爬取美团APP外卖信息( fiddle scrapy packet captur)
爬取美团APP外卖信息(fiddle,packet capture
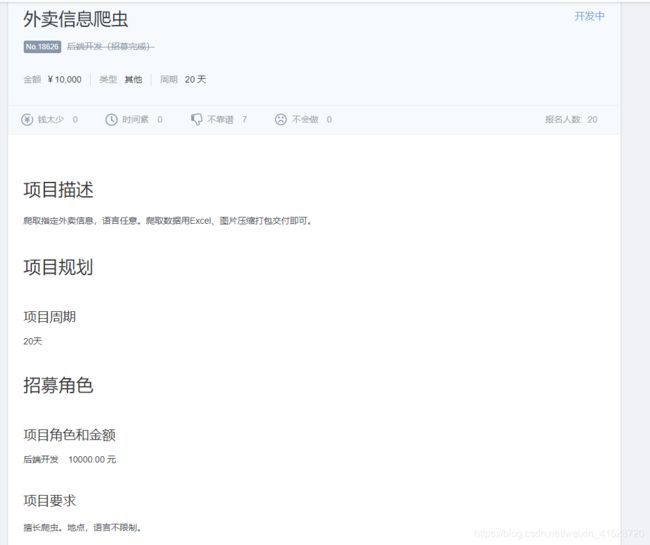
偶然看到一个项目帖子,虽然已经招募完成了,但是还是想自己做一下,结果还可以,基本上能完成项目里的要求,也算是初学者的第一个项目经验了吧!哈哈哈
下面是项目帖子截图
[外链图片转存失败(img-OuDYPdMz-1563785463719)(E:\CSDN 博客\外卖信息\QQ截图20190718181533.png)]
项目分析
1.这次想试试抓取APP上的信息,所以需要手机App的抓包工具,fiddle或者packet capture
抓包工具的配置和使用网上有例子,这里就不做介绍,附上链接
fiddler的使用介绍
https://blog.csdn.net/WsXOM853BD45Fm92B0L/article/details/80416546
或者https://blog.csdn.net/qq_31050167/article/details/83387034
packet capture 使用介绍 https://zhuanlan.zhihu.com/p/46433599
本次在使用fiddler抓包时遇见了总是抓取不到美团App数据的response
[外链图片转存失败(img-kAfdnsrl-1563785463720)(E:\CSDN 博客\外卖信息\fiddle.png)]
能抓到的基本上都是一些图片信息,所以我又换的packet capture,唯一的缺点是,在抓包时,抓到的没用的没数据的请求太多,分析起来有点麻烦,但是抓包抓的就很全了,基本上所有的包都被抓下来了。最后也找到了数据包。


2.分析url构造请求
抓取到的url
商家列表的url
GET /meishi/filter/v7/deal/select?wifi-name=&offset=0&ci=10&wifi-strength=&cityId=10&sort=defaults&flyName=4%E6%8A%98&wifi-cur=-1&isLocal=0&mypos=31.35548627129277%2C121.76778813515155&wifi-mac=&cateId=1&hasGroup=true&metrics_start_time=118337984&utm_source=hs1&utm_medium=android&utm_term=1000000801&version_name=10.0.801&utm_content=868488033376888&utm_campaign=AgroupBgroupC0D200E0Ghomepage_category1_1__a1__c-1024__e5308__gfood&msid=8684880333768881563613197803&uuid=0000000000000A80359FC7F904ABE9B210AEBE93CA6B2A153437614502539080&userid=1929054414&__reqTraceID=b8f47c37-21cb-48d1-a6a2-d63d8b12b2b7&__skck=8f5973b085446090f224af74e30e0181&__skts=1563613209&__skua=768753b4caa4f70205d96fa528c1c662&__skno=d4261da5-26b0-454b-8ab5-c6f95e8c3dbd&__skcy=mQBflW9xSDNCzLI1PMcqke9xkhs%3D HTTP/1.1
商家信息的url
/meishi/poi/v2/poi/base/111588335?lng=121.76776716314316&uuid=0000000000000A80359FC7F904ABE9B210AEBE93CA6B2A153437614502539080&lat=31.355589315391256&partner=126&uuid=0000000000000A80359FC7F904ABE9B210AEBE93CA6B2A153437614502539080&platform=4&version=10.0.801&app=0&utm_source=hs1&utm_medium=android&utm_term=1000000801&version_name=10.0.801&utm_content=868488033376888&utm_campaign=AgroupBgroupC0D200E122211242926694302711859188224810851193_a111588335_c0_e6151481600053475502Ghomepage_category1_1__a1__c-1024__gfood__hpoilist__i0&ci=10&msid=8684880333768881563619085663&userid=1929054414&__reqTraceID=f884dfc8-de43-402e-85ed-c359b98d98cb&__skck=8f5973b085446090f224af74e30e0181&__skts=1563621751&__skua=768753b4caa4f70205d96fa528c1c662&__skno=2988e482-807e-40e4-a8b1-71c67e0de863&__skcy=RSzAiR5oKJp6xzULEG2yHcNj1DQ%3D HTTP/1.1
商家评论的url
/meishi/poi/v2/poi/comment/list/111588335?userid=1929054414&token=WXfGNyZasGZlSjnIOIJqQL4qfgMAAAAAuggAAHlj_iL9ZY9ka4tp1CFrKxrAi2alFGEaH1AApkRncIsrLoO9-uZeZZlKRtD3BH5h8A&partner=126&uuid=0000000000000A80359FC7F904ABE9B210AEBE93CA6B2A153437614502539080&platform=4&version=10.0.801&app=0&utm_source=hs1&utm_medium=android&utm_term=1000000801&version_name=10.0.801&utm_content=868488033376888&utm_campaign=AgroupBgroupC0D200E122211242926694302711859188224810851193_a111588335_c0_e6151481600053475502Ghomepage_category1_1__a1__c-1024__gfood__hpoilist__i0&ci=10&msid=8684880333768881563619085663&__reqTraceID=9e4cc902-3c88-4293-9227-6e0757505648&__skck=8f5973b085446090f224af74e30e0181&__skts=1563621752&__skua=768753b4caa4f70205d96fa528c1c662&__skno=0497b5d8-3d52-4974-92e9-922d5f83161e&__skcy=oY96L10RG%2BH4Qezpm1LsQ0XPV3A%3D HTTP/1.1
