人工智能概述
人工智能
1 人工智能的概念
我们可以把任何的一个事物,它只要具备了一定的智能,我们可以把它归类成人工智能
人工智能是具备以下特征的一个系统:
- 像人类一样思考
- 像人类一样的行动
- 具备理性思考能力
- 具备理性的行动能力
人工智能分为两类:
限制领域人工智能(某一个特定场景下解决某一类特定的问题),比如:
- 电商推荐系统
- 金融评分卡
- 医疗智能问答
通用型人工智能(像人类一样,几乎可以做任何事情)
AI和BI的区别:
AI(Artificial Intelligence):通过数据帮助人做决策
BI(Business Intelligence):BI是一种分析的工具,也就是通过一些方式把数据更直观的展示给用户,辅助人去决策
所以从这个角度,可以把BI看作是辅助的决策的工具,AI则可以直接帮我们做决策。
2 机器学习的概念
机器学习是解决人工智能问题的最核心的技术。比如推荐系统,无人驾驶,人脸识别,竞技分析等应用都要依赖于机器学习技术。
机器学习的核心是,从数据中自动学出规律,而不是一个人拍脑袋定出来的。可以简单地理解为归纳总结。而且通过机器归纳出来的规律有可能很多是我们之前都没有想到的。
3 深度学习的概念
深度可以理解成我们把很多简单的模型叠加在了一起,这自然就能得到一个有深度的模型。举个例子,比如我们把一个神经网络叠加成多层结构的时候,得到的是深度神经网络; 当我们把一个高斯混合模型叠加在一起的时候就得到了深度高斯混合模型; 当我们把SVM叠加在一起的时候就得到了深度SVM模型。由此可见,这样的一个框架可以应用在很多不同种类的模型上.
这样的模型会有更强大的表达能力(capacity), 具备层次表示能力(hierarhical representation), 具有全局泛化能力(global generalization),迁移学习能力(transfer learning)等等。
人工智能>机器学习>深度学习
4 机器学习的应用场景
- 农业技术
- 教育(拍照识题、AI老师、语音评测)
- 医疗行业
- 零售行业(智能试衣间/在线服务机器人/无人超市)
- 金融行业(量化投资/个性化保险/金融风控)
- 汽车行业(无人驾驶)
- 广告(精准广告)
5 机器学习基础概念
机器学习分为两类:监督学习和无监督学习
除了监督学习和非监督学习还有一大类叫做强化学习,我们熟知的AlphaGo是强化学习最经典的代表作。
回归:输出是连续性数值,比如温度/身高/气温等
分类:输出是定性输出,比如阴或者晴,好或者坏
在机器学习训练中还有一个概念叫作训练数据和测试数据。训练数据用来训练模型,测试数据的作用是用来评估模型。
6 编写一个程序
机器学习建模环节:
数据收集→数据预处理→特征工程→建模→验证
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
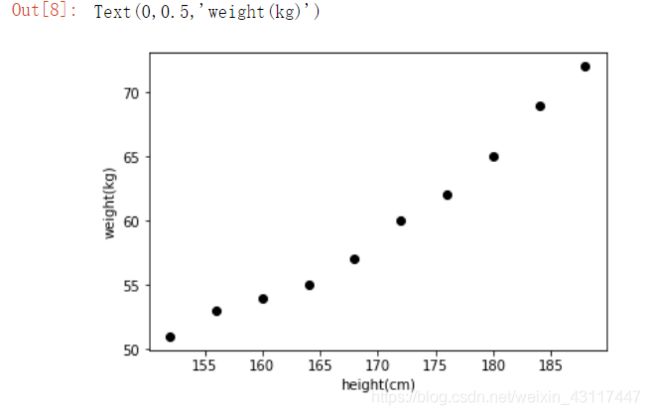
data = np.array([[152,51],[156,53],[160,54],[164,55],[168,57],[172,60],[176,62],[180,65],[184,69],[188,72]])
array([[152, 51],
[156, 53],
[160, 54],
[164, 55],
[168, 57],
[172, 60],
[176, 62],
[180, 65],
[184, 69],
[188, 72]])
x,y = data[:,0].reshape(-1,1),data[:,1]
data[:,0]中添加了一个reshape的函数,主要的原因是在之后调用fit函数的时候对特征矩阵x是要求是矩阵的形式。
plt.scatter(x,y,color="black")
plt.xlabel("height(cm)")
plt.ylabel("weight(kg)")
from sklearn import linear_model
# 实例化一个线性回归的模型
regr = linear_model.LinearRegression()
# 在x,y 上训练一个线性回归模型,如果训练顺利,则regr会存储训练完成之后的结果
regr.fit(x,y)
# 画出身高与体重的关系
plt.scatter(x,y,color="red")
# 画出已训练好的线条
plt.plot(x,regr.predict(x),color="blue")
plt.xlabel("height(cm)")
plt.ylabel("weight(kg)")

# 利用已经训练好的模型去预测身高为163的人的体重
print ("Standard weight for person with 163 is %.2f"% regr.predict([[163]]))
Standard weight for person with 163 is 55.77