JUC之线程池
线程池详解
- 常见问题
- Executor基本框架
- 源码分析线程池
- 线程池的生命周期
- 典型Execute方法源码分析
- 线程池的实践
- 常见错误
- 线程池的大小选择策略
常见问题
Java并发类库提供的线程池有哪几种,分别有什么特点?
通常我们都是利用Executors提供的通用线程方法,去创建不同配置的线程池,主要区别在与不同的ExecutorsService类型或是不同的初始参数。
Execuotors提供了5种不同的线程池创建配置:
- newCacheThreadPool(): 它是一种用来处理大量短时间工作任务的线程池。特点:它会缓存线程并重用,当没有缓存线程可用时,就会创建新的工作线程;如果线程闲置时间超过60秒,则会被终止并移出缓存;长时间闲置这种线程池不会消耗什么资源;其内部使用SynchronousQueue作为工作队列。
- newFixedThreadPool(int nThreads): 重用指定数目的线程,背后使用的是无界的工作队列,任何时候最多有NThreads个工作线程是活动的。这意味着,如果超过了活动队列数目,将在工作队列中等待空闲线程出现;如果有工作线退出,将会有新的工作线程被创建,以弥补指定的数目NThreads。
- newSingleThreadExecutor(): 其特点在于工作线程数目被限制为1,操作一个无界的工作队列,所以他保证了所有任务都是被顺序执行,最多会有一个任务处于活跃状态,并且不允许使用者改动线程池实例,因此可以避免其改变线程数目。
- newSingleThreadScheduledExecutor() 和 newScheduledThreadPool(int corePoolSize): 创建的是个ScheduledExecutorService,可以进行定时或定周期的工作调度,区别在于单一工作线程还是多个工作线程。
- newWorkStealingPool(int parallelism): 是一个经常被人忽略的线程池,Java8新增这个创建方法,其内部会构建ForkJoinPool,利用work-stealing(n. 脏物)算法,并行的处理任务,不保证处理顺序。
关于线程池要达到的程度:
- 掌握Executor框架主要内容,至少了解组成与职责,掌握基本开发用例中的使用。
- 对线程池和相关并发工具的理解,甚至源码层面的掌握。
- 实践中有哪些常见问题,基本的诊断思路是怎样的。
- 如何根据自身应用特点合理使用线程池。
Executor基本框架
Executor基本框架组成,参考下面的类图。
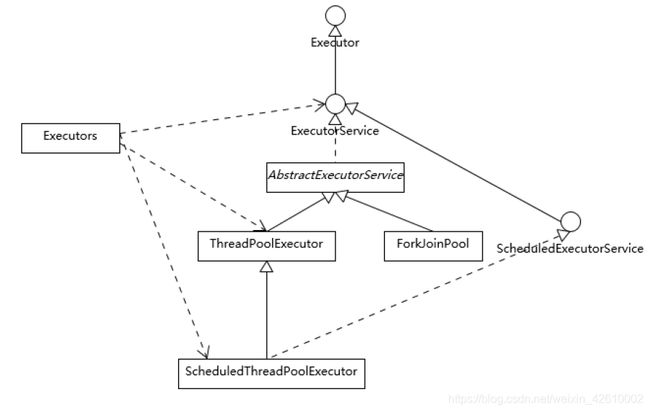
从整理上看各个类型的主要设计目的:
- Executor是一个基础的接口,设计初衷是将任务提交和任务执行解耦,这一点可以从其唯一方法中看出。Executor的设计源于Java早期线程API使用的教训,开发者在实现应用逻辑时,被太多的线程创建、调度等不相关的细节所打扰。就像我们自己进行HTTP通信,还需要关注三次握手一样麻烦,开发效率低下,质量也难以保证。
void Executor(Runnable command);
- ExecutorService则更加完善,不仅提供了Service的管理功能,比如shutDown等方法,也提供了更加全面的提交任务机制,如返回Future而不是void的Submit方法。注意: 这个例子输入的是Callable,它解决了Runnable无法返回结果的困扰。
<T> Future<T> submit(Callable<T> task);
- Java标准类库提供了几种基础实现。比如ThreadPoolExecutor、ScheduledThreadPoolExecutor、ForkJoinPool。这些线程池的设计特点在于其高度的可调节性和灵活性,以满足复杂多变的实际应用场景。
- Executors则从简化使用的角度,为我们提供了各种方便的静态工厂方法。
源码分析线程池
主要围绕ThreadPoolExecutor源码,ScheduleThreadPoolExecutor是ThreadPoolExecutor的扩展,主要增加了调度逻辑,而ForkJoinPool 是针对ForkJoinTask的定制线程池,与通常意义的线程池不太相同。
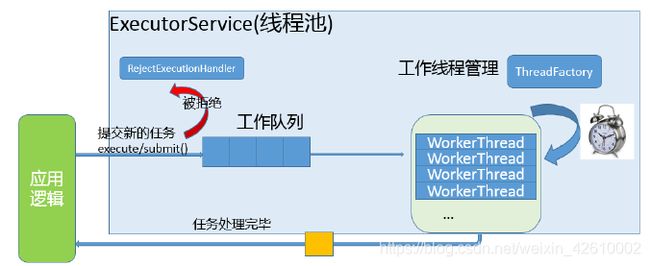
简单理解:
- 工作队列 负责存储用户提交的各个任务,这个工作队列可以是容量为0的SynchronousQueue(使用newCacheThreadPool),也可以像固定大小线程池(newFixedThreadPool)那样使用LinkedBlockingQueue。
private final BlockingQueue<Runnable> workQueue;
- 内部的“线程池”,这是指保持工作线程的集合,线程池需要在运行过程中管理线程创建和销毁。例如,对带缓存的线程池,当任务压力较大时,线程池会创建新的工作线程;当业务压力退去,线程池会在闲置一段时间后(60秒)结束线程。
private final HashSet<Worker> workers = new HashSet<>();
线程池的工作线程被抽象为静态内部类Worker,基于AQS实现
- ThreadFactory 提供上面所需要的的线程逻辑。
- 如果任务提交时被拒绝,比如线程已经处于ShutDown状态,需要为其提供处理逻辑,Java标准库提供了类似ThreadPoolExecutor.AboutPolicy等默认实现,也可以按照实际需求自定义。
从上面分析就可以看出线程池的几个基本组成部分。构造函数的属性,从字面就可以大概猜出用意:
- corePoolSize ,核心线程数,可以大致理解为长期驻留的线程数目(除非设置了allowCoreThreadTimeOut),对于不同的线程池,这个值可能会有很大的区别,比如newFixedThreadPool会将其设置成nThreads,而对于newCacheThreadPool则是0。
