宽为32像素
result.depth = 3 #因为是RGB三通道,所以深度为3
image_bytes = result.height * result.width * result.depth #结果为3072,即一幅图像的大小为3072字节
record_bytes = label_bytes + image_bytes #加上标签,即一个样本一共有3073字节
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes) #使用FixedLengthRecordReader类创建一个用于读取固定长度字节数信息的对象(针对bin文件而言)
result.key, value = reader.read(file_queue) #使用该类的read()方法读取指定路径下的文件
#这里得到的value就是record_bytes长度的包含多个label数据和image数据的字符串
record_bytes = tf.decode_raw(value, tf.uint8)
#decode_raw()可以将字符串解析成图像对应的像素数组
#strided_slice(input,begin,end)用于对输入的input截取[begin,end)区间的数据
result.label = tf.cast(tf.strided_slice(record_bytes, [0], [label_bytes]), tf.int32)
#这里把record_bytes的第一个元素截取下来然后转换成int32类型的数
#剪切label之后剩下的就是图片数据,我们将这些数据的格式从[depth*height*width]转换为[depth,height,width]
depth_major = tf.reshape(tf.strided_slice(record_bytes, [label_bytes], [label_bytes + image_bytes]),
[result.depth, result.height, result.width])
#将[depth,height,width]的格式转换为[height,width,depth]的格式
result.uint8image = tf.transpose(depth_major, [1, 2, 0])
return result
紧接着read_cifar10()函数的是inputs函数,这个函数用于构建文件路径,将构建的文件路径传给read_cifar10()函数读取样本,对读取到的样本进行数据增强处理。
def inputs(data_dir, batch_size, distorted): #data_dir为文件路径,batch_size为读取批量大小,distorted是否对样本进行增强处理
#拼接文件名路径列表
filenames = [os.path.join(data_dir, "data_batch_%d.bin" % i) for i in range(1, 6)]
#创建一个文件队列,并调用read_cifar10()函数读取队列中的文件,在后面还要调用一个tf.train.start_queue_runners()函数才开始读取图片
file_queue = tf.train.string_input_producer(filenames)
read_input = read_cifar10(file_queue)
#使用tf.cast()对图片数据进行转换
reshaped_image = tf.cast(read_input.uint8image, tf.float32)
num_examples_per_epoch = num_examples_pre_epoch_for_train
if distorted != None:
#将[32,32,3]大小的图片随机剪裁成[24,24,3]的大小
cropped_image = tf.random_crop(reshaped_image, [24, 24, 3])
#随机左右翻转图片
flipped_image = tf.image.random_flip_left_right(cropped_image)
#随机调整亮度
adjusted_brightness = tf.image.random_brightness(flipped_image, max_delta=0.8)
#随机调整对比度
adjusted_contrast = tf.image.random_contrast(adjusted_brightness, lower=0.2, upper=1.8)
#对图片每一像素减去平均值并除以像素方差
float_image = tf.image.per_image_standardization(adjusted_contrast)
#设置图片及标签的形状
float_image.set_shape([24, 24, 3])
read_input.label.set_shape([1])
min_queue_examples = int(num_examples_pre_epoch_for_eval * 0.4)
print("Filling queue with %d CIFAR image before starting to train.""This will take a few minutes." % min_queue_examples)
#shuffle_batch()函数通过随机打乱张量的顺序创建批次.
images_train, labels_train = tf.train.shuffle_batch([float_image, read_input.label], batch_size=batch_size,
num_threads=16,
capacity=min_queue_examples + 3 * batch_size,
min_after_dequeue=min_queue_examples)
return images_train, tf.reshape(labels_train, [batch_size])
#不对图像进行数据增强处理
else:
resized_image = tf.image.resize_image_with_crop_or_pad(reshaped_image, 24, 24)
float_image = tf.image.per_image_standardization(resized_image)
float_image.set_shape([24, 24, 3])
read_input.label.set_shape([1])
min_queue_examples = int(num_examples_per_epoch * 0.4)
images_test, labels_test = tf.train.batch([float_image, read_input.label], batch_size=batch_size,
num_threads=16, capacity=min_queue_examples + 3 * batch_size)
return images_test, tf.reshape(labels_test, [batch_size])
接下来按照上面的描述设计卷积神经网络
import tensorflow as tf
import numpy as np
import Cifar10_data
batch_size = 32
data_dir = "/content/drive/My Drive/cifar-10-batches-bin"
print("begin:")
images_train,labels_train = Cifar10_data.inputs(data_dir=data_dir,batch_size=batch_size,distorted=True)
images_test,labels_test = Cifar10_data.inputs(data_dir=data_dir,batch_size=batch_size,distorted=False)
def weight_variable(shape):
inital = tf.truncated_normal(shape=shape,stddev=0.1)
return tf.Variable(inital)
def bias_variable(shape):
inital = tf.constant(0.1,shape=shape)
return tf.Variable(inital)
def conv2d(x,w):
return tf.nn.conv2d(x,w,strides=[1,1,1,1],padding="SAME")
def max_pool_2x2(x):
return tf.nn.max_pool(x,strides=[1,2,2,1],ksize=[1,2,2,1],padding="SAME")
def avg_pool_6x6(x):
return tf.nn.avg_pool(x,strides=[1,8,8,1],ksize=[1,8,8,1],padding="SAME")
x = tf.placeholder(tf.float32,[batch_size,32,32,3])
y = tf.placeholder(tf.float32,[batch_size])
W_conv1 = weight_variable([5,5,3,64])
b_conv1 = bias_variable([64])
h_conv1 = tf.nn.relu(conv2d(x,W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5,5,64,64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1,W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_conv3 = weight_variable([5,5,64,10])
b_conv3 = bias_variable([10])
h_conv3 = tf.nn.relu(conv2d(h_pool2,W_conv3) + b_conv3)
nt_hpool3 = avg_pool_6x6(h_conv3) #这里由[32,8,8,10]变成[32,1,1,10]
nt_hpool3_flat = tf.reshape(nt_hpool3,[-1,10]) #这里由[32,1,1,10]变成[32,10]
y_conv = tf.nn.softmax(nt_hpool3_flat)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=nt_hpool3_flat,labels=tf.cast(y,tf.int64))
loss = tf.reduce_mean(cross_entropy)
train_step = tf.train.AdamOptimizer(1e-4).minimize(loss)
correct_prediction = tf.equal(tf.argmax(y_conv,1),tf.cast(y,tf.int64))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float"))
config = tf.ConfigProto()
config.gpu_options.allocator_type = "BFC"
with tf.Session(config=config)as sess:
tf.global_variables_initializer().run()
tf.train.start_queue_runners()
for i in range(20000):
image_batch,label_batch = sess.run([images_train,labels_train])
_,loss_value = sess.run([train_step,loss],feed_dict={x:image_batch,y:label_batch})
if i %200 == 0:
print("step:%d,loss:%.3f"%(i,loss_value))
if i %1000 == 0:
train_accuracy = sess.run(accuracy,feed_dict={x:image_batch,y:label_batch})
print("step:%d,accuracy:%.3f"%(i,train_accuracy))
image_batch,label_batch = sess.run([images_test,labels_test])
test_accuracy = sess.run(accuracy,feed_dict={x:image_batch,y:label_batch})
print("test accuracy:%g"%(test_accuracy))
运行结果部分截图

参考书籍:《深度学习之TensorFlow入门,原理与进阶实践》 李金洪 编著