在反复分析以后,最终确定的url
http://apimeishi.meituan.com/meishi/filter/v7/deal/select?offset=偏移&ci=10&mypos=31.35548627129277%2C121.76778813515155&metrics_start_time='+时间戳
'http://apimeishi.meituan.com/meishi/poi/v2/poi/base/'商家的ID uuid=0000000000000A80359FC7F904ABE9B210AEBE93CA6B2A153437614502539080&utm_medium=android&version_name=10.0.801'
'http://apimeishi.meituan.com/meishi/poi/v2/poi/comment/list/'+ 商家ID
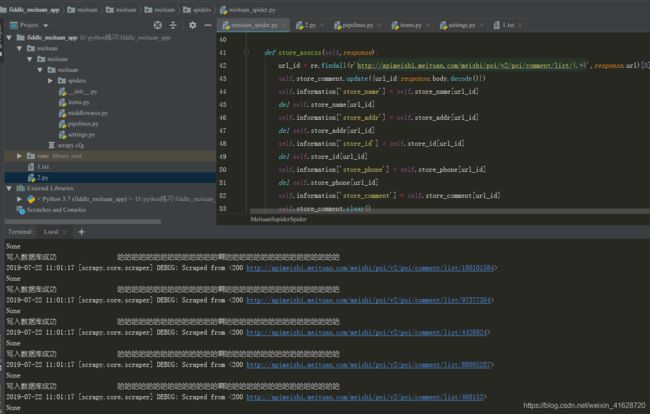
接下来就是写代码了(用的还是scrapy框架)筛选信息啦
import scrapy
import re
import time
from .. import items
class MeituanSspiderSpider(scrapy.Spider):
name = 'meituan'
store_id = {}
store_name = {}
store_addr = {}
store_phone = {}
store_comment = {}
num = 0
information = items.MeituanItem()
# start_urls = ['http://apimeishi.meituan.com/meishi/filter/v7/deal/select?offset=50&ci=10&mypos=31.35548627129277%2C121.76778813515155&metrics_start_time='+str(int(time.time()))]
start_urls = ['http://apimeishi.meituan.com/meishi/filter/v7/deal/select?offset='+str(x)+'&ci=10&mypos=31.35548627129277%2C121.76778813515155&metrics_start_time=str(int(time.time()))' for x in range(0,25*10,25)]
def parse(self, response):
# 将返回来的商家列表字符串转换成列表的形式
for names in response.body.decode()[0:-1].split(","):
# 将商家的名字更新进字典
self.store_name.update({names[2:-1].split(' ')[1]:names[2:-1].split(' ')[0]})
self.store_id.update({names[2:-1].split(' ')[1]:names[2:-1].split(' ')[1]})
# 构造商家信息的url url='http://apimeishi.meituan.com/meishi/poi/v2/poi/base/'+names[2:-1].split(' ')[1]+'?uuid=0000000000000A80359FC7F904ABE9B210AEBE93CA6B2A153437614502539080&utm_medium=android&version_name=10.0.801'
yield scrapy.Request(url=url, callback=self.store_information)
def store_information(self,response):
# 将返回来的商家信息字符串转换成列表的形式
self.num +=1
print(self.num)
url_id = re.findall(r'http://apimeishi.meituan.com/meishi/poi/v2/poi/base/(.*?).uuid=0000000000000A80359FC7F904ABE9B210AEBE93CA6B2A153437614502539080&utm_medium=android&version_name=10.0.801',response.url)[0]
url = 'http://apimeishi.meituan.com/meishi/poi/v2/poi/comment/list/'+ url_id
# 将商家地址和电话更新进字典
self.store_addr.update({url_id:response.body.decode().split(' ')[0]})
self.store_phone.update({url_id:response.body.decode().split(' ')[1]})
yield scrapy.Request(url=url, callback=self.store_asscss)
def store_asscss(self,response):
url_id = re.findall(r'http://apimeishi.meituan.com/meishi/poi/v2/poi/comment/list/(.*)',response.url)[0]
#使用item封装数据
self.store_comment.update({url_id:response.body.decode()})
self.information['store_name'] = self.store_name[url_id]
del self.store_name[url_id]
self.information['store_addr'] = self.store_addr[url_id]
del self.store_addr[url_id]
self.information['store_id'] = self.store_id[url_id]
del self.store_id[url_id]
self.information['store_phone'] = self.store_phone[url_id]