- maximumPoolSize,线程不够是可以创建的最大线程数。同样对比newFixedThreadPool,当然就是nThreads,因为其要求是固定大小,而newCacheThreadPool则是Integer.MAX_VALUE。
- keepAliveTime和TimeUnit,这两个参数指定额外的线程能够闲置多久,显然有些线程池不需要它。
- workerQueue 工作队列,必须是BlockingQueue。
通过配置不同的参数我们就能创建出大相径庭的线程池,这就是线程池高度灵活的基础。
public ThreadPoolExecutor(int coreThreadPoolsize,
int maximumPoolSize,
long KeepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workerQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
线程池的生命周期
既然线程池有生命周期,那么他的状态是如何表征的呢?
这里有一个非常有意思的设计: ctl。ctl变量被赋予了双重角色,通过 高低位的不同,即在高位表示线程池状态,又在地位表示工作线程数目,这是一个典型的高效优化。试想实际系统中,虽然我们可以指定线程极限为Integer.Max_VALUE,但是因为资源限制,这只是个理论值,所以完全可以将空闲的高位赋予其他意义。
private fnal AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 真正决定了工作线程数的理论上限
private satic fnal int COUNT_BITS = Integer.SIZE - 3;
private satic fnal int COUNT_MASK = (1 << COUNT_BITS) - 1;
// 线程池状态,存储在数字的高位
private satic fnal int RUNNING = -1 << COUNT_BITS;
…
// Packing and unpacking ctl
private satic int runStateOf(int c) { return c & ~COUNT_MASK; }
private satic int workerCountOf(int c) { return c & COUNT_MASK; }
private satic int ctlOf(int rs, int wc) { return rs | wc; }
这里是一个简单的线程池状态流转图:
注意: Java实际代码中并不存在所谓的Idle状态,添加只是为了方便理解。

典型Execute方法源码分析
public void execute(Runnable commandnb) {
...
int c = ctl.get();
//检查工作线程数目,低于corePoolSize则添加Worker
if (workerCountOf(c) < corePoolSize) {
if (addWorker(commend, true)
return;
c = ctl.get();
}
//isRunnming就是检查线程池是否被ShutDown
//工作队列可能是有界的,offer是比较友好的入队方式
if (isRunning(c) && workQueue.offer(command)) {
int reCheck = ctl.get();
//再次进行防御性检查
if (isRunning(reCheck) && remove(command))
return command;
else if (workerCountOf(reCheck) == 0)
addWorker(null, false);
}
//尝试添加一个worker,如果失败,则认为已经饱和,或者被shutDown了
else if (!addWorker(command, false))
reject(command);
}
线程池的实践
常见错误
- 避免任务堆积。前面我们说过newFixedThreadPool是创建指定数目的线程,但是其工作队列是无界的,如果工作线程数太少,导致处理跟不上入队的速度,就很有可能占用大量系统内存,甚至出现OOM。诊断时,可以使用jmap之类的工具,查看是否有大量的任务入队。
- 避免过度扩展线程。我们通常在处理大量短时任务时,使用缓存的线程池,我们在创建线程池时并不能准备预估任务压力有多大,数据特征是什么样的(大部分请求是1k,100k还是1M)。所以很难明确设定一个线程数目。
- 另外,如果线程数目不断增长(可以使用jStack等工具检测),也需要警惕另外一种可能性,就是线程泄露,这种情况往往是因为线程逻辑有问题,导致工作线程迟迟不能被释放。建议排查线程栈,很有可能多个线程都是卡在近似的代码处。
- 避免死锁等同步问题。
- 尽量避免在使用线程时,操作ThreadLocal。因为工作线程的生命周期通常会超过任务的生命周期。
线程池的大小选择策略
前面已经介绍了,线程池大小不合适,太多或太少都会造成麻烦,所以需要考虑一个合适的线程池大小。
- 如果我们的任务主要是进行计算,那么我们的CPU就是稀缺资源。我们能够通过大量增加线程数目提高计算能力吗,往往是不能的,因为如果线程数太多,反倒导致大量的上下文切换开销。所以这种情况下,通常按照CPU核的数目N或者N+1。
- 如果是较多等待的任务,比如I/O操作比较多,可以参考并发大师Brain Goetz的计算方法:线程数 = CPU核数 × (1 + 平均等待时间/平均工作时间)。这些时间并不能精确预计,需要根据采样或者概要分析,等方法进行计算,然后在实际中验证和调整。
- 上面只考虑了CPU的限制,实际上还可能受各种系统资源限制影响,如果我们不能调整资源的容量,那么我们就只能限制工作线程的数目了。这里的资源可以是文件句柄或者内存等。