使用Python处理图片验证码
在工作中,后端开发人员数据处理是常见的内容,偶尔也会从其他网站获取部分信息。我们获取信息的网站可以分为两大类,一类是资讯网站,比如各大门户网站,另一类是行业网站。资讯网站大多数是没有鉴权的,行业网站一般是有鉴权,鉴权分为多种方式,有短信验证码、账号密码等,这些方式经常是配合图片验证码来使用,因为图片验证码可以防止恶意破解密码、恶意登录等。以某网站为例,我们想要用程序的方式获取数据,必须通过该网站的鉴权。该网站也是用常规的账号+密码+图片验证码的方式组成鉴权。接下来梳理下怎么用Python获取、处理和识别图片验证码,使程序可以自动通过鉴权。
- 获取验证码
首先我们需要从该网站获取一定数量的验证码例如3000个,观察规律。
1. #encoding: utf-8
2. import os, time
3. from urllib import request
4.
5. def getPic():
6. # 单一窗口获取图片的链接
7. img_url = "https://**********/cas/plat_cas_verifycode_gen"
8. # 本地保存的目录
9. file_path = 'E:/article/auth/pic/primitive/'
10.
11. try:
12. if not os.path.exists(file_path):
13. os.makedirs(file_path)
14. for num in range(0,3000):
15. file_name = str(num)+".jpg"
16. request.urlretrieve(img_url,file_path+file_name)
17. print(str(num)+" success")
18. # 休眠 100ms
19. time.sleep(0.1)
20. except Exception as e:
21. print("error")
22. print(e)
python是一种跨平台的计算机程序设计语言,是一种面向对象的动态类型语言。语法比较通俗易懂,拥有非常丰富的第三方库,代码显得非常的简洁。上述代码可以在本地保存3000张JPG格式的验证码。
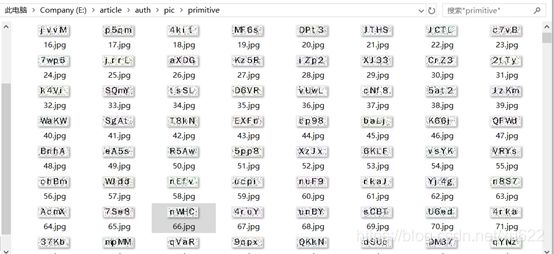
从上述图中可以看出验证码是带有很多噪点的,随机选择一张用Windows自带的画图工具放大800%查看如下图所示。
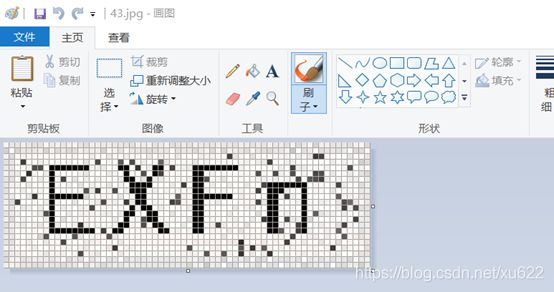
从放大的图片可以看出噪点的颜色深度没有验证码值的深,通过比较像素点的RGB值将浅色的像素点改成白色,可以去除大部分的噪点。
2. 验证码降噪
2.1 二值化处理
图片需要先转成灰度图,再转成二值图片(非黑即白)。经过多次试验灰度阈值设为30到40之间最为合适,大多数的噪点已经被渲染成白色,代码如下
1. from PIL import Image
2. import os
3.
4.
5. # 二值化处理 灰度阈值设为35,高于这个值的点全部填白色
6. def two_value(threshold=35):
7. for i in range(0, 3000):
8. # 打开文件夹中的图片
9. im-age = Image.open('E:/article/auth/pic/primitive/' + str(i) + '.jpg')
10. # 灰度图 模式“L” 每个像素用8个bit表示,0表示黑,255表示白
11. # 公式 L = R * 299/1000 + G * 587/1000+ B * 114/1000
12. lim = image.convert('L')
13. table = []
14.