del self.store_phone[url_id]
self.information['store_comment'] = self.store_comment[url_id]
self.store_comment.clear()
yield self.information
app返回的都是json格式的代码,所以我直接在中间件里用resquests库请求并转换成字典格式方便处理下面的是中间件的代码
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
if "http://apimeishi.meituan.com/meishi/filter/v7/deal/select?"in request.url:
response = requests.get(url=request.url)
# 返回的response 是JSON的格式 获取到商家列表
names_dict = response.json()['data']['poiList']['poiInfos']
names = []
for li in names_dict:
#从JSON中取出店铺名称 和ID 组成一个列表
information = li['name']+' '+li['poiid']
names.append(information)
name_str = str(names)
name = HtmlResponse(url=request.url, body=name_str, encoding='utf-8', request=request)
return name
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
if "http://apimeishi.meituan.com/meishi/poi/v2/poi/base/"in request.url:
response = requests.get(url=request.url)
# 返回的response 是JSON的格式 获取到商家列表
information_dict = response.json()
informations = information_dict['data']['addr']+' '+information_dict['data']['phone']
information = HtmlResponse(url=request.url, body=informations, encoding='utf-8', request=request)
return information
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
if "comment/list"in request.url:
response = requests.get(url=request.url)
# 返回的response 是JSON的格式 获取到商家的评论
comment_dict = response.json()['data']["comments"]
for comment in comment_dict:
comments = comment["user"]["userName"]+'评论说: '+comment["reviewBody"]+' '
information = HtmlResponse(url=request.url, body=comments, encoding='utf-8', request=request)
return information
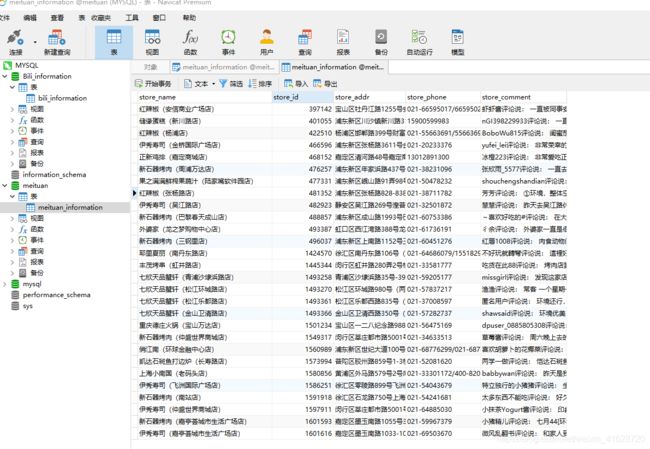
接下来就是处理数据了,项目要求是使用excel打包,这里我就直接入库了
下面使用管道清洗入库的代码
from . import items
import pymysql
from twisted.enterprise import adbapi
from scrapy.exceptions import DropItem
class MeituanPipeline(object):
def __init__(self):
self.meituan_set = set()
def process_item(self,item,spider):
if isinstance(item, items.MeituanItem):
if item['store_id'] in self.meituan_set: # 清洗数据,将重复的数据删除
raise DropItem("Duplicatebookfound:%s" % item)
else:
self.meituan_set.add(item['store_id'])
return item
# 一般数据库存储
# 此处代码最容易报错请确保数据库表 中开头么有空格其他注意细节
class MySQL_Meituan_Pipeline(object):
def __init__(self):
self.conn = pymysql.connect(host="127.0.0.1", user="admin", password="Root110qwe", db="meituan", charset='utf8mb4',port=3306)
self.cursor = self.conn.cursor()
print('连接数据库成功 啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啦啊啦')
def process_item(self, item, spider):
insert_sql = '''insert into meituan_information(store_id,store_name,store_addr,store_phone,store_comment)values(%s,%s,%s,%s,%s)'''
self.cursor.execute(insert_sql, (
item['store_id'], item['store_name'], item['store_addr'], item['store_phone'], item['store_comment']
))
print('写入数据库成功 哈哈哈哈哈哈哈哈哈哈哈哈哈哈啊哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈')
self.conn.commit()
def close_spider(self, spider): # TypeError: close_spider() takes 1 positional argument but 2 were given
self.cursor.close()
self.conn.close()
##一定不要忘了settings的配置
爬取的结果展示