15. for j in range(256):
16. if j < threshold:
17. # 填黑色
18. table.append(0)
19. else:
20. # 填白色
21. table.append(1)
22. # 对图像像素操作 模式“1” 为二值图像,非黑即白。但是它每个像素用8个bit表示,0表示黑,255表示白
23. bim = lim.point(table, '1')
24. path = 'E:/article/auth/pic/first/'
25. isExists = os.path.exists(path)
26. if not isExists:
27. os.makedirs(path)
28. # 保存图片
29. bim.save(path + str(i) + '.jpg')
下图左侧是原图,右侧是已经处理过的图片,通过对比可以看出大部分的噪点已经被处理,仍有少量的噪点存在。
2.2 去除单独的黑色噪点
经过上述二值化操作,大部分的图片已经没有噪点,仍有部分图片有一些单独的噪点,比如下图。
去除单独噪点,原理是一个单独的点,它的上下左右各方也没有点存在。代码如下
1. # 去除单独的黑色像素点
2. def descrambler(name, threshold=35):
3. # 打开图片
4. im = Image.open('E:/article/auth/pic/first/' + name)
5. # 获取图像数据
6. data = im.getdata()
7. w, h = im.size
8. black_point = 0
9. # black_rgb = 10
10. black_rgb = threshold
11.
12. for x in range(1, w - 1):
13. for y in range(1, h - 1):
14. mid_pixel = data[w * y + x] # 中央像素点像素值 255为白色
15. if mid_pixel <= threshold: # 找出上下左右四个方向像素点像素值
16. # 上、左、下、右边像素点
17. top_pixel = data[w * (y - 1) + x]
18. left_pixel = data[w * y + (x - 1)]
19. down_pixel = data[w * (y + 1) + x]
20. right_pixel = data[w * y + (x + 1)]
21.
22. # 判断上下左右的黑色像素点总个数
23. if top_pixel < black_rgb:
24. black_point += 1
25. if left_pixel < black_rgb:
26. black_point += 1
27. if down_pixel < black_rgb:
28. black_point += 1
29. if right_pixel < black_rgb:
30. black_point += 1
31. # 孤立的点周围没有黑点
32. if black_point < 1:
33. # 将黑点置为白色
34. im.putpixel((x, y), 255)
35. black_point = 0
36. path = 'E:/article/auth/pic/second/'
37. isExists = os.path.exists(path)
38. if not isExists:
39. os.makedirs(path)
40. im.save(path + name)
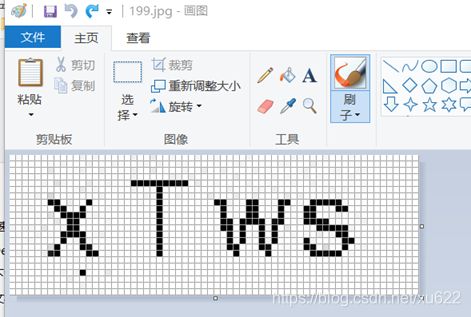
下图左边为去除单独噪点前的验证码,右边为去除后的。右边除了X下方的黑点被去除,X本身也被误删除了一个点,但是这已经不影响用tess4j或者OCR网站判断了。
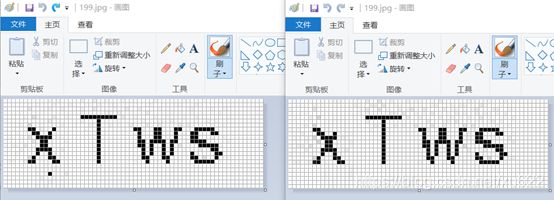
3. 识别
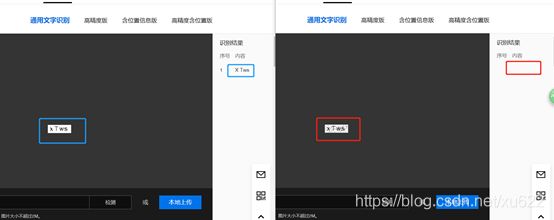
打开https://ai.baidu.com/tech/ocr/general 百度OCR测试地址,选择“本地上传”提交上述验证码,检测结果为“X Tws”,检测成功。
4. 总结
图片验证码的种类非常多,有带干扰点、干扰线及内容倾斜等等,但它是按一种或者一组规律生成的,最终目的是让人能够看得清,程序不容易识别。我们可以通过细心的观察和试验,发现其规律并破解,达到我们的目的。